
Brouillage de données

Introduction
Dans le monde actuel axé sur les données, la protection des informations sensibles est primordiale. Les fuites de données et l’accès non autorisé aux informations confidentielles peuvent entraîner de graves conséquences pour les individus et les organisations. C’est ici qu’intervient le brouillage de données.
Le brouillage de données est une technique utilisée pour obscurcir les données sensibles tout en en préservant le format, la structure et l’utilité d’origine. Cet article explique les notions de base du brouillage de données, les différentes techniques ainsi que des conseils pour sa mise en œuvre dans votre organisation.
Qu’est-ce que le brouillage de données ?
Le brouillage de données, également connu sous le nom de masquage de données, remplace les informations sensibles par de fausses données afin de protéger la vie privée. Le but est de protéger les données originales tout en maintenant leur utilité pour les tests, le développement ou l’analyse. Les données brouillées ressemblent aux données originales et peuvent être utilisées dans des environnements non productifs.
Par exemple, imaginez une base de données contenant des détails sur les clients. Vous pouvez recourir à des techniques de brouillage de données au lieu d’utiliser de vrais noms, adresses et numéros de cartes de crédit dans des environnements de développement ou d’assurance qualité.
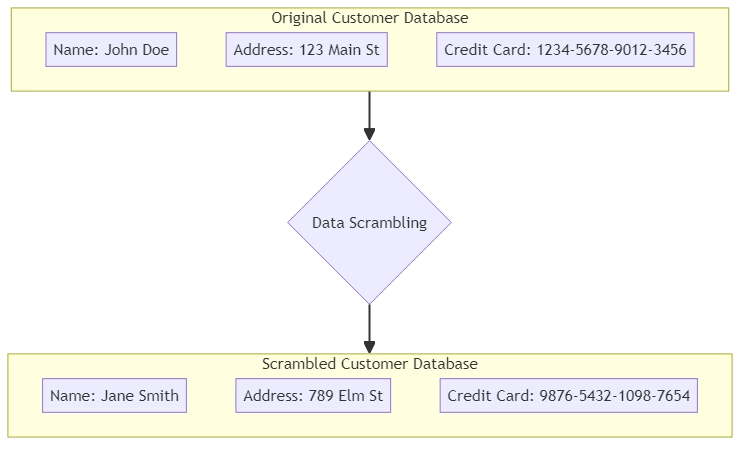
Ces méthodes remplacent les données sensibles par des valeurs générées aléatoirement qui imitent les informations originales.
Brouillage de données vs Masquage de données
Bien qu’ils soient souvent utilisés de manière interchangeable, le brouillage de données et le masquage de données présentent des distinctions importantes. Le brouillage de données se concentre principalement sur la randomisation ou la réorganisation des données tout en préservant le format. Il implique généralement des transformations irréversibles et est couramment utilisé pour la préparation de données de test où les valeurs exactes sont moins importantes que le maintien des propriétés statistiques.
En revanche, le masquage de données met l’accent sur le remplacement des données sensibles par des valeurs substitutives fonctionnelles et réalistes qui « préservent l’apparence des données tout en dissimulant les informations sensibles ». Contrairement au brouillage, le masquage peut être partiellement ou totalement réversible pour les utilisateurs autorisés et est souvent employé dans des environnements de production où le maintien de la structure des données et de l’intégrité référentielle est crucial.
Les deux techniques sont reconnues dans des cadres de conformité tels que le RGPD, la HIPAA et la norme PCI DSS. De nombreuses organisations mettent en œuvre les deux techniques dans le cadre d’une stratégie globale de sécurité des données, en appliquant la méthode appropriée en fonction du contexte spécifique et de la sensibilité des données à protéger.
Pourquoi le brouillage de données est-il important ?
Le brouillage de données joue un rôle crucial dans la protection des informations sensibles et la garantie de la conformité aux réglementations en matière de confidentialité des données. Voici quelques raisons clés pour lesquelles le brouillage de données est essentiel :
- Protection des données sensibles : En remplaçant les données sensibles par des valeurs fictives, le brouillage de données aide à prévenir l’accès non autorisé aux informations confidentielles. Même si les données brouillées tombent entre de mauvaises mains, elles ne révèlent aucun détail sensible réel.
