Comment automatiser la conformité des données pour Elasticsearch
Elasticsearch alimente la recherche, l’analytique, le traitement des logs et l’observabilité dans les applications modernes. Sa nature distribuée et son modèle flexible de documents JSON permettent un indexage rapide et des analyses en temps réel, mais ces mêmes forces posent des défis en matière de conformité. De nouveaux champs apparaissent sans prévenir, les mappings évoluent dynamiquement, et les indices peuvent se répartir sur plusieurs clusters en quelques secondes. Les informations sensibles peuvent être stockées de manière incohérente, et les contrôles manuels peinent souvent à suivre le rythme des structures de données qui changent rapidement.
L’automatisation de la conformité des données dans Elasticsearch est essentielle pour maintenir la sécurité, la confidentialité et l’alignement réglementaire. Cet article explique comment les outils automatisés rationalisent les workflows de conformité, quelles fonctionnalités natives propose Elasticsearch, et comment DataSunrise étend ces capacités avec la découverte, le masquage, l’audit et la gouvernance centralisée.
Qu’est-ce que la conformité des données ?
La conformité des données est la pratique visant à protéger les informations sensibles selon les exigences légales, réglementaires et organisationnelles. Elle garantit que les données personnelles, financières, médicales et commerciales confidentielles sont collectées, traitées et stockées de manière sécurisée.
Des réglementations telles que le RGPD, HIPAA, SOX et PCI DSS définissent des règles strictes pour le contrôle d’accès, le reporting, la rétention et l’audit. Dans Elasticsearch, maintenir la conformité est complexe car les documents JSON et les mappings évoluent constamment. L’automatisation assure que ces normes sont appliquées de manière cohérente sur tous les indices et environnements.
Les organisations s’appuient souvent sur des outils centralisés tels que le Gestionnaire de conformité DataSunrise pour évaluer les risques, détecter les violations et maintenir l’alignement réglementaire.
Capacités natives de conformité dans Elasticsearch
Elasticsearch inclut plusieurs fonctionnalités intégrées qui soutiennent la conformité, bien qu’elles nécessitent une configuration minutieuse et manquent souvent d’adaptation automatisée aux données évolutives. Des conseils supplémentaires proviennent fréquemment de ressources telles que la base de connaissances DataSunrise Data Discovery et le Guide de sécurité.
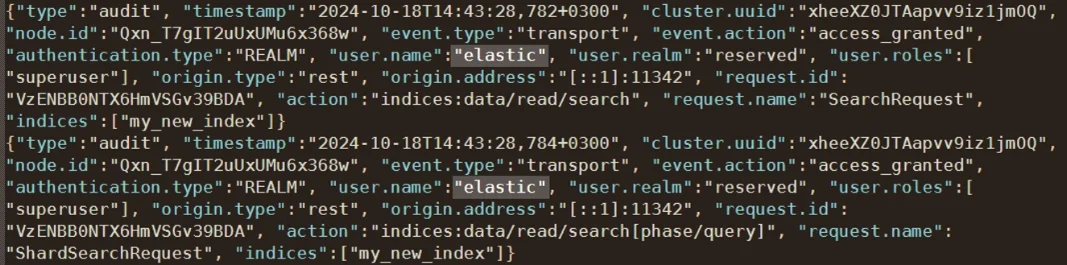
Journalisation d’audit
Elasticsearch peut enregistrer l’activité d’accès, les mises à jour d’indices, les tentatives d’authentification et les actions administratives. La journalisation d’audit permet aux administrateurs de capturer des informations détaillées sur qui a accédé à quoi, quand et comment.
De nombreuses organisations utilisent également des systèmes de surveillance basés sur le Guide d’audit DataSunrise et la documentation sur les journaux d’audit afin d’assurer la cohérence entre les environnements.
Exemple : activation de la journalisation d’audit X-Pack
xpack.security.audit.enabled: true
xpack.security.audit.logfile.events.include:
- access_granted
- access_denied
- authentication_success
- authentication_failed
xpack.security.audit.outputs: [ logfile ]
Bien que les journaux d’audit permettent de suivre le comportement des utilisateurs et d’identifier des motifs suspects, ils ne classifient pas automatiquement les informations sensibles, ne détectent pas les changements structurels, ni n’appliquent des règles de conformité. Des technologies complémentaires telles que le module Data Audit Trail contribuent à combler ces lacunes.
