
Comment automatiser la conformité des données pour Apache Impala

Introduction
Apache Impala offre des analyses SQL haute performance et à faible latence pour les données stockées dans des environnements Hadoop. Cependant, garantir la conformité avec des règlements tels que GDPR, HIPAA, PCI DSS et SOX nécessite des outils d’automatisation robustes et des contrôles de sécurité. Sans outils adéquats pour automatiser la conformité des données, les organisations s’exposent à des risques importants, y compris des violations de données, des sanctions réglementaires et des échecs d’audit.
Ce guide explique comment automatiser la conformité dans Apache Impala en utilisant à la fois les fonctionnalités intégrées et des solutions d’entreprise telles que DataSunrise pour mettre en œuvre un contrôle d’accès complet, un audit, un masquage des données et des rapports de conformité.
Automatisation de la conformité avec les outils natifs d’Apache Impala
Impala inclut plusieurs fonctionnalités natives et intégrations avec l’écosystème Hadoop qui forment la base de l’automatisation de la conformité :
Étape 1 : Mettre en œuvre la classification des données basée sur les politiques
La classification des données est la pierre angulaire de toute stratégie de conformité, garantissant que les données sensibles sont correctement identifiées et protégées.
Intégration avec Apache Atlas
Impala peut s’intégrer avec Apache Atlas pour la gestion des métadonnées et la gouvernance des données :
<!-- atlas-application.properties -->
<property>
<name>atlas.hook.impala.enabled</name>
<value>true</value>
</property>
<property>
<name>atlas.cluster.name</name>
<value>ImpalaCluster</value>
</property>
Cette configuration permet l’étiquetage automatique et la classification des éléments de données sensibles dans les tables Impala, créant ainsi une base pour des contrôles de conformité basés sur des catégories de données.
Étape 2 : Appliquer les contrôles d’accès et les politiques de sécurité
Impala prend en charge le contrôle d’accès basé sur les rôles (RBAC) grâce à son intégration avec Apache Ranger :
SQL pour la mise en œuvre du RBAC
-- Créer un rôle pour les responsables de la conformité
CREATE ROLE compliance_officer;
-- Accorder un accès sélectif aux tables sensibles
GRANT SELECT ON DATABASE compliance_db TO ROLE compliance_officer;
GRANT SELECT ON TABLE customer_data(id, name, region) TO ROLE compliance_officer;
-- Assigner le rôle à des utilisateurs spécifiques
GRANT ROLE compliance_officer TO USER auditor1;
Cette approche garantit que seuls les utilisateurs autorisés peuvent accéder aux données sensibles, avec des autorisations pouvant être contrôlées de manière granulaire au niveau de la base de données, de la table ou de la colonne.
Étape 3 : Automatiser la journalisation et la surveillance des audits
Des traces d’audit complètes sont essentielles pour la vérification de la conformité. Activez la journalisation d’audit native d’Impala :
# Configuration du démon Impala
--audit_event_log_dir=/var/log/impala/audit
--audit_log_level=full
--audit_log_format=json
Ces paramètres garantissent que toutes les opérations de la base de données sont enregistrées, y compris :
- Les détails d’exécution des requêtes
- Les événements d’authentification
- Les opérations sur les métadonnées
- Les modèles d’accès aux données
Les journaux d’audit peuvent être analysés pour vérifier la conformité aux exigences réglementaires et détecter d’éventuels incidents de sécurité.
Étape 4 : Automatiser la génération de rapports de conformité
La plupart des cadres réglementaires exigent des rapports de conformité réguliers. Bien qu’Impala n’inclue pas d’outils de génération de rapports intégrés, vous pouvez mettre en œuvre des solutions automatisées :
Scripts de reporting personnalisés
#!/usr/bin/python
import json
import datetime
# Analyse des journaux d'audit d'Impala
def generate_compliance_report():
with open('/var/log/impala/audit/impala_audit_log.json', 'r') as f:
logs = [json.loads(line) for line in f]
# Filtrer pour l'accès aux données sensibles
sensitive_access = [log for log in logs if 'pii_data' in log['query'].lower()]
# Générer le rapport
report = {
'date': datetime.datetime.now().isoformat(),
'sensitive_data_access_count': len(sensitive_access),
'access_by_user': {}
}
# Enregistrer dans un fichier
with open(f'compliance_report_{datetime.date.today()}.json', 'w') as f:
json.dump(report, f, indent=2)
# Exécuter quotidiennement
if __name__ == "__main__":
generate_compliance_report()
Cet exemple de script démontre comment les organisations peuvent développer des solutions de reporting personnalisées basées sur les journaux d’audit d’Impala.
