Masquage des données dans Vertica
Le masquage des données dans Vertica consiste à permettre aux analystes de travailler avec de vraies structures de données tout en cachant les valeurs qui ne doivent jamais être exposées en clair. Vertica est une base de données analytique haute performance, fréquemment utilisée pour les tableaux de bord BI, l’analyse client, les magasins de fonctionnalités ML et l’exploration ad hoc sur de larges ensembles de données colonneaires. Cette flexibilité est précieuse pour l’entreprise, mais signifie également que des champs réglementés tels que les numéros de carte, les identifiants nationaux et les attributs médicaux peuvent facilement fuiter dans des requêtes, exportations ou ensembles d’entraînement si aucune couche de protection n’est appliquée.
Tenter de résoudre ce problème uniquement avec des permissions manuelles, des tables copiées ou des vues SQL écrites à la main devient rapidement pénible. Les schémas changent, de nouvelles projections apparaissent, les tâches ETL créent des tables dérivées, et soudainement personne n’est sûr de la colonne réellement sûre à exposer. Au lieu de traquer chaque requête, les équipes ont besoin d’une couche de masquage qui fonctionne automatiquement pour chaque charge de travail Vertica.
Le masquage des données avec DataSunrise offre cette couche aux utilisateurs Vertica. DataSunrise se place entre Vertica et les outils clients, détecte les champs sensibles, et réécrit les résultats des requêtes à la volée afin que les valeurs confidentielles soient cachées, anonymisées par jetons, ou partiellement révélées selon la politique. Vertica continue à faire ce qu’il fait de mieux — l’analytique rapide — tandis que la logique de masquage, les pistes d’audit et les règles de conformité résident dans un plan de contrôle séparé et dédié.
Pourquoi Vertica nécessite une couche de masquage dédiée
L’architecture de Vertica le rend à la fois puissant et complexe. Les données sont stockées dans des conteneurs ROS colonneaires, les modifications récentes résident dans le WOS, et les projections offrent plusieurs agencements physiques pour la même table logique, comme décrit dans la documentation d’architecture Vertica. Ce design est idéal pour la performance, mais complique des questions telles que « Où exactement résident les numéros de carte client ? » ou « Quelles charges de travail manipulent des informations de santé protégées (PHI) aujourd’hui ? »
Les points douloureux courants incluent :
- Tables analytiques larges regroupant des dizaines d’attributs (y compris des données personnelles identifiables et des informations de santé protégées) en une seule structure.
- Multiples projections qui répliquent physiquement des colonnes sensibles à travers le cluster.
- Clusters partagés utilisés simultanément par BI, ETL, notebooks, et frameworks ML.
- SQL ad hoc émis par des utilisateurs avancés et data scientists, contournant les couches de reporting organisées.
- Logs dispersés qui compliquent la reconstitution de qui a vu quoi et quand.
Le contrôle d’accès basé sur les rôles (RBAC) de Vertica gère qui peut se connecter et quels objets ils peuvent interroger. Cependant, il ne comprend pas si une requête donnée exporte des numéros de carte, joint des données RH et CRM de manière non sécurisée, ou remplit un environnement non production avec des données client réelles. Pour combler ces lacunes, les organisations déploient un moteur externe de masquage et de politique qui comprend la sensibilité des colonnes et le contexte utilisateur.
Comment DataSunrise assure le masquage des données dans Vertica
DataSunrise agit comme un proxy transparent en amont de Vertica. Les outils BI, clients SQL, planificateurs, et plateformes de science des données se connectent à DataSunrise au lieu de se connecter directement à Vertica. Pour chaque requête, DataSunrise analyse le SQL, vérifie quelles colonnes sont sensibles, évalue les politiques de masquage, puis soit laisse passer la requête telle quelle, soit réécrit l’ensemble des résultats pour que les valeurs confidentielles ne quittent jamais la base en clair.
Sous le capot, ce moteur de masquage combine plusieurs capacités :
- Découverte des données sensibles pour identifier les colonnes contenant des PII, PHI ou identifiants financiers.
- Masquage dynamique des données qui modifie les résultats en temps réel selon l’utilisateur, l’application ou le contexte réseau.
- Masquage statique des données pour générer des ensembles de données sûrs en environnement non production.
- Journalisation d’audit qui enregistre chaque requête masquée comme preuve de conformité.
