Comment Appliquer la Gouvernance des Données pour Vertica
Alors que les plateformes analytiques modernes continuent de croître en taille et en complexité, les organisations sont de plus en plus confrontées à des défis liés à la visibilité, au contrôle et à la conformité réglementaire. Parce que Vertica est conçue pour des charges de travail analytiques haute performance, la question de comment appliquer la gouvernance des données pour Vertica devient particulièrement importante. Son architecture permet une ingestion massive parallèle et une exécution de requêtes parallèle. Cependant, cette même force introduit des exigences uniques en matière de gouvernance que les équipes doivent gérer à la fois au niveau du plan de données et du plan de contrôle.
Dans les environnements Vertica, la gouvernance des données n’est pas simplement une liste de contrôle politique ; c’est un cadre technique qui définit comment les données sont classifiées, accessibles, masquées, surveillées et vérifiées. Puisque Vertica stocke des ensembles de données variés — des indicateurs financiers et de la télémétrie opérationnelle aux identifiants liés aux clients — les couches de gouvernance doivent garantir que les données sensibles se comportent conformément aux obligations réglementaires telles que le RGPD, HIPAA, PCI DSS et SOX. Par conséquent, comprendre comment appliquer la gouvernance des données pour Vertica nécessite d’examiner comment Vertica structure, traite et expose les données en interne. De plus, des outils externes de gouvernance comme DataSunrise appliquent la classification, le masquage, l’audit et les contrôles de sécurité à travers des chemins de requêtes distribués. Pour un contexte réglementaire, les organisations peuvent consulter la réglementation officielle RGPD ainsi que la documentation Vertica.
Architecture de Vertica et Considérations sur la Gouvernance des Données
Lors de l’évaluation de comment appliquer la gouvernance des données pour Vertica, l’architecture de la base de données elle-même devient un facteur central. Vertica fonctionne comme un moteur distribué, sans partage, en colonnes où les données sont segmentées, compressées et projetées dans des structures physiques optimisées ; cette conception accélère les charges analytiques tout en introduisant une complexité de gouvernance. Les attributs sensibles peuvent apparaître dans plusieurs projections, répliques ou chemins de requêtes, ce que les approches traditionnelles de gouvernance basées sur les lignes ne peuvent pas entièrement interpréter.
Par ailleurs, Vertica supporte des accès concurrents provenant d’outils BI, de pipelines ETL, de notebooks de machine learning et de comptes de service. En conséquence, la gouvernance doit prendre en compte non seulement les permissions statiques du schéma, mais aussi les schémas dynamiques de workload. Les analystes peuvent interroger la même table depuis des tableaux de bord, des outils d’exploration et des scripts Python, et chaque modèle d’accès produit une signature de risque distincte. Par conséquent, les organisations appliquant la gouvernance des données pour Vertica doivent intégrer le contexte du workload, l’identité, les règles de masquage et les bases comportementales dans l’évaluation des accès.
Classification des Données et Cartographie de la Sensibilité dans Vertica
Avant que les contrôles de gouvernance des données ne puissent être effectifs, les organisations doivent déterminer où résident les données sensibles dans les schémas et projections de Vertica. Les déploiements Vertica accumulent souvent de larges tables analytiques, des structures fortement dénormalisées et des variantes de projections où des attributs sensibles tels que les PII, PHI, jetons d’authentification et identifiants financiers apparaissent à des emplacements inattendus. De plus, la dérive des schémas ou les projections nouvellement générées peuvent exposer des informations auparavant contenues.
