Masquage Statique des Données dans Vertica
Le masquage statique des données dans Vertica joue un rôle crucial dans la protection des données analytiques sensibles utilisées pour le reporting haute performance, la science des données et les charges analytiques à grande échelle. Les environnements Vertica s’appuient fréquemment sur des ensembles de données en production contenant des informations personnellement identifiables, des dossiers financiers et d’autres types de données réglementées. Lorsque les équipes copient ces données en dehors de systèmes de production strictement contrôlés, le profil global des risques augmente immédiatement.
Cette approche traite l’exposition en transformant de façon permanente les valeurs sensibles avant que les équipes ne réutilisent les données pour le développement, les tests, l’analyse ou les flux de travail de partage. Contrairement aux contrôles en temps réel, le masquage irréversible élimine totalement les valeurs d’origine, garantissant que les informations sensibles ne quittent jamais les limites protégées.
Cet article explique comment le masquage irréversible s’applique aux charges de travail Vertica, où les techniques natives basées sur SQL montrent leurs limites, et comment DataSunrise offre des contrôles de masquage centralisés et auditables à grande échelle.
Pourquoi le Masquage des Données est Important dans l’Analyse Vertica
Les déploiements Vertica prennent généralement en charge plusieurs consommateurs en aval, notamment les outils BI, les data scientists, les sous-traitants externes et les pipelines automatisés. Même lorsque les administrateurs configurent correctement les contrôles d’accès, la copie des données analytiques brutes vers des systèmes hors production introduit des risques d’exposition inévitables.
Le masquage irréversible atténue ces risques en garantissant que les ensembles de données exportés ou clonés ne contiennent aucune valeur sensible réelle. Les environnements réglementés par le RGPD, HIPAA ou PCI DSS exigent souvent une transformation permanente comme mesure de conformité et non comme simple recommandation.
Vertica se concentre sur la performance analytique, et non sur la logique de transformation au niveau des lignes. Par conséquent, les approches natives reposent généralement sur des scripts SQL personnalisés, des réécritures manuelles et des processus opérationnels fragiles.
Techniques Natives de Transformation des Données et Leurs Limites
Vertica ne fournit pas de primitives intégrées pour le masquage irréversible. Les équipes s’appuient habituellement sur des mises à jour SQL ou des pipelines d’export pour remplacer manuellement les valeurs sensibles.
Les approches natives courantes comprennent :
- La mise à jour des colonnes avec des valeurs transformées via des instructions
UPDATE - La création de copies anonymisées des tables pour un usage hors production
- L’application de fonctions irréversibles de hachage ou de substitution de chaînes
Bien que ces techniques fonctionnent dans des environnements de petite taille, elles introduisent des problèmes opérationnels récurrents :
- Absence de visibilité centralisée sur les colonnes transformées
- Absence de politiques réutilisables à travers les schémas ou les environnements
- Absence de trace d’audit indiquant quand les transformations ont eu lieu ou qui les a initiées
- Forte charge opérationnelle lors des modifications de schéma
À grande échelle, les flux de travail de transformation manuelle deviennent difficiles à contrôler et encore plus compliqués à auditer.
Comment DataSunrise Applique le Masquage Irréversible pour Vertica
DataSunrise ajoute une couche de contrôle externe qui applique des transformations permanentes sans modifier les schémas Vertica ni la logique applicative. Les administrateurs définissent des règles de masquage de manière centralisée et les appliquent de façon cohérente lors de flux de travail contrôlés tels que la copie, le clonage ou l’export de données.
Ce modèle aligne la transformation des données avec des stratégies plus larges de sécurité des données et de sécurité des bases de données.
