
Permutation de noms
Introduction
Les organisations ont souvent du mal à protéger les données sensibles tout en ayant besoin d’ensembles de données réalistes pour les tests et le développement. C’est là que des techniques telles que la permutation de noms et le masquage des données entrent en jeu.
Voici un fait amusant : l’Administration de la sécurité sociale des États-Unis publie chaque année des données sur les prénoms des bébés, avec environ 30 000 à 35 000 noms uniques utilisés chaque année. Ce type d’ensemble de données est idéal pour générer des données de test crédibles tout en restant anonymisées.
Cet article explore le fonctionnement de la permutation de noms, comment elle est mise en œuvre et pourquoi elle est efficace pour créer des environnements de test sécurisés.
DataSunrise offre des capacités avancées de masquage des données — y compris la permutation intelligente — qui préservent le réalisme tout en garantissant la confidentialité. Notre plateforme aide les organisations à respecter les exigences réglementaires et à protéger les données sensibles sans sacrifier la fonctionnalité.
Avec DataSunrise, vous pouvez sélectionner aléatoirement des valeurs à partir de lexiques personnalisés — soit créés manuellement, soit extraits de bases de données en direct. Cela permet à la fois une permutation déterministe et une substitution aléatoire pour générer des données de test de haute qualité et sécurisées.
Qu’est-ce que le masquage des données ?
Avant d’aborder la permutation de noms, évoquons brièvement le masquage des données. Le masquage des données est une méthode utilisée pour créer une version structurellement similaire mais inauthentique des données d’une organisation. Il remplace les informations sensibles par des données réalistes mais fictives. Cela permet aux entreprises d’utiliser des données masquées pour les tests, le développement et l’analyse sans risquer de divulguer des informations confidentielles.
Réglementations et conformité en matière de masquage des données
Les cadres réglementaires imposent de plus en plus la protection des données via des techniques de masquage. Le RGPD exige des mesures de protection appropriées pour le traitement des données personnelles. La HIPAA impose la protection des informations de santé dans les environnements non productifs. La norme PCI DSS interdit l’utilisation de données réelles des titulaires de carte pour les tests. Le CCPA donne aux consommateurs le contrôle sur l’utilisation des informations personnelles. Les normes industrielles exigent souvent l’anonymisation des données de test. Les organisations de santé sont confrontées à des exigences strictes en matière de confidentialité des données des patients. Les institutions financières doivent protéger les informations financières de leurs clients pendant le développement. Les sanctions en cas de non-respect peuvent atteindre des millions de dollars. Le masquage des données fournit une preuve documentée de la conformité à la confidentialité. Les réglementations exigent souvent des évaluations formelles des risques liés à la gestion des données. Des audits de conformité réguliers vérifient la bonne mise en œuvre du masquage. Les entreprises doivent démontrer des mesures de sécurité raisonnables grâce à des techniques comme la permutation.
Comprendre la permutation de noms
Qu’est-ce que la permutation de noms ?
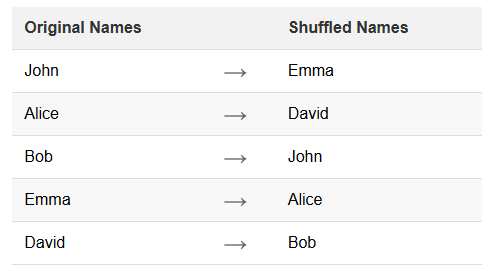
La permutation de noms est une technique spécifique de masquage des données. Elle consiste à réorganiser les données existantes au sein d’un ensemble de données. Cette méthode préserve l’intégrité et le réalisme des données tout en masquant l’identité des individus. La permutation est particulièrement utile pour protéger les informations personnelles dans les bases de données.