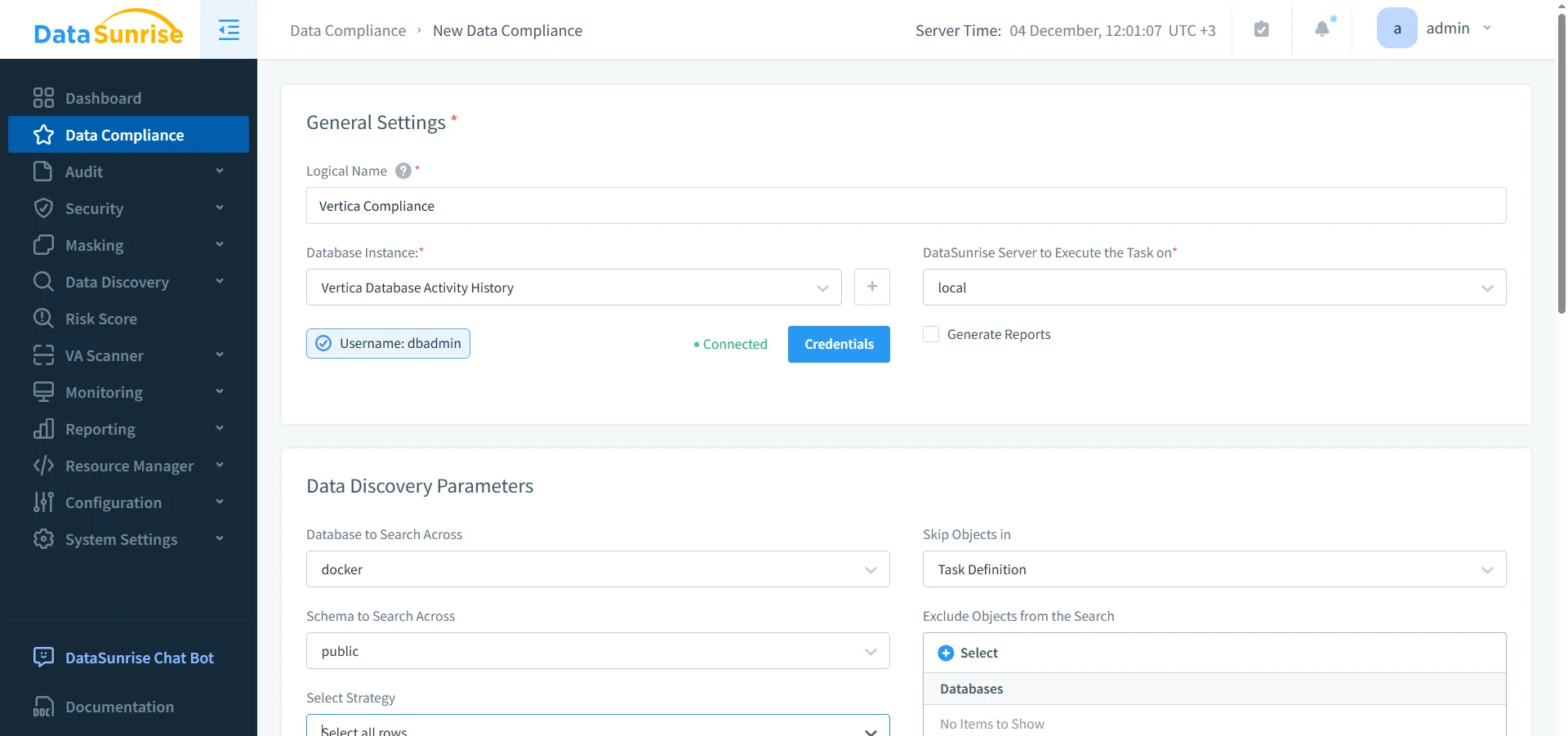
DataSunrise étend Vertica avec la Découverte des Données Sensibles, utilisant la correspondance de motifs, des dictionnaires et une logique contextuelle pour classer automatiquement les champs réglementés. DataSunrise stocke les résultats de la découverte de manière centralisée afin que les équipes de gouvernance puissent maintenir une cartographie continuellement mise à jour des actifs sensibles. Ce jeu de données de classification soutient directement des composants en aval tels que les règles de masquage, la conception des rôles et la validation de conformité.