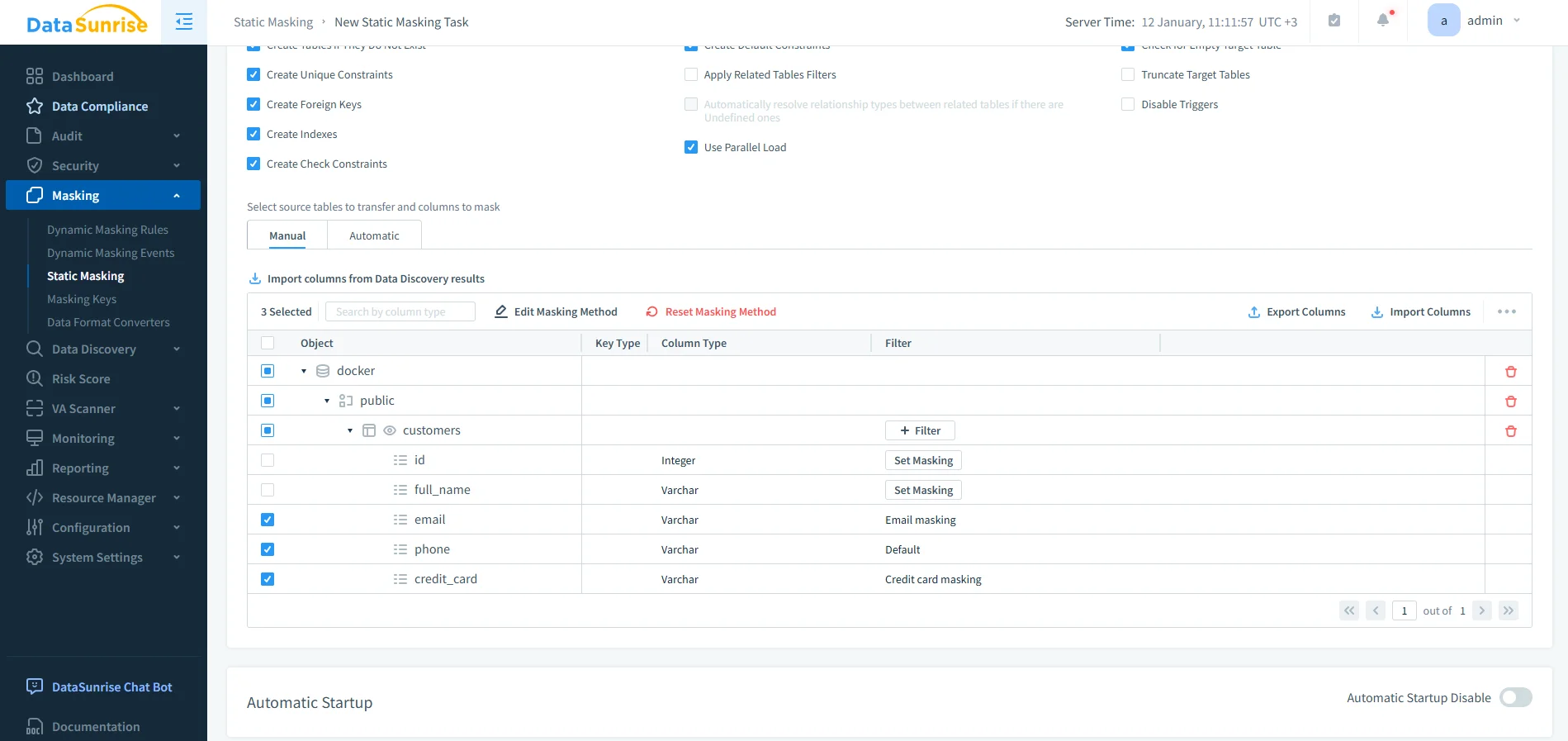
Identification des Colonnes Basée sur les Politiques
Au lieu de sélectionner manuellement des champs individuels, DataSunrise s’intègre à la découverte de données pour identifier automatiquement les colonnes sensibles dans Vertica. Après classification, les règles de transformation s’appliquent de façon cohérente à travers les schémas.
Cette approche supprime la dépendance aux conventions de nommage et réduit le risque de laisser des colonnes nouvellement introduites non protégées.
Transformations Préservant le Format et Synthétiques
Les transformations permanentes supportent plusieurs méthodes selon le type de données et les exigences analytiques :
- Substitution d’emails avec des adresses synthétiques valides
- Tokenisation des numéros de téléphone
- Hachage irréversible pour les identifiants
- Masquage des cartes de crédit avec préservation de la longueur et de la structure
Ces transformations conservent l’utilisabilité analytique tout en éliminant l’exposition des données réelles.
Exécution Contrôlée et Sécurité des Performances
Les tâches de transformation s’exécutent comme des opérations contrôlées avec un traitement parallèle optionnel. Cette conception permet aux équipes de traiter efficacement de grands ensembles de données Vertica sans impacter les charges analytiques en production.