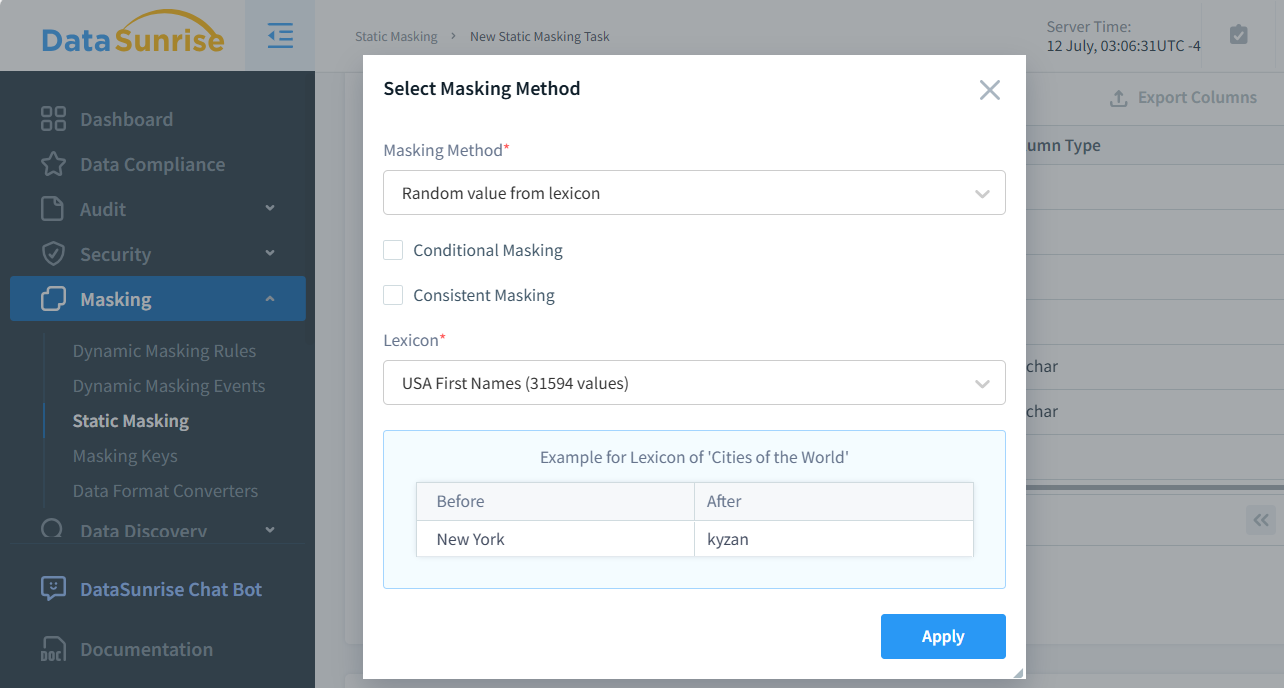
Comme mentionné dans l’introduction, DataSunrise vous permet de créer une sélection aléatoire de valeurs basée sur un lexique pour le masquage. La figure ci-dessous montre la sélection de cette méthode de masquage dans l’interface utilisateur de DataSunrise. Comme vous pouvez le voir, 31 594 valeurs sont disponibles, ce qui est bien plus fiable que de simplement permuter un ensemble donné. Cette fiabilité accrue s’explique par le fait que lorsqu’il y a n valeurs uniques dans une colonne, la probabilité qu’une valeur donnée soit mappée sur elle-même est de 1/n.