Étape 5 : Mettre en œuvre le masquage des données pour la conformité
Le masquage des données est crucial pour protéger les informations sensibles tout en conservant leur utilité pour l’analyse :
Création de vues masquées dans Impala
-- Créer une vue avec des données sensibles masquées
CREATE VIEW masked_customer_data AS
SELECT
customer_id,
REGEXP_REPLACE(email, '(.{2})(.*)(@.*)', '$1***$3') AS email,
CONCAT(SUBSTR(phone_number, 1, 3), '-XXX-XXXX') AS phone,
CASE
WHEN credit_score < 600 THEN 'Below 600'
WHEN credit_score BETWEEN 600 AND 750 THEN '600-750'
ELSE 'Above 750'
END AS credit_range
FROM customer_data;
Cette approche permet aux utilisateurs non privilégiés d’accéder aux données pour des analyses tout en masquant les valeurs sensibles réelles, aidant ainsi à maintenir la conformité avec les règlements sur la confidentialité des données.
Comment automatiser la conformité des données pour Apache Impala en 3 étapes faciles avec DataSunrise
Bien que les capacités natives d’Impala fournissent une base pour la conformité, DataSunrise offre une approche complète et automatisée qui simplifie la mise en œuvre et la gestion.
Étape 1 : Connectez votre base de données Impala
Commencez par connecter DataSunrise à votre environnement Impala. La plateforme prend en charge divers modèles de déploiement, y compris le cloud, sur site et les architectures hybrides.

L’assistant de connexion vous guide pour spécifier l’hôte, le port, les méthodes d’authentification et les détails de la base de données.
Étape 2 : Configurer les paramètres de conformité
Depuis le tableau de bord du Gestionnaire de conformité, sélectionnez votre connexion à la base de données Impala, choisissez les règlements de conformité pertinents (GDPR, HIPAA, PCI DSS, SOX) et définissez votre planning de rapports préféré.
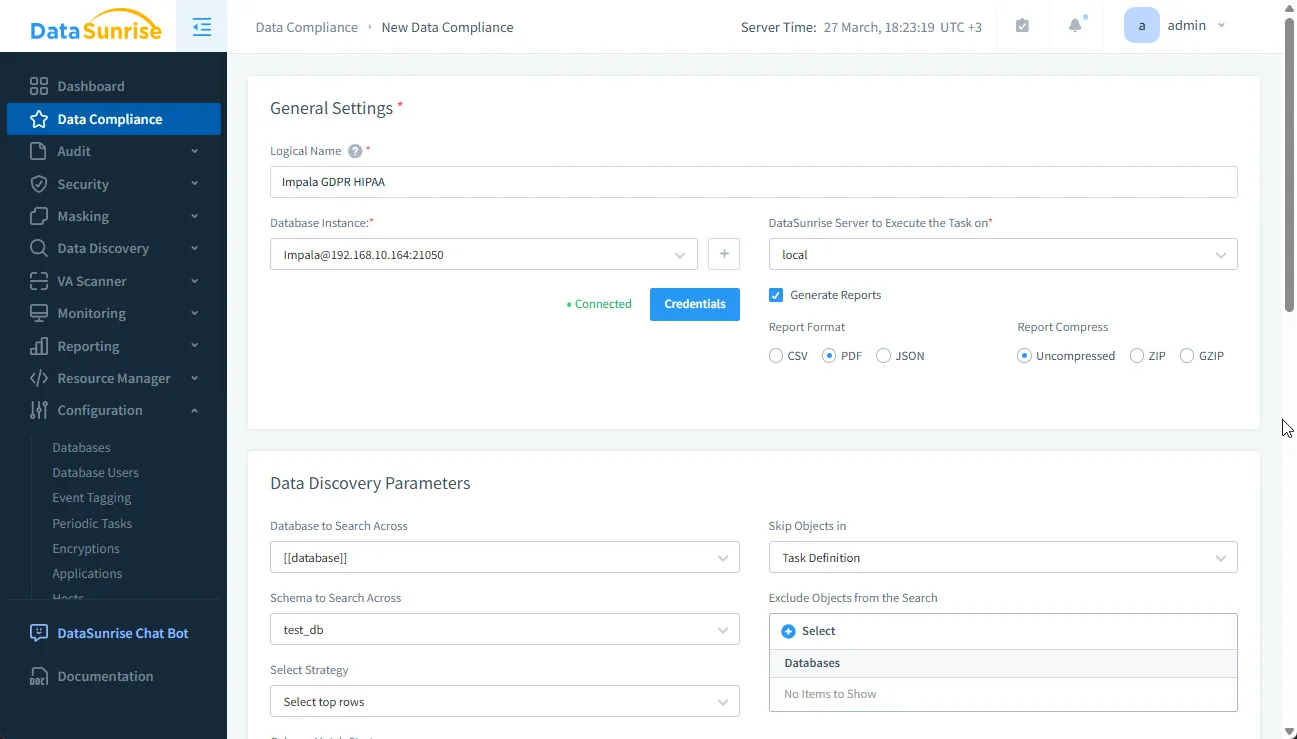
La plateforme vous permet de spécifier quels types de données sensibles scanner, notamment les données personnelles (PII), les informations financières et les données de santé.