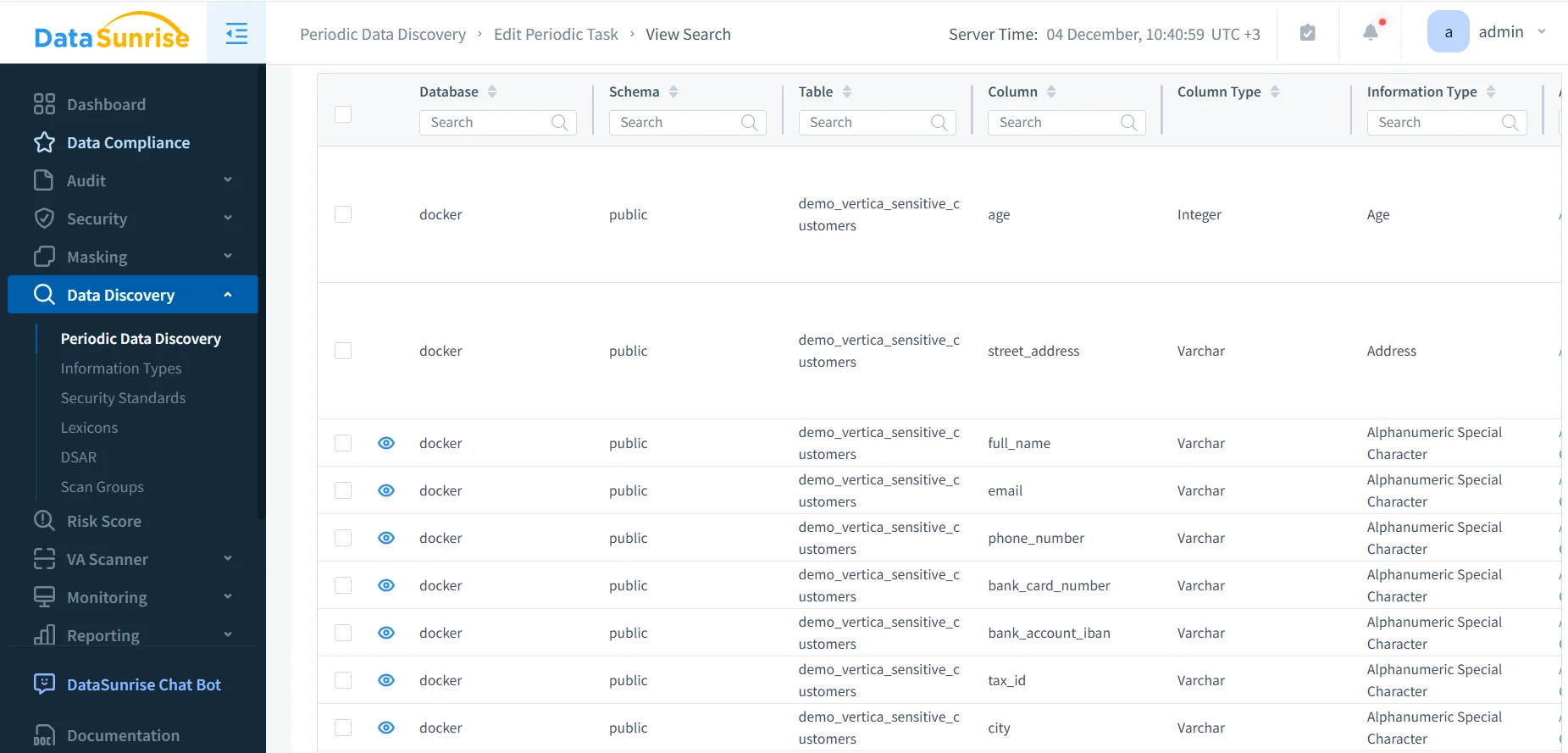
En outre, les équipes peuvent corréler les résultats de classification avec des directives internes et d’autres ressources DataSunrise telles que la classification des PII et les exigences plus larges de sécurité des données.
Comportement du Contrôle d’Accès et Application des Politiques
Vertica offre un système de contrôle d’accès basé sur les rôles (RBAC). En pratique, cependant, la gouvernance réelle exige des politiques plus granulaires et contextuelles. Les charges de travail peuvent provenir de tableaux de bord, moteurs ETL, intégrations JDBC ou pipelines ML, et chacune peut exposer des données sensibles différemment. Par conséquent, la gouvernance doit évaluer non seulement les privilèges au niveau des objets, mais aussi l’identité, l’origine de la requête, la structure de la requête et le contexte du masquage.
DataSunrise devient une couche d’application de politique en inspectant le trafic SQL avant qu’il n’atteigne Vertica. Cela permet aux administrateurs de mettre en œuvre des contrôles avancés que Vertica ne supporte pas nativement, notamment :
- masquage contextuel des champs sensibles,
- décisions d’accès basées sur le comportement,
- blocage de requêtes basé sur des règles via les Règles de Sécurité,
- notation des risques pour les opérations inhabituelles ou à fort impact.
