Trace d’Audit Amazon OpenSearch
La trace d’audit Amazon OpenSearch devient pertinente lorsqu’un cluster n’est plus utilisé uniquement pour la journalisation, mais sert également de source de données métier et de sécurité. Dans un environnement de production typique, le même domaine OpenSearch reçoit des requêtes provenant des services applicatifs, des tableaux de bord BI, des équipes de support et des processus automatisés. Ces requêtes touchent souvent les mêmes indices et APIs, bien que les utilisateurs et les systèmes derrière eux aient des rôles et intentions différents.
Si les équipes ne conservent pas de trace d’audit, les journaux de service dispersent les activités et ne fournissent pas une image cohérente. Lors d’un incident, les équipes doivent reconstruire les événements de manière indirecte : qui a accédé à un index, quel point de terminaison a-t-il utilisé, s’il a modifié des données et ce qui s’est passé durant la même session. Lorsque OpenSearch stocke des identifiants clients, des journaux d’accès ou des événements de sécurité, cette méthode devient rapidement peu fiable.
Pourquoi une trace d’audit est importante pour Amazon OpenSearch
Amazon OpenSearch n’est pas une base de données relationnelle, mais il stocke des données persistantes et exécute des opérations structurées sur ces données. Les clients créent des indices, mettent à jour des documents, effectuent des recherches et récupèrent des résultats qui peuvent inclure des champs sensibles. Du point de vue de la gouvernance, ces actions relèvent des mêmes exigences d’audit appliquées aux bases de données.
Plusieurs facteurs rendent l’audit OpenSearch différent de l’audit des systèmes basés sur SQL :
-
Accès aux données basé sur l’API
La majorité des opérations OpenSearch arrivent sous forme de requêtes HTTP avec des charges JSON. La gestion des indices, les mises à jour de documents et les opérations de recherche s’appuient sur des points de terminaison REST plutôt que sur des requêtes SQL. Une trace d’audit qui ne comprend que le SQL manquera des activités critiques liées au plan de contrôle et au plan de données. -
De nombreux consommateurs dans un même cluster
Un cluster OpenSearch unique prend souvent en charge des charges de production et des accès temporaires. Sans trace d’audit, les équipes ont du mal à séparer le trafic applicatif normal des travaux mal configurés, des enquêtes de support ou des scans d’indices. -
Les opérations par lots modifient de grands volumes
Les opérations en masse d’indexation et de mise à jour peuvent modifier de nombreux documents en un seul appel. Lorsqu’un problème survient, les équipes ont besoin du contexte de session de la requête, pas seulement d’une confirmation que la requête a eu lieu. -
Les données réglementées se retrouvent dans les indices
Dès que les indices contiennent des identifiants, des adresses IP, des dossiers clients ou des incidents de sécurité, l’historique d’accès et de modification relève des exigences d’audit GDPR, HIPAA, PCI DSS et SOX.
Architecture du journal d’audit Amazon OpenSearch
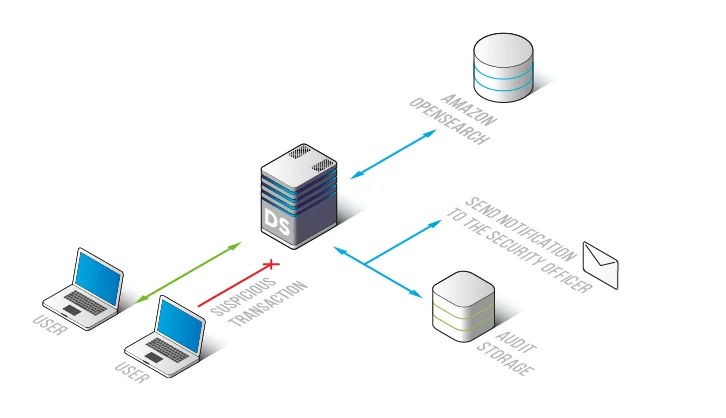
DataSunrise implémente un journal d’audit Amazon OpenSearch en plaçant une couche de contrôle transparente entre les applications clientes et le service OpenSearch. Les requêtes transitent par la couche DataSunrise où le système évalue les opérations et enregistre les événements d’audit selon les règles définies. Ce design évite toute modification des indices OpenSearch ou du code applicatif.