Les captures d’écran ci-dessous expliquent une configuration type de masquage dans Vertica : définition d’une règle de masquage, sélection des colonnes à protéger, et vérification que les requêtes sont masquées et auditées correctement.
Définir une règle de masquage Vertica
La première étape consiste à créer une règle de masquage et à la rattacher à l’instance Vertica appropriée. Dans l’exemple ci-dessous, la règle nommée Vertica_Masking cible une base de données Vertica accessible sur le port 5433. La règle précise également ce qui doit se passer lorsqu’un masquage est déclenché — ici, chaque événement de masquage est enregistré à la fois dans le magasin d’audit DataSunrise et dans un syslog externe, ce qui facilite l’intégration avec des plateformes SIEM.
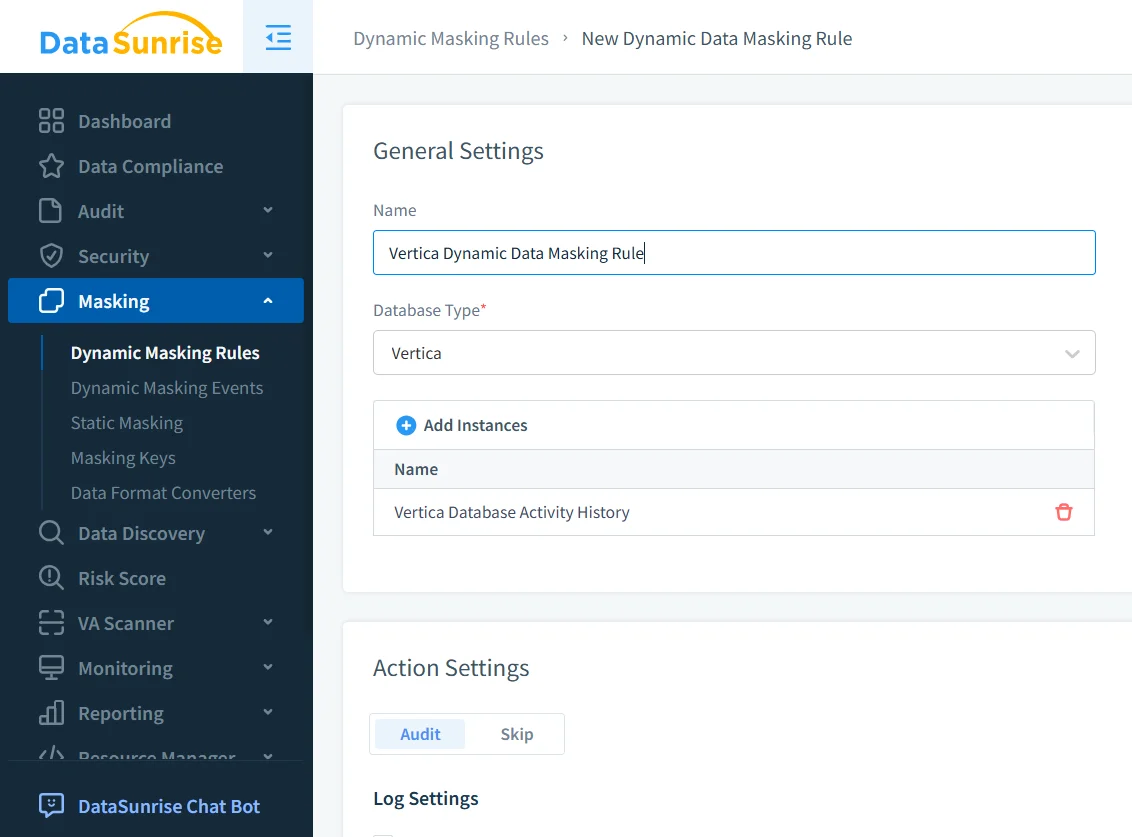
À ce stade, vous définissez le comportement principal :
- Les instances Vertica concernées par la règle.
- Si les événements de masquage doivent être audités, ignorés ou transférés vers des systèmes externes.
- Éventuels filtres globaux, comme limiter la règle aux environnements de production.
Cette séparation permet de conserver une politique logique « Vertica_Masking » même si vous ajoutez ultérieurement d’autres nœuds ou clusters. La logique de masquage réside dans DataSunrise, pas dans les schémas Vertica.