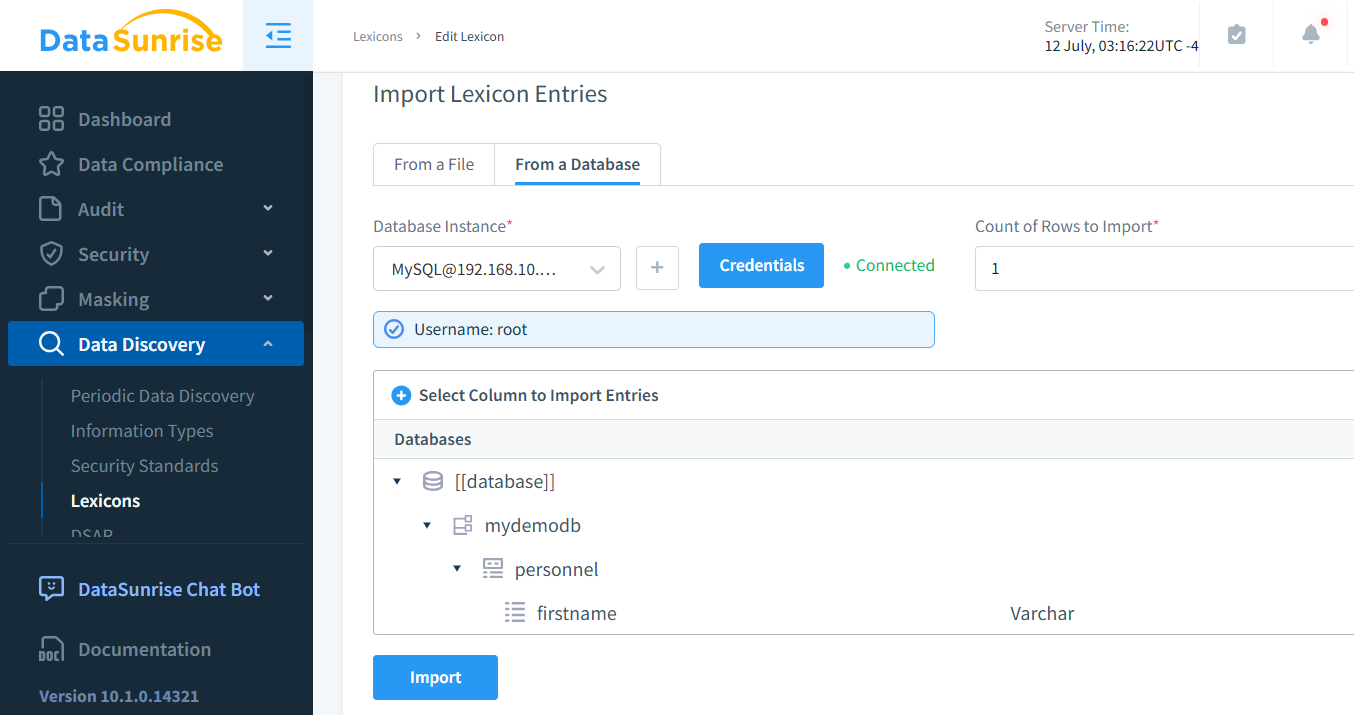
Si vous préférez effectuer un mappage avec des valeurs existantes, vous pouvez facilement y parvenir en créant un lexique personnalisé. Cette approche est particulièrement bénéfique dans les situations où les valeurs permutées ne sont pas des prénoms américains, car elle permet un masquage des données plus contextuellement approprié.
Comment fonctionne la permutation de noms ?
Le processus est simple :
- Sélectionnez une colonne contenant des noms (prénoms, noms de famille, ou les deux).
- Réorganisez aléatoirement les valeurs au sein de cette colonne.
- Remplacez les valeurs d’origine par les valeurs permutées.
Cette technique préserve la distribution et les caractéristiques des données d’origine. Cependant, elle rompt le lien entre les individus et leurs informations.
Mise en œuvre de la permutation de noms en R et Python
Explorons comment implémenter la permutation de noms la plus simple dans deux langages de programmation populaires : Python et R.
Il est important de noter que le niveau d’utilisabilité offert par DataSunrise est inégalé dans ce contexte. Créer une solution flexible et tout-en-un avec seulement quelques lignes de code n’est pas réalisable avec les langages de programmation standards. Notre objectif ici est de mettre en lumière les capacités d’outils spécialisés comme DataSunrise par rapport aux langages de programmation à usage général.
Permutation de noms en Python
Python offre des moyens simples et efficaces de permuter des données. Voici un exemple utilisant pandas, une puissante bibliothèque de manipulation de données :
import pandas as pd
import numpy as np
# Création d'un ensemble de données d'exemple
data = pd.DataFrame({
'FirstName': ['John', 'Alice', 'Bob', 'Emma', 'David'],
'LastName': ['Smith', 'Johnson', 'Williams', 'Brown', 'Jones'],
'Age': [32, 28, 45, 36, 51],
'Salary': [50000, 60000, 75000, 65000, 80000]
})
# Permuter la colonne FirstName
data['FirstName'] = np.random.permutation(data['FirstName'])
# Permuter la colonne LastName
data['LastName'] = np.random.permutation(data['LastName'])
print(data)
Ce script crée un ensemble de données d’exemple et permute les colonnes FirstName et LastName. Le résultat conserve les noms d’origine tout en les remettant dans un ordre aléatoire, masquant ainsi efficacement l’identité des individus.