Cette approche basée sur le trafic s’intègre aux workflows plus larges de monitoring de l’activité des bases de données et permet aux équipes de revoir les activités des utilisateurs, des points d’extrémité, des indices et sur des plages temporelles.
Chaque requête devient une entrée d’audit que les équipes peuvent filtrer par utilisateur, index, type d’action, horodatage et contexte de règle. Ce filtrage rend le journal d’audit pratique pour l’investigation des incidents et la vérification de conformité.
Définition des règles de journalisation d’audit pour Amazon OpenSearch
Un journal d’audit n’est efficace que lorsque les équipes définissent des règles claires sur ce que le système enregistre. DataSunrise utilise un audit fondé sur des règles pour suivre l’activité OpenSearch et la stocker dans un format cohérent.
Les paramètres typiques des règles incluent l’index ou le motif d’index, la méthode HTTP, l’utilisateur ou le compte de service, et le réseau source. Les règles peuvent également capturer le contexte de session et les résultats d’exécution.
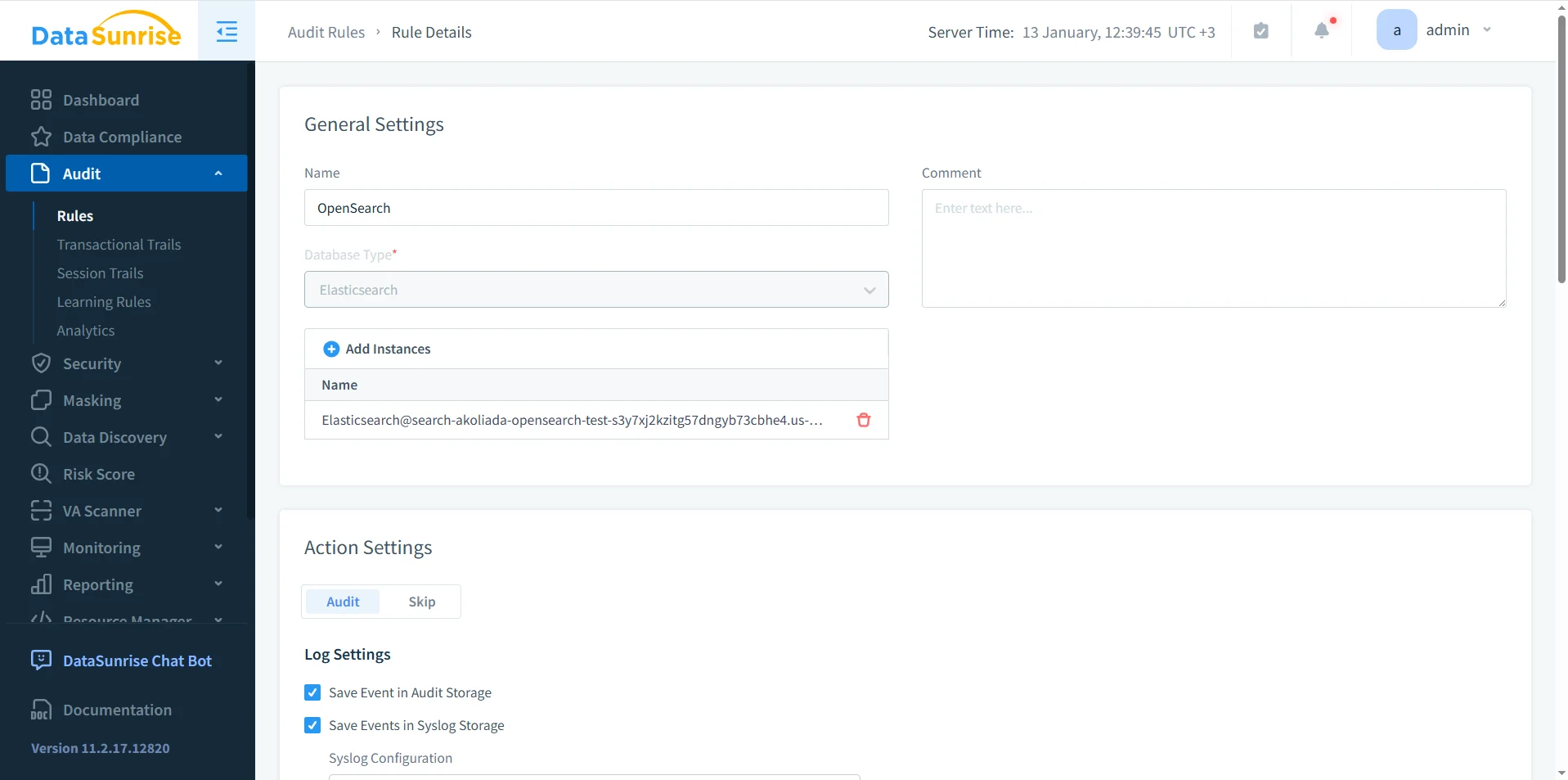
La priorisation des règles permet d’appliquer un audit plus strict aux indices sensibles tout en réduisant le bruit des trafics opérationnels à faible risque. Dans les environnements OpenSearch à fort volume, cette distinction détermine si les données d’audit restent exploitables.
