Comment Auditer Databricks SQL
L’audit de Databricks SQL n’est pas un simple exercice de case à cocher ; par conséquent, apprendre comment auditer Databricks SQL correctement est essentiel dans des environnements lakehouse réels. Dans ces environnements, Databricks SQL devient souvent une plateforme analytique partagée par des dizaines d’équipes, des pipelines automatisés et des outils BI externes. En conséquence, les organisations doivent concevoir l’audit comme un processus continu plutôt qu’une configuration ponctuelle.
Ce guide explique comment auditer Databricks SQL correctement : en commençant par la visibilité native, en identifiant ses limites, puis en mettant en œuvre un workflow d’audit structuré et prêt pour l’investigation grâce à DataSunrise. L’accent est mis sur les décisions pratiques, les points de contrôle et la qualité des preuves plutôt que sur des définitions théoriques.
Ce que signifie l’audit dans Databricks SQL
Auditer Databricks SQL signifie conserver des preuves fiables et vérifiables de l’utilisation de l’entrepôt SQL. Cela inclut le suivi de qui a exécuté les requêtes, quelles opérations ont été réalisées, quand elles ont eu lieu, et si ces actions étaient conformes aux politiques internes et aux exigences réglementaires.
En pratique, l’audit doit répondre à des questions opérationnelles et judiciaires telles que :
- Qui a accédé aux tables sensibles et via quels outils ?
- Les opérations de modification des données étaient-elles attendues et autorisées ?
- Peut-on reconstruire l’ordre d’exécution des requêtes durant une enquête ?
- Les preuves d’audit sont-elles protégées contre la falsification et correctement conservées ?
Sans réponses claires à ces questions, les données d’audit ont peu de valeur pratique. Avec le temps, les équipes matures combinent cette approche avec la surveillance de l’activité des bases de données pour maintenir la cohérence des enquêtes et des revues de conformité à travers les environnements.
Étape 1 : Examiner les capacités d’audit natives de Databricks SQL
Databricks SQL fournit un historique natif des requêtes affichant les instructions exécutées avec les horodatages, la durée et le statut d’exécution. Les administrateurs utilisent souvent cette interface pour le dépannage à court terme et la visibilité opérationnelle.
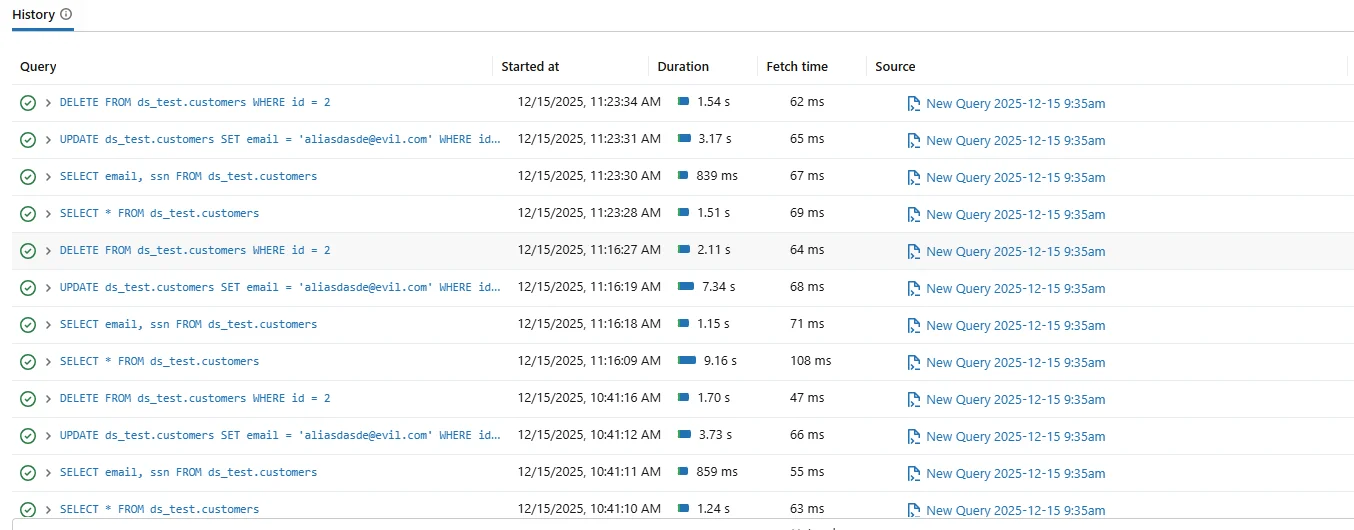
Historique natif des requêtes Databricks SQL utilisé pour un audit opérationnel basique.