Résultats Validés Après Transformation des Données
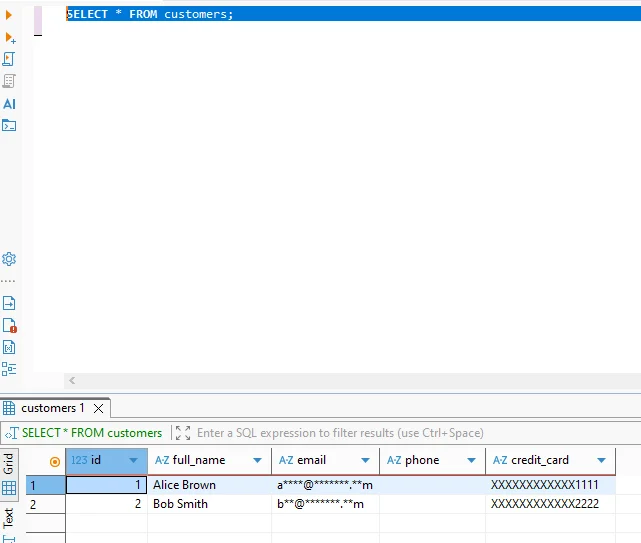
Après traitement, Vertica stocke tous les champs sensibles sous forme transformée. Les requêtes sur l’ensemble de données résultant ne retournent aucune valeur d’origine, même pour les utilisateurs privilégiés.
La requête suivante illustre à quoi ressemblent les données masquées lors de l’interrogation d’une table Vertica après transformation irréversible :
SELECT * FROM customers;
Parce que la transformation est irréversible, ces ensembles restent sûrs pour l’analyse, les environnements QA et le partage de données externes.
Audit et Transparence Opérationnelle
Chaque opération de transformation génère des enregistrements d’audit. Ces enregistrements capturent :
- Quelles tables et colonnes ont été traitées
- Quelles méthodes de transformation ont été appliquées
- Quand la tâche a été exécutée
- Qui a initié l’opération
Cette visibilité s’intègre directement avec la surveillance d’activité des bases de données et les journaux d’audit, rendant la transformation des données défendable lors d’audits.
Transformation Permanente vs Masquage à l’Exécution dans Vertica
Les équipes confondent souvent transformation irréversible et masquage à l’exécution, bien que chacun serve un objectif différent.
Le masquage permanent modifie les valeurs stockées, tandis que le masquage à l’exécution applique les transformations au moment de la requête.
Les techniques irréversibles conviennent mieux lorsque :
- Les données quittent les environnements de production
- La conformité exige l’anonymisation
- Les analyses haute performance doivent éviter la charge à l’exécution
Alignement sur les Conformités pour les Environnements Vertica
| Réglementation | Exigence | Rôle de la Transformation |
|---|---|---|
| RGPD | Anonymisation irréversible des données personnelles | Suppression permanente des identifiants |
| HIPAA | Dé-identification des informations de santé protégées (PHI) | Réutilisation sécurisée des ensembles de données de santé |
| PCI DSS | Protection des données des détenteurs de carte | Données d’analyse et de test masquées |
| SOX | Contrôle de l’accès aux dossiers financiers | Reporting hors production sécurisé |
Ces contrôles s’intègrent naturellement aux flux de travail pris en charge par le DataSunrise Compliance Manager.
Conclusion : Considérer le Masquage Irréversible comme un Contrôle Fondamental
Le masquage irréversible des données dans Vertica n’est pas une amélioration facultative. C’est un contrôle fondamental pour des opérations analytiques sécurisées. Les scripts SQL manuels peuvent fonctionner temporairement, mais ils échouent à grande échelle, face aux audits et aux exigences réglementaires évolutives.
En centralisant les flux de travail de transformation avec DataSunrise, les organisations obtiennent une application cohérente, une auditabilité claire et un alignement avec les réglementations modernes sur la conformité des données. Le masquage devient un processus gouverné plutôt qu’un ensemble fragile de scripts.
Si votre environnement Vertica prend en charge plusieurs consommateurs en aval, le masquage permanent devrait déjà faire partie de votre architecture. Sinon, ce n’est pas du courage – c’est un risque non maîtrisé.