Permutation de noms en R
R propose également des méthodes simples pour la permutation des données. Voici un exemple :
# Création d'un ensemble de données d'exemple
data <- data.frame(
FirstName = c("John", "Alice", "Bob", "Emma", "David"),
LastName = c("Smith", "Johnson", "Williams", "Brown", "Jones"),
Age = c(32, 28, 45, 36, 51),
Salary = c(50000, 60000, 75000, 65000, 80000)
)
# Permuter la colonne FirstName
data$FirstName <- sample(data$FirstName)
# Permuter la colonne LastName
data$LastName <- sample(data$LastName)
print(data)
Ce script en R obtient le même résultat que l’exemple en Python. Il permute les colonnes FirstName et LastName, préservant l’intégrité des données tout en masquant l’identité des individus.
Permutation de noms : avantages et considérations
La permutation de noms est une technique d’anonymisation des données populaire qui remplace les noms d’origine par des alternatives permutées afin de protéger la vie privée tout en préservant l’utilité des données. Voici un récapitulatif de ses principaux avantages et considérations :
| Avantage | Considération |
|---|---|
| Préserve le réalisme des données Les valeurs permutées ressemblent à l’ensemble des données d’origine, rendant les données utiles pour les tests et l’analyse. |
Risques liés à l’unicité Les noms rares ou uniques peuvent rester identifiables après permutation. |
| Préserve la distribution des données Les profils de fréquence restent inchangés, soutenant l’intégrité statistique. |
Consistance entre les tables Assurez-vous que le même nom est mappé de manière cohérente à travers les tables liées pour éviter des problèmes de référence. |
| Facile à mettre en œuvre Les algorithmes de permutation sont simples et faciles à appliquer. |
Fuite contextuelle D’autres champs de données peuvent révéler l’identité même si les noms sont permutés. |
| Optionnellement réversible Avec une clé ou une table de correspondance, le processus peut être inversé si nécessaire. |
Gestion de la clé requise La réversibilité introduit un risque si la clé de permutation ou la correspondance n’est pas stockée en toute sécurité ou correctement supprimée. |
Bonnes pratiques pour la permutation de noms
Pour maximiser l’efficacité de la permutation de noms :
- Utilisez de grands ensembles de données : Plus l’ensemble de données est important, plus la permutation est efficace.
- Combinez les techniques : Utilisez la permutation de noms avec d’autres méthodes de masquage pour une meilleure protection.
- Application cohérente : Appliquez la permutation de manière cohérente sur toutes les données liées.
- Mises à jour régulières : Permutez périodiquement les données pour empêcher toute ingénierie inverse.
La permutation de noms dans la création de données de test
La permutation de noms est particulièrement utile dans la création de données de test. Elle permet aux développeurs et aux testeurs de travailler avec des données réalistes sans compromettre la vie privée. Voici pourquoi elle est cruciale :
- Tests réalistes : Les noms permutés préservent les caractéristiques des données réelles.
- Conformité à la vie privée : Elle aide à respecter les réglementations sur la protection des données.
- Développement simplifié : Les développeurs peuvent utiliser des données qui imitent étroitement les environnements de production.
Conclusion
La permutation de noms est une technique puissante de masquage des données. Elle offre un équilibre entre l’utilité des données et la protection de la vie privée. En implémentant la permutation de noms, les organisations peuvent créer des données de test réalistes tout en protégeant les informations sensibles. À mesure que les préoccupations concernant la confidentialité des données augmentent, des méthodes comme la permutation deviendront de plus en plus importantes dans la gestion des données.
Pour ceux qui recherchent des solutions avancées de masquage des données, DataSunrise offre des outils conviviaux et flexibles pour la sécurité des bases de données. Notre outil complet de masquage de données dynamique et statique comprend des capacités robustes de permutation et de chiffrement. Visitez le site de DataSunrise pour une démo en ligne et découvrez comment nos solutions peuvent améliorer vos stratégies de protection des données.