- Conformité aux réglementations : De nombreuses industries sont soumises à des réglementations strictes en matière de confidentialité des données, telles que le RGPD, la HIPAA ou le PCI-DSS. Le brouillage de données aide les organisations à se conformer à ces réglementations en dépersonnalisant les données sensibles avant de les utiliser à des fins de test, de développement ou d’analyse.
- Permettre des tests et un développement réalistes : Les données brouillées ressemblent aux données originales. Les développeurs et les testeurs peuvent les utiliser pour travailler avec des données similaires à celles de la production. Cela garantit que les tests sont plus précis et réduit le risque de problèmes lors du déploiement de l’application en production.
- Réduire l’impact des fuites de données : En cas de fuite, les données brouillées réduisent la probabilité d’exposer des informations sensibles réelles, atténuant ainsi les dommages potentiels.
- Faciliter le partage de données : Le brouillage de données permet aux organisations de partager des informations avec des tiers, tels que des partenaires ou des fournisseurs, sans compromettre la confidentialité des informations sensibles. Les utilisateurs peuvent utiliser les données brouillées pour collaborer ou analyser, tout en maintenant la confidentialité des données originales.
Cas d’utilisation réels du brouillage de données
Le brouillage de données est largement adopté dans diverses industries pour protéger les informations sensibles tout en répondant aux besoins opérationnels. Voici quelques exemples de la manière dont les organisations utilisent le brouillage de données en pratique :
- Santé : Les dossiers des patients contenant des informations personnelles de santé (IPS) sont brouillés afin de permettre des tests et un développement sûrs des logiciels médicaux sans exposer de réelles données patient.
- Services financiers : Les banques et les processeurs de paiement brouillent les numéros de carte de crédit et les détails des transactions pour protéger les données clients lors des tests d’applications et des analyses, aidant ainsi à respecter les normes PCI-DSS.
- Distribution : Les détaillants brouillent les noms, adresses et historiques d’achat des clients afin de partager les données en toute sécurité avec des fournisseurs tiers ou des partenaires marketing sans risquer des violations de la vie privée.
- Agences gouvernementales : Les données sensibles des citoyens sont brouillées pour faciliter l’analyse interne et la recherche tout en se conformant aux réglementations sur la protection des données.
Ces applications concrètes démontrent comment le brouillage de données aide les organisations à trouver l’équilibre entre la confidentialité des données et les exigences opérationnelles, permettant une utilisation sécurisée et efficace des informations sensibles.
Techniques de brouillage
Différentes techniques de brouillage de données existent, chacune ayant ses propres avantages et cas d’utilisation. Explorons quelques techniques de brouillage courantes :
1. Substitution
Dans la substitution, on remplace les données sensibles par des valeurs aléatoires issues d’un ensemble ou suivant un modèle. Par exemple, vous pouvez transformer des noms en noms fictifs à partir d’une liste. Vous pouvez également remplacer des numéros de carte de crédit par des numéros syntaxiquement valides qui passent les contrôles de format (comme l’algorithme de Luhn) mais qui ne correspondent à aucun compte réel.
Exemple :
Données originales : John Doe, 1234-5678-9012-3456 Données brouillées : Jane Smith, 9876-5432-1098-7654
2. Mélange
Le mélange consiste à réorganiser l’ordre des valeurs de données au sein d’une colonne ou entre plusieurs colonnes. Cette technique maintient la distribution originale des données tout en brisant la relation entre différentes colonnes. Le mélange est utile lorsque la préservation de la distribution statistique est importante, mais que l’association individuelle valeur-enregistrement ne l’est pas.
Exemple : Données originales :
Nom Age Salaire John Doe 35 50000 Jane Doe 28 60000
Données brouillées (colonnes Âge et Salaire mélangées) :
Nom Age Salaire John Doe 28 60000 Jane Doe 35 50000
3. Chiffrement
Le chiffrement consiste à convertir les données sensibles en un format illisible en utilisant un algorithme de chiffrement et une clé secrète. Vous ne pouvez déchiffrer les données brouillées pour retrouver leur forme originale qu’en utilisant la clé de déchiffrement correspondante. Le chiffrement offre un haut niveau de sécurité mais peut impacter les performances, et contrairement au brouillage, il nécessite une gestion en temps réel des clés pour les processus de chiffrement/déchiffrement.
