Comment Appliquer le Masquage Statique dans Percona Server
Le masquage statique dans Percona Server pour MySQL est une approche pratique pour protéger les informations sensibles avant que les données ne quittent les environnements de production. Percona Server est largement utilisé pour les charges transactionnelles, les pipelines analytiques et les applications orientées client, qui stockent souvent des données réglementées telles que des identifiants personnels, des coordonnées et des attributs financiers. Dans ce contexte, le masquage statique agit comme un contrôle fondamental au sein de stratégies plus larges de sécurité des données.
Une fois que les jeux de données de production sont copiés dans des environnements de développement, de test, d’analyse ou de support, les contrôles d’accès traditionnels perdent leur efficacité. À ce stade, la transformation permanente des données devient le moyen le plus fiable de prévenir toute exposition tout en préservant l’intégrité du schéma et la cohérence relationnelle. Cette approche soutient directement les pratiques modernes de sécurité des bases de données, où la protection doit persister même en dehors des limites de production. Percona Server pour MySQL est lui-même couramment choisi dans ces scénarios en raison de ses performances et de ses fonctionnalités pour entreprise, comme décrit dans la documentation officielle de Percona Server.
Cet article explique comment le masquage statique peut être appliqué dans Percona Server pour MySQL en utilisant des techniques SQL natives, et comment des plateformes centralisées telles que DataSunrise étendent ces capacités avec des flux de travail de masquage pilotés par des politiques, reproductibles et alignés avec les exigences modernes de conformité des données.
Quand le Masquage Statique est Nécessaire dans Percona Server pour MySQL
Les environnements Percona servent souvent plusieurs objectifs opérationnels en même temps. Une seule instance de base de données peut supporter le débogage d’application, l’assurance qualité et les tests de régression, l’analyse commerciale, l’expérimentation en data science et les enquêtes de support de routine. Bien que ces activités reposent sur des schémas réalistes et des relations de données, elles ne nécessitent pas l’accès aux valeurs personnelles ou financières réelles. En pratique, le masquage statique devient un contrôle clé dans des stratégies plus larges de sécurité des données visant à réduire les expositions inutiles.
Lorsque les données de production sont réutilisées en dehors de leur environnement d’origine, conserver les valeurs originales introduit des risques significatifs. Même lorsque les permissions basées sur les rôles sont appliquées, les jeux de données copiés sont souvent consultés par un éventail plus large d’utilisateurs et stockés dans des systèmes moins contrôlés. À ce stade, les contrôles d’accès traditionnels seuls ne suffisent plus, c’est pourquoi le masquage statique est généralement appliqué dans le cadre de pratiques complètes de sécurité des bases de données.
Le masquage statique devient obligatoire lorsque les données de production sont répliquées dans des environnements non productifs, partagées avec des fournisseurs ou sous-traitants tiers, ou utilisées pour des charges de travail de test et d’analyse sans besoin business clair pour les valeurs réelles. De plus, les cadres réglementaires tels que le RGPD, HIPAA et PCI DSS exigent explicitement de minimiser l’utilisation de données sensibles réelles hors des systèmes de production, alignant ainsi le masquage statique avec les principes établis de conformité des données.
Contrairement au masquage dynamique, le masquage statique remplace de manière permanente les valeurs sensibles dans le jeu de données. Cette transformation irréversible garantit que même si les contrôles d’accès échouent ou si les données sont copiées à nouveau, les informations originales ne peuvent pas être récupérées. Par conséquent, le masquage statique complète d’autres mécanismes de protection, y compris le masquage dynamique des données, en éliminant les risques d’exposition au niveau même des données.
Techniques Natives de Masquage Statique dans Percona Server pour MySQL
Percona Server pour MySQL n’inclut pas de moteur natif de masquage statique. Par conséquent, le masquage statique est généralement mis en œuvre via des transformations SQL explicites exécutées sur les jeux de données copiés dans des environnements non productifs. Ces opérations modifient les données de manière permanente et sont typiquement réalisées immédiatement après la réplication ou l’exportation.
Masquage Statique au Niveau des Colonnes avec des Instructions UPDATE
La technique de masquage statique la plus commune consiste à écraser les colonnes sensibles avec des valeurs déterministes ou partiellement obfusquées. Cette méthode préserve la structure du schéma et les types de données tout en supprimant le contenu réel.