Même lorsqu’un rôle Vertica accorde un accès SELECT à une table, DataSunrise peut toujours masquer des colonnes spécifiques, restreindre les requêtes ou outrepasser la visibilité selon les exigences de gouvernance des données. Conceptuellement, une politique de gouvernance appliquée par DataSunrise pour les charges Vertica peut ressembler à la structure suivante :
{
"database_type": "Vertica",
"rule_name": "Masquer les PII dans la table clients",
"match": {
"schema": "public",
"table": "customers",
"columns": ["email", "phone", "ssn"]
},
"actions": [
{
"type": "dynamic_masking",
"profile": "default_pii_mask"
}
],
"conditions": {
"roles_excluded": ["DS_ADMIN", "COMPLIANCE_OFFICER"]
}
}
Cet exemple illustre comment une politique de gouvernance peut décrire les objets Vertica, sélectionner les colonnes à protéger et définir les rôles exemptés du masquage pour besoins d’enquête ou de conformité. De plus, ce même modèle peut s’étendre à d’autres tables et schémas sans modifier le code applicatif ni les structures Vertica.
Masquage et Protection des Données pour les Charges Vertica
Appliquer la gouvernance des données pour Vertica nécessite un masquage cohérent sur tous les chemins d’accès. Parce que Vertica ne fournit pas de fonctionnalité de masquage intégrée, DataSunrise applique les règles de masquage au niveau des requêtes et protège les données sensibles, que les requêtes proviennent de tableaux de bord BI, d’outils SQL, de notebooks, d’applications personnalisées ou de pipelines d’automatisation.
- Masquage Dynamique remplace en temps réel les valeurs sensibles pendant l’exécution de la requête.
- Masquage Statique génère des jeux de données Vertica anonymisés pour le développement et les tests.
- Masquage contextuel adapte le comportement en fonction de l’identité, de l’application source ou de la classification du workload.
Parce que DataSunrise applique le masquage indépendamment des structures de stockage et des projections de Vertica, la couche de masquage reste prévisible, auditable et conforme à travers des workflows d’utilisation variés. Des concepts similaires sont abordés dans Masquage Dynamique des Données et Masquage Statique, qui décrivent aussi des schémas de masquage au-delà de Vertica.
Auditabilité et Surveillance des Charges Vertica
Vertica maintient des journaux opérationnels dans plusieurs tables système. Toutefois, corréler ces journaux en un enregistrement de gouvernance unifié devient difficile lorsque l’exécution distribuée fragmente le comportement des requêtes. Une seule opération utilisateur peut déclencher plusieurs étapes internes à travers des nœuds et des projections. Par conséquent, les équipes de gouvernance ont besoin de pistes d’audit normalisées qui reflètent le contexte complet de chaque action.