Journal d’audit transactionnel et contexte de session
Après activation des règles d’audit, DataSunrise enregistre l’activité dans des traces d’audit transactionnelles. Au lieu de traiter chaque requête comme un événement isolé, le système regroupe les actions liées en sessions et transactions.
Ce regroupement change la manière dont les équipes enquêtent sur les incidents. Elles peuvent revoir des sessions qui ont exécuté plusieurs recherches, suivies d’actualisations en masse, avant de se clôturer. Cette méthode offre une séquence claire d’actions plutôt que de se baser uniquement sur les horodatages.
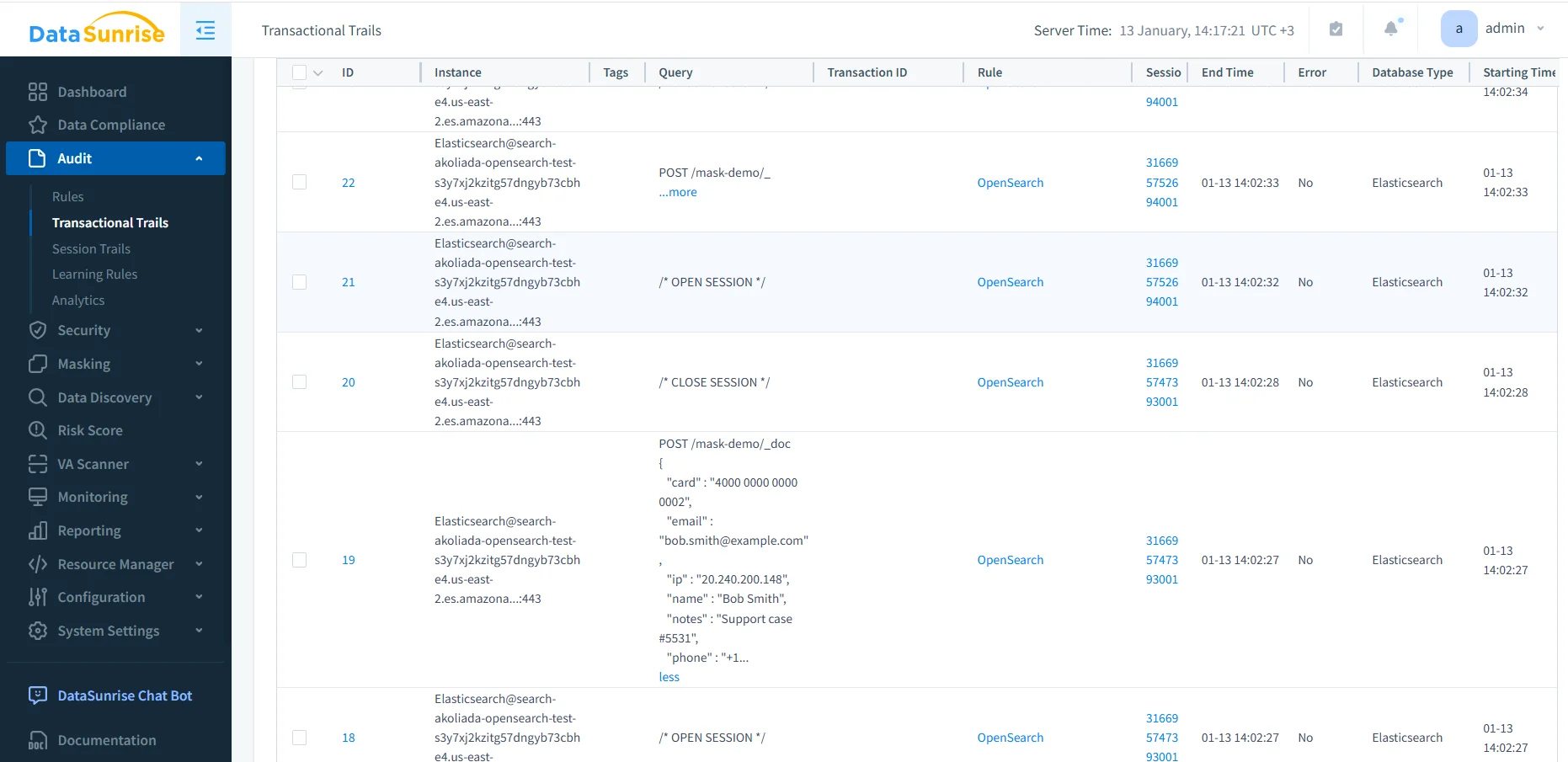
Chaque entrée du journal d’audit inclut généralement :
- Point d’extrémité OpenSearch et nom de l’index
- Méthode HTTP et type de requête
- Identifiants de session et de transaction
- Adresse IP source et contexte utilisateur
- Horodatages, temps d’exécution et état d’erreur
Ce niveau de détail supporte la réponse aux incidents, les enquêtes internes et la collecte de preuves pour la conformité.
Contenu collecté à l’aide du journal d’audit Amazon OpenSearch
La couverture du journal d’audit Amazon OpenSearch comprend la création et la suppression d’indices, les modifications de configuration, les opérations d’insertion, de mise à jour et de suppression des documents, les requêtes de recherche et d’agrégation, les requêtes en masse, les événements d’ouverture et de fermeture de sessions, ainsi que les opérations échouées ou rejetées.
Les équipes peuvent stocker les données du journal d’audit localement ou les transférer vers des systèmes externes et les intégrer dans des workflows centralisés de sécurité des données.