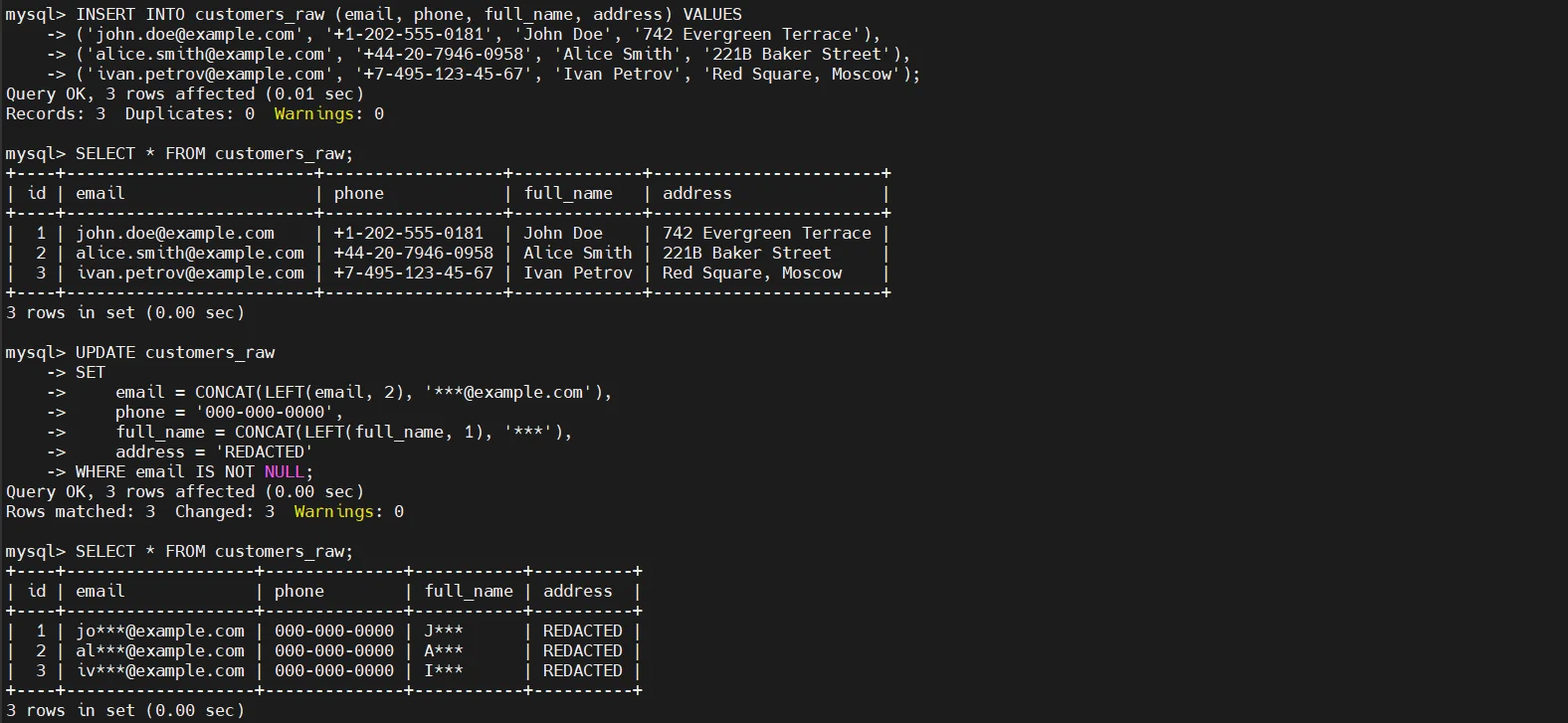
Cette méthode est simple et efficace, mais elle modifie de manière permanente le jeu de données. Une fois exécutée, les valeurs originales ne peuvent pas être restaurées, ce qui rend cette approche adaptée uniquement aux copies non productives.
Masquage Basé sur le Hachage pour les Identifiants
Lorsque l’unicité et l’intégrité référentielle doivent être préservées, le hachage fournit une technique de masquage statique fiable. Les valeurs hachées restent cohérentes entre les tables, permettant aux jointures et comparaisons de continuer à fonctionner.
UPDATE users
SET
national_id = SHA2(national_id, 256),
passport_number = SHA2(passport_number, 256)
WHERE national_id IS NOT NULL;
Comme le hachage est unidirectionnel, les identifiants originaux ne peuvent pas être reconstruits, tandis que la logique relationnelle reste intacte à travers les tables dépendantes.
Masquage Aléatoire pour les Champs Numériques et de Date
Pour les montants financiers, les métriques ou les horodatages, la randomisation dans des plages contrôlées aide à maintenir des distributions de données réalistes sans exposer les vraies valeurs.