Sélection des colonnes et conditions de masquage
Une fois la règle créée, vous choisissez quelles colonnes Vertica masquer et dans quelles conditions. DataSunrise peut importer directement les listes de colonnes à partir des résultats de découverte pour que les administrateurs n’aient pas à les maintenir manuellement.
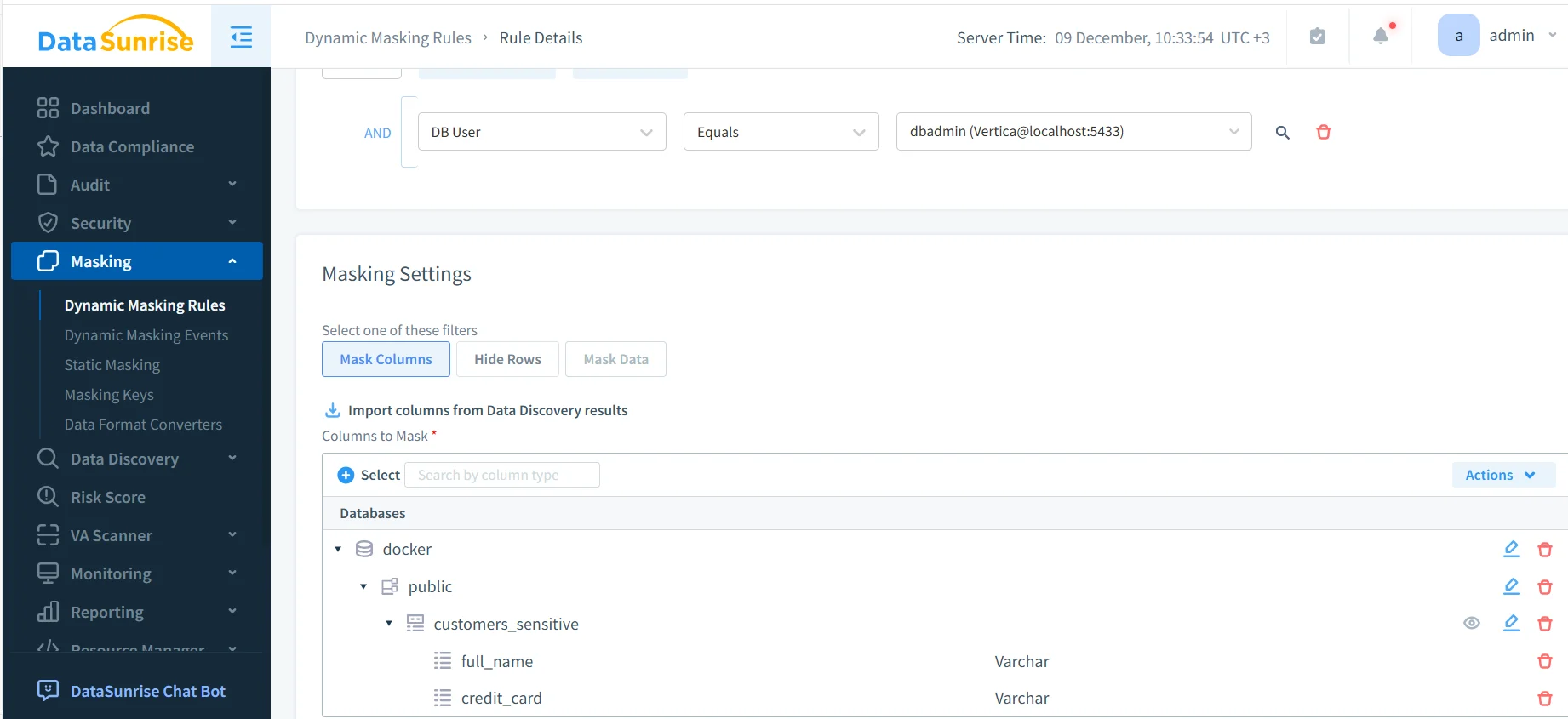
Les fonctions de masquage peuvent être personnalisées par colonne. Les numéros de carte peuvent n’afficher que les quatre derniers chiffres, les numéros de téléphone peuvent supprimer l’indicatif pays, et les noms peuvent être entièrement remplacés ou réduits aux initiales. Le comportement exact dépend des politiques internes de sécurité et des profils de masquage définis dans DataSunrise.