Bien que l’historique natif des requêtes soit utile, il n’a pas été conçu pour des audits formels. La rétention est limitée, la corrélation des sessions est faible, et l’intégrité des preuves n’est pas garantie.
Pour prolonger la rétention, les équipes exportent souvent les journaux vers des plateformes externes telles que Azure Log Analytics ou Amazon CloudWatch. Cependant, ces systèmes demandent toujours un effort manuel important pour corréler les sessions et reconstituer les chronologies. Pour une collecte structurée des preuves, de nombreuses organisations s’appuient sur des journaux d’audit dédiés qui conservent des métadonnées cohérentes entre utilisateurs et charges de travail.
Étape 2 : Définir le périmètre d’audit avant de collecter les données
Une des erreurs d’audit les plus courantes est de tout capturer sans définir de périmètre. Un journal excessif crée du bruit et ralentit les enquêtes.
| Dimension de l’audit | Questions clés |
|---|---|
| Activité utilisateur | Quels utilisateurs et comptes de service ont exécuté des requêtes ? |
| Types de requêtes | Des instructions SELECT, UPDATE ou DELETE ont-elles été exécutées ? |
| Objets de données | Quels schémas et tables ont été consultés ? |
| Ordre d’exécution | Peut-on reconstruire les actions chronologiquement ? |
Étape 3 : Comprendre l’architecture de l’audit
Un audit efficace suit une architecture en couches. Les requêtes SQL proviennent d’utilisateurs, d’outils BI et d’applications, s’exécutent dans l’entrepôt Databricks SQL, puis génèrent des événements pertinents pour l’audit.

Architecture d’audit montrant la capture, la centralisation et l’analyse des activités Databricks SQL.
La décision de conception critique est le lieu de capture des événements. La journalisation native enregistre les événements localement, tandis que les plateformes d’audit centralisées capturent, normalisent et stockent les événements en temps réel. En pratique, les équipes combinent un stockage centralisé avec des contrôles de sécurité des bases de données pour réduire les lacunes d’audit et accélérer les enquêtes.
Étape 4 : Centraliser l’audit avec DataSunrise
DataSunrise audite Databricks SQL en capturant l’activité SQL en temps réel et en la stockant dans un référentiel d’audit centralisé. Plutôt que de s’appuyer sur des journaux fragmentés, il construit des enregistrements d’audit structurés enrichis du contexte de session.
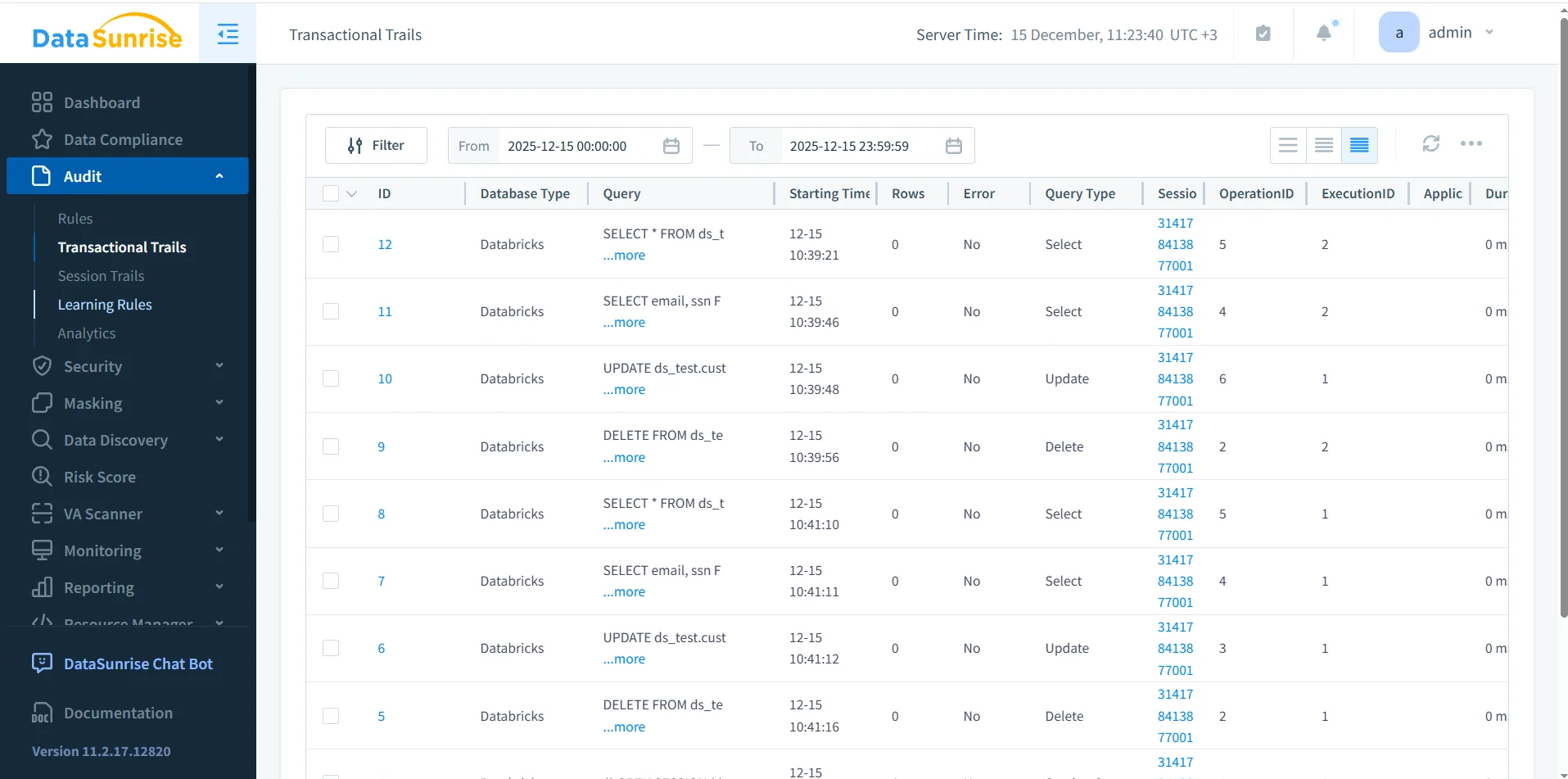
Pistes Transactionnelles DataSunrise montrant une vue centralisée des enregistrements d’audit Databricks SQL.
Chaque enregistrement d’audit comprend le texte SQL, le type de requête, l’identité de l’utilisateur, l’identifiant de session, le statut d’exécution et les informations temporelles. Cette structure supporte à la fois la surveillance en temps réel et l’investigation post-incident.
Étape 5 : Valider la couverture d’audit avec des requêtes réelles