UPDATE payments
SET
amount = FLOOR(RAND() * 1000) + 10,
tax_amount = FLOOR(RAND() * 200),
payment_date = DATE_SUB(
CURDATE(),
INTERVAL FLOOR(RAND() * 365) DAY
),
settlement_date = DATE_ADD(
payment_date,
INTERVAL FLOOR(RAND() * 5) DAY
);
Cette approche est couramment utilisée dans les environnements de test et d’analyse, où les tendances et distributions comptent, mais pas les données transactionnelles réelles.
Considérations Pratiques
Bien que le masquage statique basé sur SQL natif offre de la flexibilité, il nécessite une coordination rigoureuse. Les dépendances entre tables doivent être gérées manuellement, la logique de masquage doit être maintenue cohérente entre les environnements et les erreurs d’exécution peuvent facilement entraîner des jeux de données incomplets ou corrompus. À mesure que le périmètre de masquage s’étend, ces scripts deviennent plus difficiles à maintenir et à gouverner.
Masquage Statique Centralisé pour Percona Server pour MySQL avec DataSunrise
DataSunrise introduit une couche de sécurité externe pilotée par des politiques qui automatise le masquage statique sans intégrer la logique de transformation dans les scripts SQL ou les objets de base de données. Au lieu de maintenir des instructions UPDATE personnalisées ou des procédures stockées, les règles de masquage sont définies de manière centralisée et exécutées de façon cohérente à travers les environnements. Cela garantit que la même logique de transformation est appliquée chaque fois que les données de production sont préparées pour un usage non productif.
En externalisant la logique de masquage, cette approche aligne le masquage statique avec des stratégies plus larges de sécurité des données et de sécurité des bases de données, où la protection est appliquée indépendamment du code applicatif et de la conception du schéma de base de données.
Découverte et Classification des Données Sensibles
Avant toute opération de masquage, DataSunrise analyse automatiquement les schémas Percona Server pour MySQL afin d’identifier les données sensibles. Le processus de découverte détecte les informations personnelles identifiables, les attributs financiers, les identifiants et autres données réglementées basées sur des motifs de contenu réels plutôt que sur les seuls noms de colonnes ou métadonnées. Cette capacité s’appuie sur des techniques modernes de découverte des données qui se concentrent sur le contenu réel des données plutôt que sur les hypothèses liées au schéma.
Parce que la découverte repose sur l’analyse du contenu, elle reste efficace même dans des schémas mal documentés ou nommés de manière incohérente. En conséquence, les champs sensibles sont identifiés de manière fiable avant l’application des règles de masquage, réduisant le risque d’exposition accidentelle et renforçant l’ensemble des contrôles de sécurité des données.
- Identification automatique des informations personnelles (PII), des données financières et des identifiants basée sur le contenu des données, alignée avec les pratiques de protection des PII
- Indépendance par rapport aux conventions de nommage des colonnes ou à la qualité de la documentation des schémas
- Découverte continue à mesure que les schémas évoluent dans le temps
- Réduction du risque de manquer des champs sensibles avant masquage
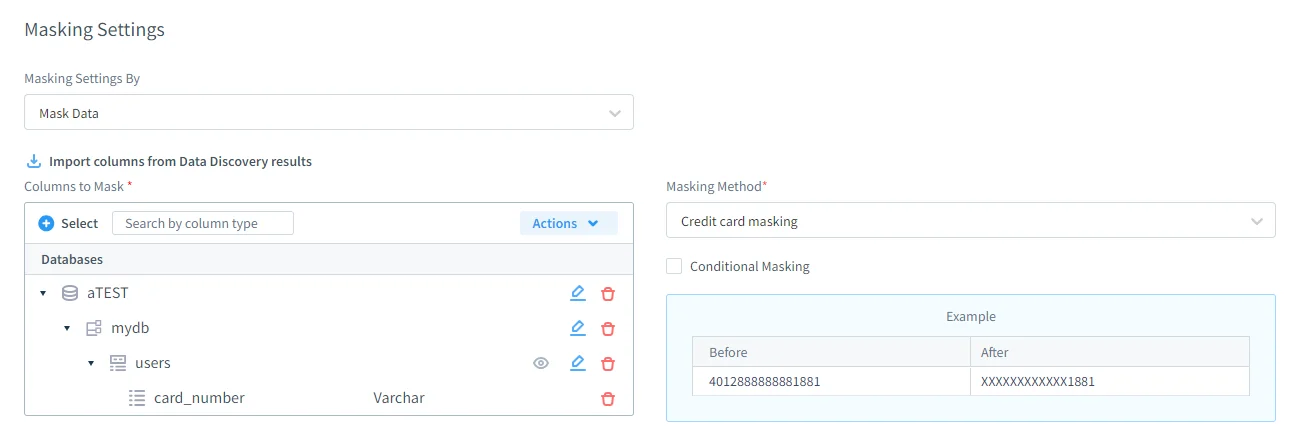
Définir les Règles de Masquage Statique
Les règles de masquage statique dans DataSunrise offrent un contrôle granulaire sur la manière dont les données sont transformées. Les administrateurs peuvent définir précisément quelles bases de données, schémas, tables et colonnes sont soumises au masquage, ainsi que la méthode de masquage appliquée à chaque champ. Les techniques supportées incluent la substitution, le hachage, la randomisation et la nullification, conformément aux principes établis du masquage statique des données.