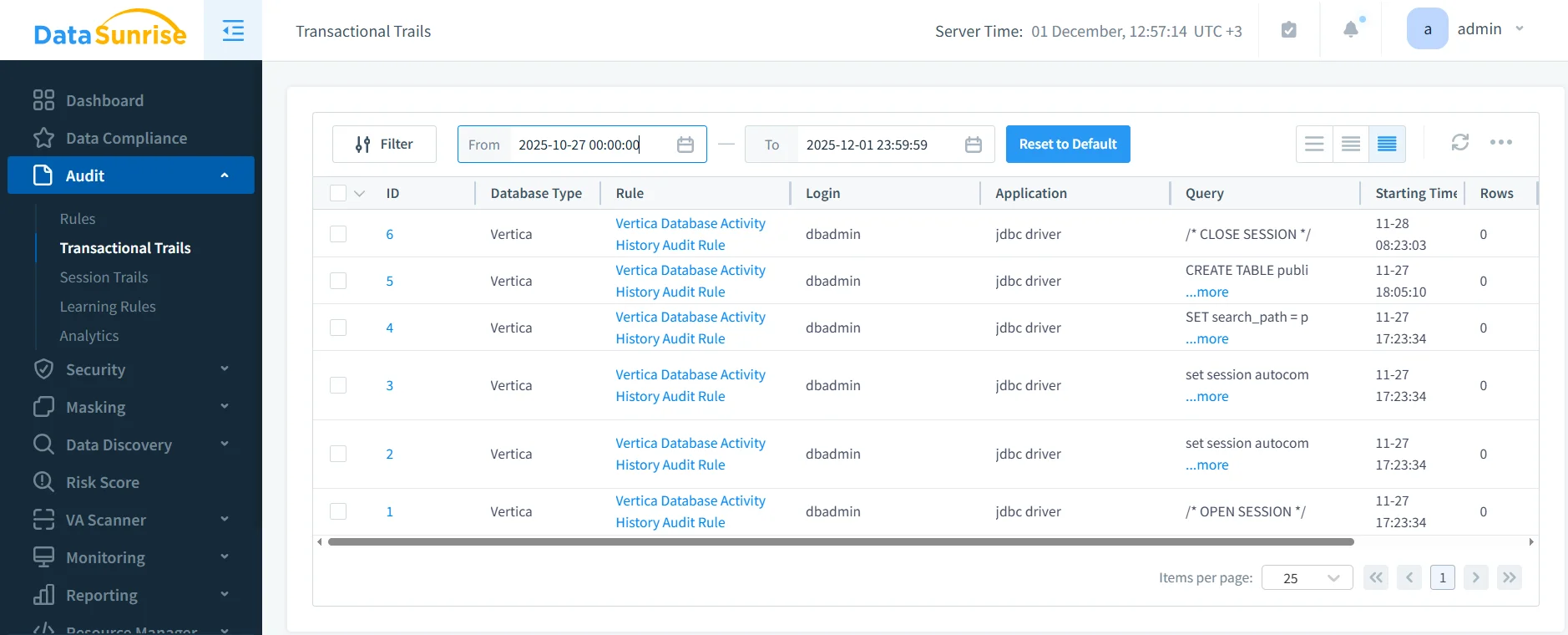
DataSunrise consolide tous les accès Vertica en flux d’audit unifiés. Il corrèle le comportement des sessions, les actions au niveau des requêtes, les résultats du masquage et les déclencheurs des règles de sécurité. Cette corrélation permet une reconstruction médico-légale fiable, la validation des politiques et la documentation de conformité. De plus, les équipes peuvent enrichir ces informations avec la Surveillance de l’Activité des Bases de Données, des Journaux d’Audit détaillés et des rapports automatisés via le Gestionnaire de Conformité.
Capacités de Gouvernance : Vertica vs DataSunrise
Le tableau ci-dessous compare les capacités natives de Vertica avec la fonctionnalité axée sur la gouvernance fournie par DataSunrise. Cette comparaison met en lumière précisément où les contrôles supplémentaires améliorent la façon dont les organisations appliquent la gouvernance des données pour Vertica et les plateformes associées.
| Domaine de Gouvernance | Capacité Native Vertica | Amélioration DataSunrise |
|---|---|---|
| Classification des Données | Revue manuelle ; modèles limités | Découverte Automatisée des Données Sensibles avec détection PII/PHI |
| Gouvernance des Accès | RBAC basique | Décisions d’accès contextuelles + Règles de Sécurité |
| Masquage des Données | Pas de fonctionnalité de masquage | Masquage Dynamique et Statique avec logique de politique |
| Audit et Surveillance | Journaux fragmentés | Pistes d’audit unifiées et corrélation inter-plateformes |
| Préparation à la Conformité | Assemblage manuel des preuves | Rapports automatisés pour RGPD, HIPAA, PCI DSS, SOX |
Conclusion : Comment Appliquer avec Succès la Gouvernance des Données pour Vertica
Comprendre comment appliquer la gouvernance des données pour Vertica nécessite une perspective technique sur la classification, l’application des accès, le comportement du masquage et la visibilité d’audit. Parce que Vertica fonctionne comme un moteur analytique distribué, ses besoins de gouvernance vont au-delà du RBAC natif et de la journalisation. Les couches d’application externes comme DataSunrise fournissent un masquage cohérent, des audits centralisés, une découverte automatisée et des contrôles comportementaux qui maintiennent Vertica alignée avec les politiques réglementaires et internes. Avec cette architecture de gouvernance en place, Vertica devient une base sécurisée et conforme pour l’analyse à grande échelle et l’intelligence d’entreprise.