Étape 3 : Cliquez sur Enregistrer – DataSunrise s’occupe du reste
Une fois configuré, DataSunrise :
- Exécute une découverte intelligente des données pour identifier et classer les données sensibles dans les tables Impala
- Applique des règles d’audit exhaustives pour une visibilité complète sur l’activité de la base de données
- Applique des politiques de sécurité pour prévenir les violations de la conformité
- Déploie le masquage dynamique des données afin de protéger les informations personnelles identifiables
- Génère des rapports de conformité détaillés selon votre planning
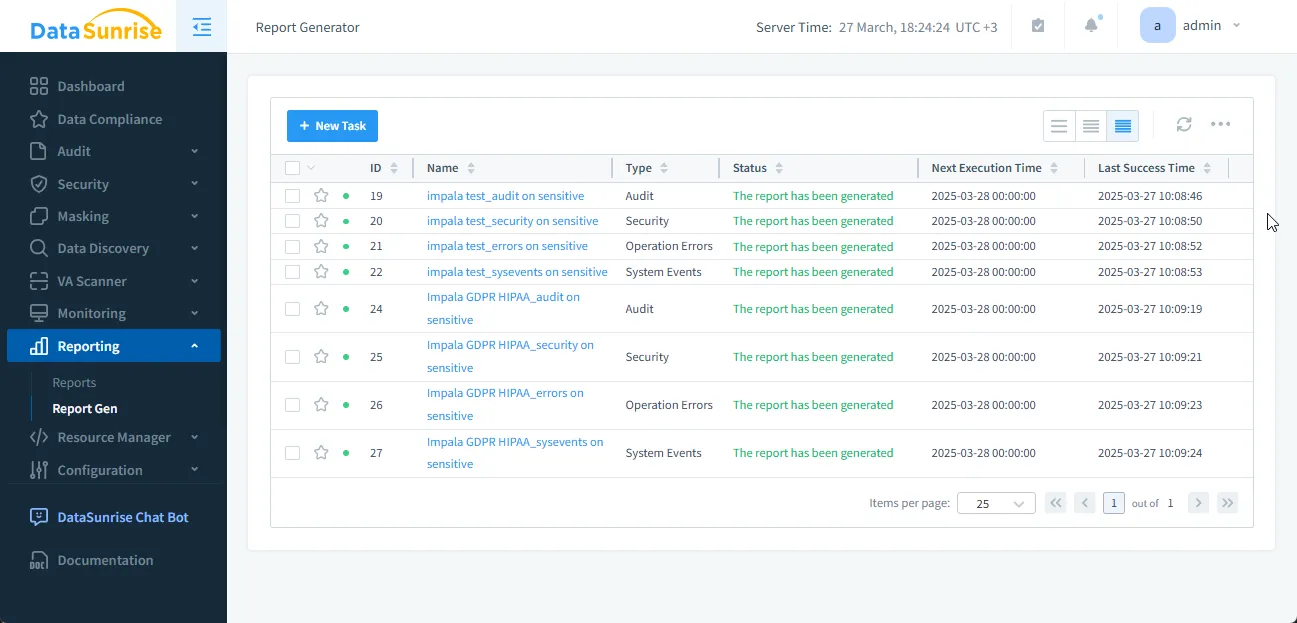
Cette mise en œuvre sans intervention transforme la conformité d’un processus manuel et coûteux en un flux de travail automatisé et rationalisé.
Caractéristiques clés de DataSunrise pour Apache Impala
DataSunrise améliore les capacités de sécurité d’Impala grâce à une automatisation et une surveillance avancées :
- Audit des données automatisé – Enregistre toutes les activités de la base de données dans une piste d’audit inviolable
- Contrôle d’accès en temps réel – Applique des politiques de sécurité dynamiques basées sur l’utilisateur, le temps, la localisation et le contenu des données
- Masquage dynamique des données – Protège les informations sensibles sans modifier les données originales
- Détection des menaces – Identifie les tentatives d’injection SQL et les motifs de requêtes anormaux
- Rapports de conformité automatisés – Génère des rapports préconçus pour le GDPR, HIPAA, PCI DSS et SOX
- Intégration d’entreprise – Se connecte avec des solutions SIEM et des plateformes de sécurité via des API standardisées
Conclusion
L’automatisation de la conformité des données dans Apache Impala nécessite une combinaison des fonctionnalités de sécurité natives et des outils d’automatisation de niveau entreprise. Bien qu’Impala fournisse des capacités essentielles telles que la journalisation d’audit et les contrôles d’accès, ces fonctionnalités natives manquent souvent de l’automatisation complète requise pour des environnements de conformité complexes.
DataSunrise améliore les capacités de conformité d’Impala avec :
- L’application de politiques de sécurité en temps réel
- Une journalisation d’audit avancée et une analyse comportementale
- La génération automatisée de rapports de conformité et la documentation
- Le masquage dynamique des données et les contrôles d’accès
Pour les organisations souhaitant rationaliser la conformité d’Impala et réduire les risques de sécurité, DataSunrise offre une solution complète qui transforme les processus de conformité manuels en flux de travail automatisés.
Planifiez une démonstration en direct pour découvrir comment DataSunrise peut automatiser la conformité pour votre environnement Apache Impala.