Il est important de noter que les règles de masquage peuvent préserver l’intégrité référentielle entre tables liées, assurant que les relations de clés étrangères restent valides après transformation. Les règles sont réutilisables et versionnées, ce qui élimine le besoin de scripts SQL ponctuels et aide à maintenir la cohérence entre plusieurs environnements tout en soutenant des politiques centralisées de sécurité des bases de données.
- Définition centralisée des règles à travers bases de données et schémas
- Support de multiples techniques de masquage par type de données
- Préservation de l’intégrité référentielle entre tables liées
- Règles versionnées et réutilisables entre environnements
Exécution des Jobs de Masquage Statique
Une fois les règles de masquage configurées, l’exécution devient un processus opérationnel contrôlé plutôt qu’une tâche manuelle. Les jobs de masquage statique peuvent être lancés à la demande, planifiés pour s’exécuter automatiquement, ou intégrés dans des pipelines CI/CD et de provisionnement de données. Ce modèle opérationnel s’aligne avec les pratiques plus larges de gestion des données de test utilisées dans les workflows DevOps modernes.
En conséquence, les environnements non productifs reçoivent des jeux de données masqués de façon cohérente sans dépendre d’exécutions SQL manuelles ou de scripts ad hoc, réduisant les risques opérationnels et les erreurs humaines tout en améliorant l’efficience de la gestion des données.
- Exécution à la demande pour la préparation ad hoc de jeux de données
- Masquage planifié pour les cycles de rafraîchissement récurrents
- Intégration aux workflows CI/CD et de provisionnement de données
- Élimination des étapes manuelles de masquage basées sur SQL
Auditabilité et Alignement sur la Conformité
Chaque opération de masquage statique réalisée par DataSunrise est enregistrée et traçable. Ces enregistrements créent un historique clair des moments où le masquage a été exécuté, quelles règles ont été appliquées et quels actifs de données ont été affectés. Ce niveau de visibilité soutient directement les programmes structurés de conformité des données.
En transformant le masquage statique en un processus documenté et reproductible, les organisations s’éloignent des manipulations ad hoc des données et évoluent vers un workflow de conformité gouverné, capable de résister aux contrôles internes et audits externes, complétant ainsi les initiatives centralisées de gestion de la conformité.