Contrôles d’accès basés sur les rôles
Elasticsearch supporte des restrictions au niveau des champs et des documents via RBAC, Document-Level Security (DLS) et Field-Level Security (FLS). Ces mécanismes appliquent le principe du moindre privilège. De nombreuses équipes complètent cela par la référence RBAC et les directives de politique de sécurité des données.
Exemple : restriction d’accès à des champs sensibles
{
"indices": [
{
"names": [ "customer*" ],
"privileges": [ "read" ],
"field_security": {
"grant": [ "name", "email" ],
"except": [ "ssn", "credit_card_number" ]
},
"query": {
"term": { "active": true }
}
}
]
}
Le RBAC seul ne classe pas les champs sensibles, ne détecte pas les nouveaux types de données, ni n’applique de masquage lorsque la structure évolue. Les organisations intègrent souvent ces contrôles à des systèmes tels que le cadre de sécurité des bases de données et le moteur de priorité des règles pour assurer une application automatisée et cohérente.
Templates et schémas d’index
Les templates d’index permettent de définir des mappings, paramètres et motifs de nommage qui contribuent à garantir une cohérence structurelle entre les indices. Ils standardisent la façon dont les champs sensibles sont indexés, particulièrement dans les clusters à fort volume de logs ou de données utilisateur.
Pour soutenir ces processus, les équipes combinent souvent les templates d’index avec des pratiques de surveillance mentionnées dans le guide de surveillance de l’activité des bases de données.
Exemple : template avec structure prédéfinie pour champs sensibles
{
"index_patterns": [ "customer-*" ],
"template": {
"mappings": {
"properties": {
"ssn": { "type": "keyword" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
}