Exemple :
Données originales : John Doe Données brouillées : a2VsZmF0aG9uIGRvb3IgZ
4. Tokenisation
La tokenisation remplace les données sensibles par un jeton ou identifiant généré aléatoirement. Le système stocke en toute sécurité les données sensibles dans une base de données ou un coffre séparé. L’utilisateur utilise ensuite le jeton pour récupérer l’information originale lorsqu’il en a besoin. Les entreprises utilisent couramment la tokenisation pour protéger les numéros de carte de crédit et d’autres données financières sensibles. La tokenisation est particulièrement précieuse dans les industries traitant de données de paiement, telles que la finance et la distribution, et est souvent utilisée en conformité avec les normes PCI-DSS.
Exemple :
Données originales : 1234-5678-9012-3456 Données brouillées : TOKEN-1234
5. Masquage
Trois techniques de masquage courantes incluent le masquage de caractères, le masquage partiel et le masquage par expression régulière. Le masquage de caractères consiste à remplacer les caractères par un symbole. Le masquage partiel ne montre qu’une partie des données. Le masquage par expression régulière remplace les données selon un modèle prédéfini.
Exemple :
Données originales : 1234-5678-9012-3456 Données masquées : XXXX-XXXX-XXXX-3456
Bonnes pratiques pour le brouillage de données
Pour mettre en œuvre efficacement le brouillage de données dans votre organisation, considérez les bonnes pratiques suivantes :
- Identifier les données sensibles : Effectuez un examen approfondi de votre environnement de données afin d’identifier les éléments sensibles nécessitant un obscurcissement. Prenez en compte les exigences légales et réglementaires, ainsi que les politiques internes de classification des données de votre organisation.
- Choisir les techniques de brouillage appropriées : Sélectionnez la méthode de brouillage ou de chiffrement la plus adaptée en fonction du type de données et de leur utilisation prévue. Prenez en considération des facteurs tels que le format des données, leur complexité et le niveau de sécurité requis.
- Maintenir la cohérence des données : Assurez-vous que les données brouillées conservent l’intégrité référentielle et la constance à travers les tables et systèmes liés. Utilisez des techniques de brouillage, des valeurs de graine et des règles cohérentes pour garantir leur reproductibilité lorsque cela est nécessaire.
- Protéger les algorithmes et les clés de brouillage : Sauvegardez les algorithmes, règles et clés de chiffrement utilisés pour le brouillage des données. Stockez-les en lieu sûr et limitez leur accès uniquement au personnel autorisé.
- Tester et valider les données brouillées : Examinez minutieusement les données altérées pour vous assurer qu’elles respectent le format requis, ainsi que les normes de qualité et d’uniformité. Vérifiez que les données brouillées ne contiennent aucune information confidentielle et qu’elles conviennent à l’usage prévu.
- Établir des contrôles d’accès : Mettez en place des contrôles stricts et une surveillance active afin d’empêcher l’accès non autorisé aux données sensibles et brouillées. Passez en revue et mettez régulièrement à jour les autorisations d’accès.
- Documenter et maintenir les processus de brouillage : Documentez le processus d’intégration des données, y compris le volume de données concerné et toutes configurations ou directives spécifiques. Assurez une gestion de version et mettez la documentation à jour.
- Auditer et surveiller l’utilisation du brouillage : Procédez régulièrement à des audits de l’utilisation du brouillage des données afin de garantir la conformité, de détecter les abus et de vérifier que les techniques restent efficaces face aux menaces émergentes sur les données.
Conclusion
Le brouillage de données est une technique efficace pour protéger les informations sensibles tout en permettant leur utilisation dans des tests, le développement et l’analyse. En substituant les données réelles par des valeurs réalistes mais fictives, les organisations peuvent protéger les détails confidentiels, assurer leur conformité aux lois sur la confidentialité des données et permettre un partage sécurisé des données.
Lors de la mise en œuvre du brouillage de données, il est crucial de choisir des méthodes adaptées à la sensibilité des données, à leur structure et à leur usage prévu. Le respect des bonnes pratiques – telles que le maintien de la cohérence des données, la sécurisation des algorithmes et des clés de chiffrement, et l’application de contrôles d’accès stricts – contribuera à garder vos données en sécurité.
L’intégration du brouillage de données dans votre stratégie globale de protection des données vous permet de trouver le juste équilibre entre l’utilité des données et la préservation de la vie privée, favorisant ainsi la confiance parmi vos clients et parties prenantes tout en utilisant vos données de manière efficace.