- Traçabilité complète des opérations de masquage et de l’utilisation des règles
- Alignement avec les exigences du RGPD, HIPAA, PCI DSS et SOX
- Enregistrements prêts à être produits lors des audits et revues de conformité
- Transition du masquage ad hoc vers des processus de conformité gouvernés
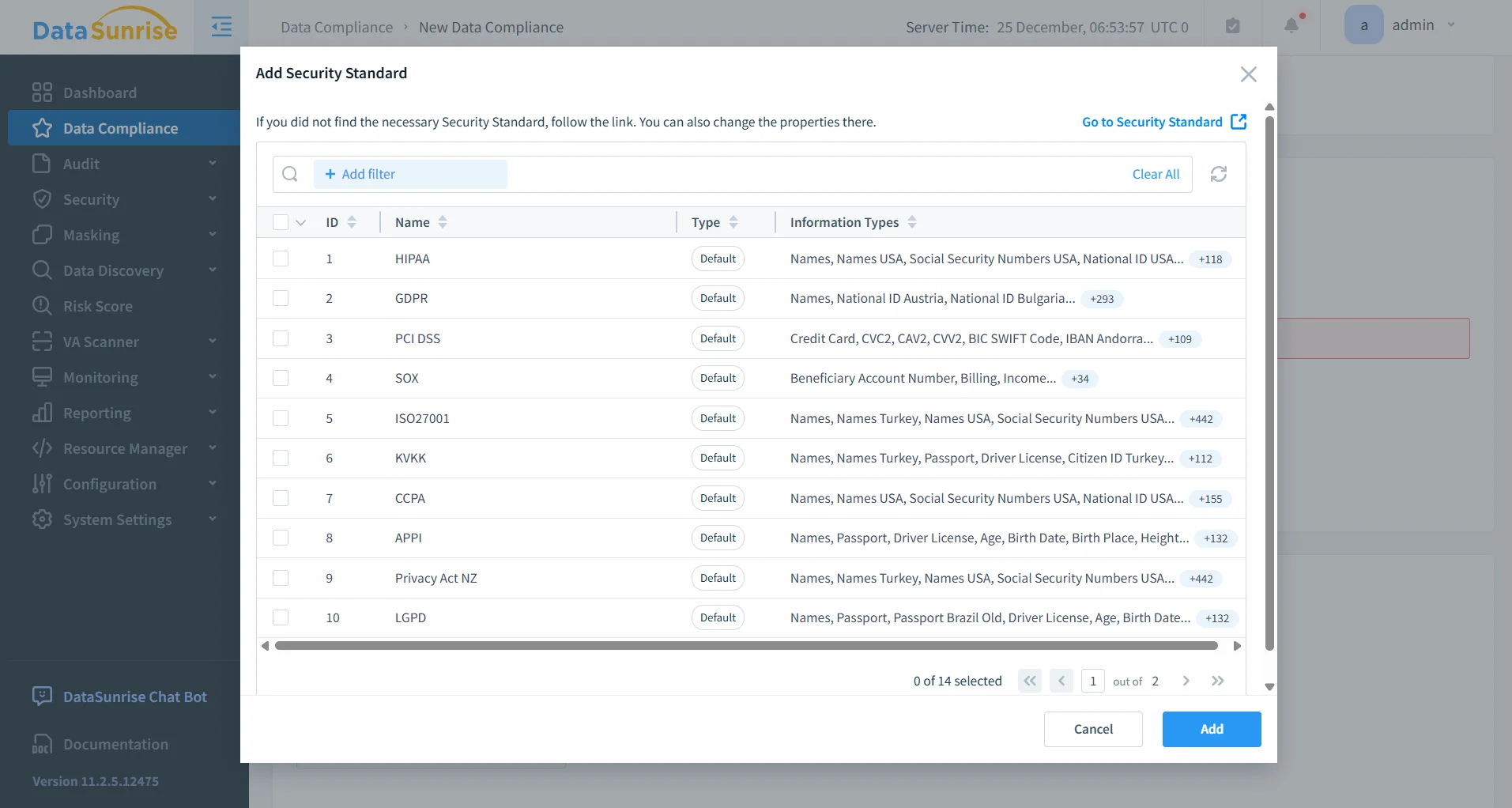
Impact Business du Masquage Statique dans Percona Server pour MySQL
| Domaine Business | Impact Opérationnel |
|---|---|
| Risque d’exposition des données | Réduction de la probabilité de fuite de données sensibles en dehors des environnements de production |
| Provisionnement des données de test | Création plus rapide de jeux de données conformes pour le développement, l’assurance qualité et l’analyse |
| Préparation à l’audit | Effort réduit pour préparer les éléments de preuve pour les audits de sécurité et de conformité |
| Consistance opérationnelle | Règles de masquage uniformes appliquées à travers les équipes et les environnements |
| Confiance dans le partage des données | Collaboration plus sûre avec les équipes internes et partenaires externes |
Le masquage statique déplace l’attention de la restriction d’accès vers la réutilisation sécurisée et contrôlée des données, rendant les workflows non productifs à la fois plus sûrs et plus efficaces.
Conclusion
Percona Server pour MySQL offre la flexibilité nécessaire pour implémenter le masquage statique en utilisant des techniques SQL natives. Ces approches conviennent à des scénarios petits et contrôlés où l’application manuelle est acceptable et où les exigences basiques de masquage statique des données peuvent être satisfaites avec des scripts personnalisés.
Cependant, les organisations ayant besoin d’une gouvernance à l’échelle, de cohérence entre environnements et de workflows de masquage prêts pour l’audit bénéficient de plateformes centralisées telles que DataSunrise. En formalisant le masquage statique dans des politiques structurées plutôt que dans des scripts fragiles, la protection des données sensibles devient prévisible, reproductible et conforme par conception, renforçant ainsi la posture globale de sécurité des données.
Le masquage statique cesse d’être un contournement — et devient un contrôle opérationnel.