Pour garantir une gouvernance cohérente, les organisations s’appuient également sur des ressources telles que l’aperçu de DataSunrise et les fondamentaux de la sécurité des données afin de construire des architectures de conformité résilientes.
Automatisation de la conformité Elasticsearch avec DataSunrise
DataSunrise étend les capacités natives d’Elasticsearch avec la découverte automatisée, le masquage, l’audit et la gouvernance centralisée. Cela élimine la supervision manuelle et garantit une protection cohérente dans des clusters dynamiques.
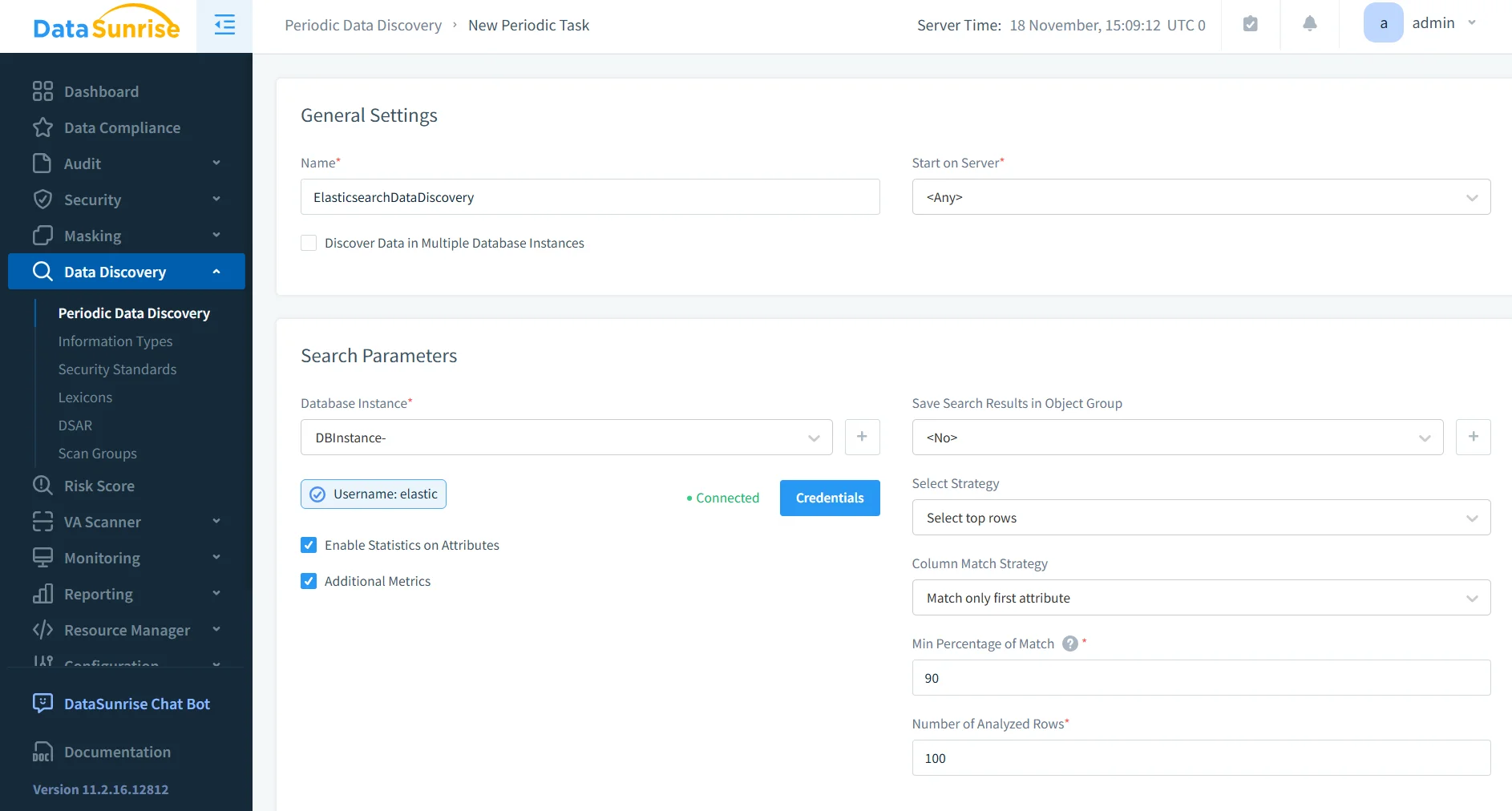
Découverte sans intervention
DataSunrise analyse en continu le trafic Elasticsearch et les structures d’index pour identifier les données sensibles sans nécessiter de configuration manuelle. Il utilise des modèles d’apprentissage automatique, des classifieurs de motifs et des techniques de traitement du langage naturel pour analyser les objets JSON imbriqués et détecter les informations personnelles, financières et médicales.
Cette capacité s’intègre parfaitement avec le moteur de découverte DataSunrise, garantissant que les champs sensibles sont reconnus dès leur apparition.
Au fur et à mesure que les clusters évoluent, DataSunrise analyse automatiquement les nouveaux indices et champs pour maintenir une cartographie précise de la conformité.
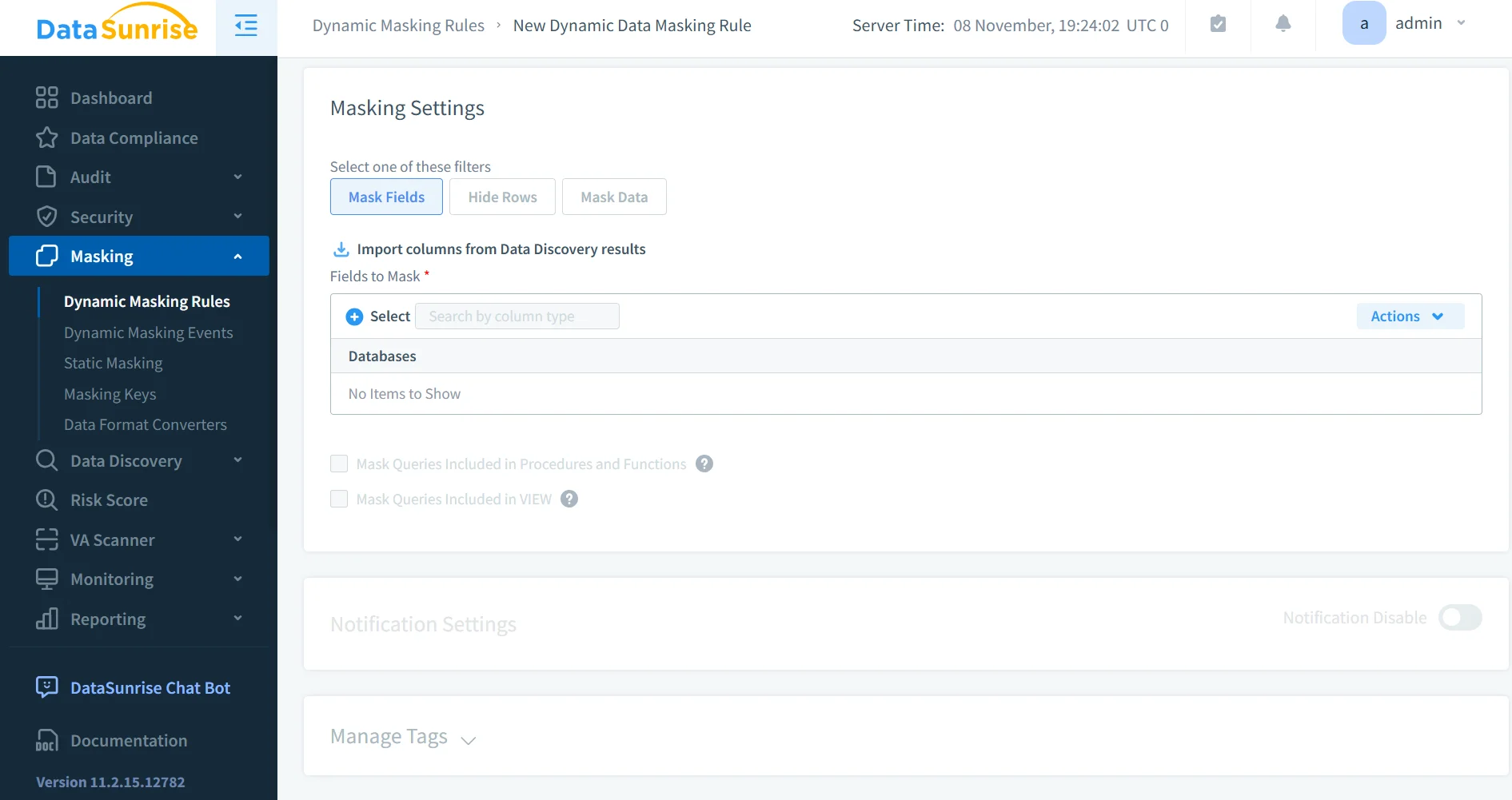
Masquage dynamique
Le masquage dynamique protège les informations sensibles en appliquant des transformations aux réponses des requêtes Elasticsearch en temps réel. Au lieu de modifier les données stockées, le proxy DataSunrise masquent les champs en fonction des rôles utilisateurs et des permissions d’accès.