Après avoir configuré l’audit, validez la couverture en exécutant des requêtes représentatives et en confirmant qu’elles apparaissent dans le système d’audit dans le bon ordre.
SELECT email, ssn FROM ds_test.customers; UPDATE ds_test.customers SET email = '[email protected]' WHERE id = 2; DELETE FROM ds_test.customers WHERE id = 2;
Une configuration d’audit fiable enregistre chaque instruction, préserve l’ordre d’exécution et associe toutes les opérations au même contexte de session.
Étape 6 : Scénarios courants d’échec d’audit
En pratique, les implémentations d’audit échouent souvent de manière prévisible. Un problème fréquent survient lorsque les journaux d’audit capturent les requêtes mais omettent le contexte de session, rendant impossible la reconstitution des workflows. Un autre échec apparaît lorsque les politiques de rétention suppriment les enregistrements avant que les audits aient lieu.
De plus, exporter des journaux sans normalisation crée des preuves incohérentes. Les enquêteurs peuvent avoir des difficultés à aligner les horodatages ou les identités des utilisateurs entre les systèmes.
Étape 7 : Rétention, intégrité et chaîne de possession
Les preuves d’audit ne sont utiles que si elles restent fiables. Les organisations doivent assurer que les enregistrements d’audit ne peuvent pas être modifiés et restent disponibles pendant la période de rétention requise.
DataSunrise impose un stockage centralisé, des contrôles d’accès et des politiques de rétention. En conséquence, les preuves d’audit maintiennent leur intégrité et soutiennent les exigences de chaîne de possession durant les enquêtes et les revues réglementaires. Pour un alignement plus large de la gouvernance, les équipes connectent souvent ce workflow à des programmes de conformité des données pour uniformiser les processus de rétention et de preuve.
Audit natif vs audit centralisé : différences pratiques
| Capacité | Databricks SQL natif | Audit DataSunrise |
|---|---|---|
| Rétention | Court terme | Long terme configurable |
| Corrélation des sessions | Minimale | Suivi complet des sessions |
| Qualité des preuves d’audit | Opérationnelle | Prête pour l’investigation |
| Rapports de conformité | Manuel | Structuré et automatisé |
Conclusion : Auditer Databricks SQL correctement
Auditer Databricks SQL demande plus que l’activation de l’historique des requêtes. Cela nécessite un périmètre clair, une capture fiable, un stockage centralisé, la préservation de l’ordre d’exécution et une conservation protégée.
En combinant la visibilité native de Databricks SQL avec un audit centralisé via DataSunrise, les organisations obtiennent des preuves d’audit qui soutiennent les enquêtes, les contrôles de conformité et la gouvernance à long terme.
Lorsqu’il est correctement mis en œuvre, l’audit de Databricks SQL devient un atout opérationnel plutôt qu’un fardeau de conformité.