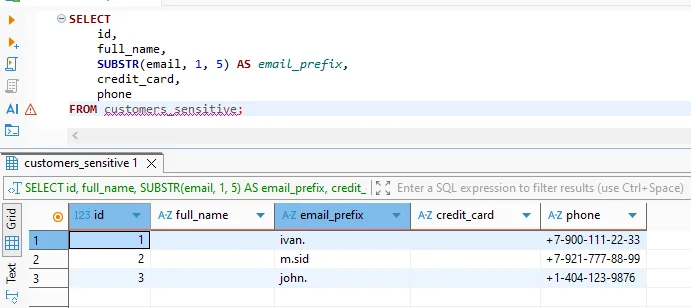
Une requête typique émise depuis un client SQL ou un notebook pourrait ressembler à ceci :
SELECT
id,
full_name,
SUBSTR(email, 1, 5) AS email_prefix,
credit_card,
phone
FROM customers_sensitive;
Sans masquage, cette requête renverrait les vrais noms des clients, numéros de carte et détails téléphoniques. Avec la règle activée, les utilisateurs non privilégiés voient des valeurs pseudonymisées tandis que le reste des résultats reste intact.
Audit des requêtes masquées dans Vertica
Le masquage seul ne suffit pas pour la conformité réglementaire. Les organisations doivent aussi prouver que le masquage a été appliqué de façon cohérente. DataSunrise enregistre chaque requête qui a déclenché un masquage, avec des informations sur l’utilisateur, l’application, le nom de la règle, et la durée d’exécution. Ces enregistrements servent aux audits sous des réglementations telles que le RGPD, HIPAA, et SOX.
Depuis la console d’audit, vous pouvez :
- Filtrer par règle Vertica, utilisateur, ou application pour enquêter sur des incidents.
- Exporter les journaux vers des plateformes SIEM ou GRC.
- Corréler les événements de masquage avec les alertes de Surveillance de l’activité base de données.
Parce que toutes les requêtes transitent par la même passerelle, les équipes conformité bénéficient d’une piste d’audit unique et normalisée au lieu de devoir reconstituer plusieurs tables système Vertica.
Scénarios courants de masquage avec Vertica
Le masquage des données dans Vertica apparaît dans plusieurs scénarios opérationnels et analytiques. Le tableau ci-dessous résume les cas d’usage fréquents et la manière dont les organisations appliquent typiquement les contrôles de masquage DataSunrise.
| Scénario | Risques | Approche de masquage |
|---|---|---|
| Tableaux de bord BI et analyses ad hoc | Exposition des données personnelles dans les rapports et exports | Masquage dynamique basé sur les rôles utilisateur et comptes de service BI |
| Science des données et notebooks | Utilisation de données clients réelles lors de l’exploration | Masquage partiel ou total pour les environnements non production et les rôles analystes |
| ETL et pipelines de données | Propagation des données sensibles vers les systèmes en aval | Masquage appliqué au moment de la requête avant que les données ne quittent Vertica |
| Magasins de fonctionnalités ML et entraînement de modèles | Fuite d’identifiants dans les ensembles de données d’entraînement | Pseudonymisation et tokenisation via des règles de masquage dynamiques |
| Audits réglementaires et enquêtes | Incapacité à prouver le respect des protections des données | Résultats de requêtes masquées combinés avec des pistes d’audit centralisées |
Conclusion
Bien fait, le masquage des données dans Vertica permet aux organisations de continuer à utiliser la plateforme comme moteur analytique à haute vitesse tout en réduisant considérablement le risque d’exposition d’informations sensibles. En déléguant la logique de masquage, la découverte et l’audit à DataSunrise, les équipes remplacent des solutions manuelles fragiles par une protection cohérente et automatisée.
Que ce soit pour soutenir le self-service BI, alimenter les charges ML, ou se préparer aux audits réglementaires, une passerelle de masquage dédiée offre à Vertica les garde-fous nécessaires — sans ralentir l’accès aux données.
Protégez vos données avec DataSunrise
Sécurisez vos données à chaque niveau avec DataSunrise. Détectez les menaces en temps réel grâce à la surveillance des activités, au masquage des données et au pare-feu de base de données. Appliquez la conformité des données, découvrez les données sensibles et protégez les charges de travail via plus de 50 intégrations supportées pour le cloud, sur site et les systèmes de données basés sur l'IA.
Commencez à protéger vos données critiques dès aujourd’hui
Demander une démo Télécharger maintenant