Cette technique suit les principes documentés dans la référence sur le masquage dynamique des données, garantissant que les tableaux de bord, API et applications continuent de fonctionner sans exposer les valeurs réglementées.
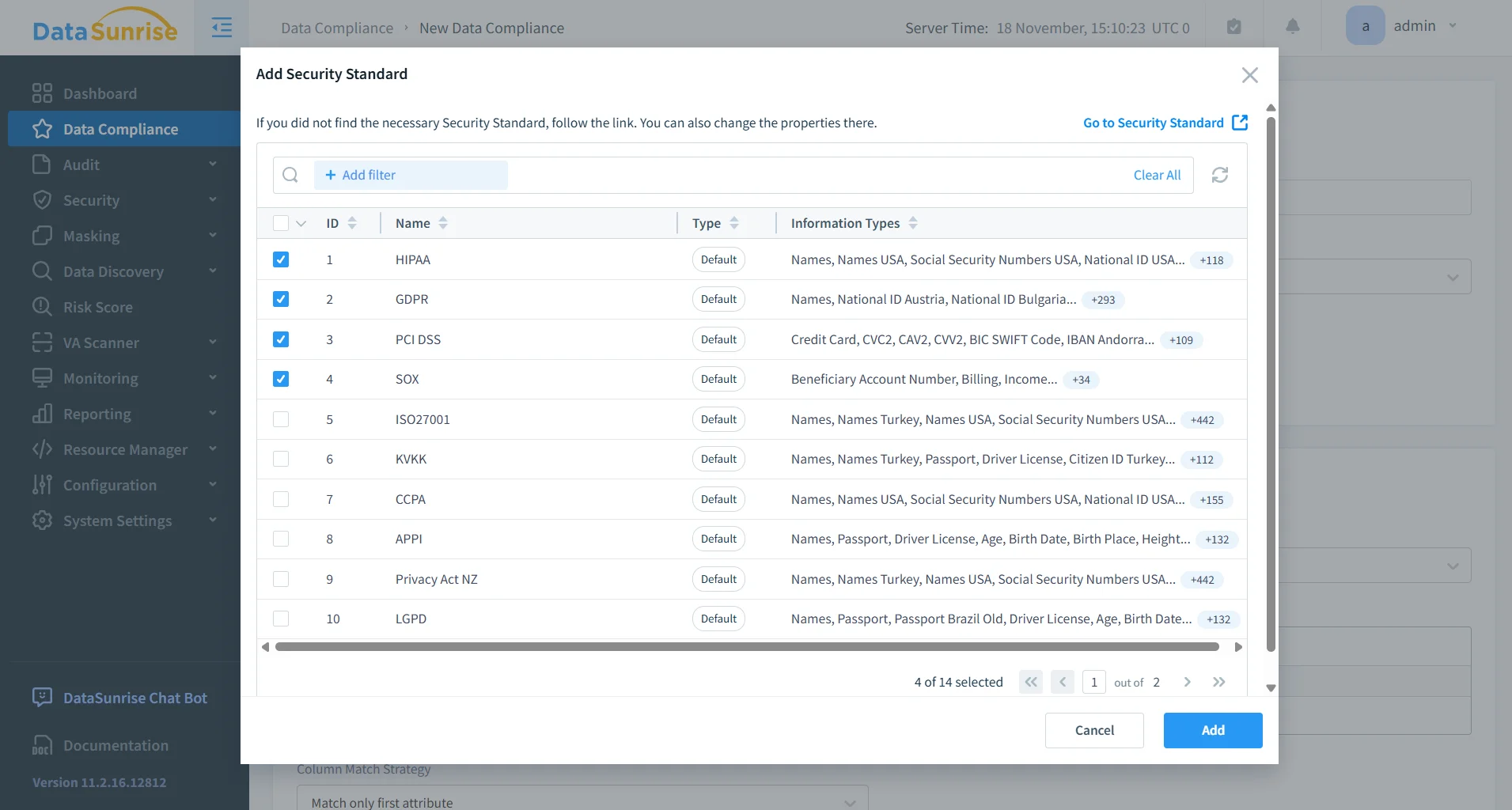
Alignement réglementaire continu
DataSunrise évalue les données Elasticsearch, les modèles d’accès et les structures de champs pour garantir la conformité avec le RGPD, HIPAA, PCI DSS et SOX.
Il exploite l’intelligence de la plateforme de gestion de conformité pour identifier les violations, recommander des règles de masquage ou d’accès, et détecter les dérives lors de l’apparition de nouveaux champs.
Cela réduit la revue manuelle et assure un alignement continu avec les cadres réglementaires.
Traçabilité automatisée des audits
Chaque requête transmise par DataSunrise est enregistrée en tant qu’événement d’audit détaillé, offrant une visibilité unifiée sur la façon dont les données Elasticsearch sont consultées et modifiées.
Les organisations prolongent généralement cette fonctionnalité en s’appuyant sur des références comme la documentation des journaux d’audit et l’article sur les pistes d’audit des données pour répondre aux obligations réglementaires et conserver des archives d’audit à long terme.
Application uniforme à travers les environnements
Les règles de conformité, configurations de masquage et paramètres d’audit peuvent être synchronisés entre les infrastructures de développement, test, préproduction et production.
Cette approche de gouvernance est souvent associée à des cadres plus larges comme le Guide de sécurité et la documentation sur la sécurité des bases de données afin d’obtenir une application cohérente et multi-environnements.
Principaux avantages de la conformité automatisée
| Avantage | Description |