Journal d’audit et contrôles de sécurité
Le journal d’audit agit également comme une surface de contrôle. En observant les points d’extrémité utilisés par les identités, les équipes peuvent détecter des schémas tels que des scans répétés, des exports non intentionnels ou des comptes de service invoquant des points d’administration depuis de nouveaux segments réseau.
DataSunrise peut combiner les journaux d’audit avec des règles de sécurité et une détection basée sur le comportement pour signaler précocement les activités OpenSearch suspectes et les diriger vers des workflows d’enquête établis.
Adaptation à la conformité et preuves d’audit
Si des données réglementées sont indexées, les organisations doivent produire des preuves montrant un accès et une modification traçables. DataSunrise corrèle les enregistrements du journal d’audit avec les workflows de conformité pour le RGPD, HIPAA, PCI DSS et SOX. Les équipes peuvent générer des rapports via la génération de rapports lorsqu’elles ont besoin de preuves d’audit.
| Réglementation | Exigence de trace d’audit | Support DataSunrise |
|---|---|---|
| RGPD | Suivi des accès aux données personnelles | Traces d’audit consultables avec contrôles de rétention |
| HIPAA | Surveillance des accès aux données de santé protégées | Entrées du journal d’audit basées sur les sessions |
| PCI DSS | Journalisation des accès aux données de paiement | Stockage d’audit immuable et génération de rapports |
| SOX | Responsabilisation des actions administratives | Suivi des modifications et rapport de conformité |
Les workflows automatisés via le Compliance Manager réduisent l’effort manuel lorsque les équipes ont besoin de preuves d’audit répétables.