|---|---|
| Réduction des efforts manuels | La découverte et la génération automatiques des politiques éliminent la maintenance fastidieuse des règles et réduisent le risque de mauvaise configuration. |
| Renforcement de la protection des données | Le masquage dynamique et l’isolement des données sensibles garantissent que les champs régulés restent protégés, même lorsque les clusters s’étendent ou que de nouveaux documents apparaissent. |
| Gouvernance cohérente | Les contrôles centralisés créent une posture uniforme de conformité sur tous les environnements, réduisant les écarts dus aux dérives de configuration. |
| Audit plus rapide | Les enregistrements d’activité unifiés et les modèles préconstruits simplifient les rapports pour les audits internes et les obligations réglementaires. |
| Support des architectures hybrides | L’automatisation prend en charge les déploiements cloud, sur site et containerisés, réduisant la complexité des empreintes Elasticsearch distribuées. |
Conclusion
La flexibilité d’Elasticsearch permet un indexage rapide, des analyses et une recherche performante, mais elle introduit aussi des risques de conformité lorsque les structures de données évoluent rapidement. Bien que les outils natifs fournissent des contrôles de sécurité de base, ils ne suffisent pas pour les environnements réglementés ou à évolution rapide.
DataSunrise automatise la découverte, le masquage, les pistes d’audit et l’alignement réglementaire sans nécessiter de modifications de Elasticsearch lui-même. Grâce à une conformité continue alimentée par une analyse intelligente et une application automatique des règles, les organisations peuvent maintenir une protection solide avec un minimum d’efforts opérationnels.
