
Masquage Statique des Données
Introduction
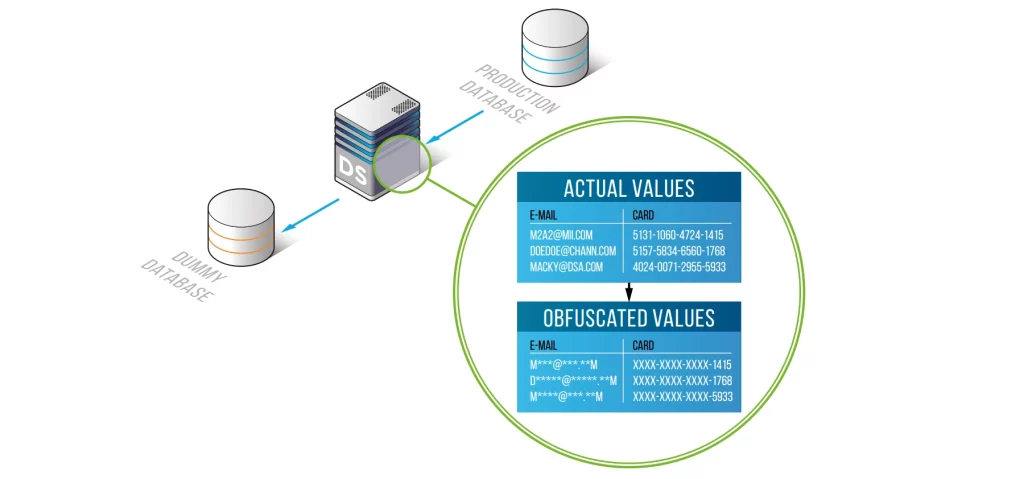
Le masquage statique des données protège les informations sensibles en générant une copie sécurisée et anonymisée des données de production dans laquelle les champs confidentiels sont remplacés par des valeurs réalistes mais fictives. Comme le jeu de données résultant conserve le schéma, les relations et le format des données d’origine, il reste pleinement utilisable pour les tests, l’analyse, le développement logiciel et l’apprentissage automatique — sans exposer les données personnelles, les informations financières ou médicales à des personnes non autorisées. Cette approche permet aux organisations de concilier l’utilité des données avec des exigences strictes en matière de confidentialité et de conformité. Les recommandations issues de normes telles que le cadre de protection des données ISO/IEC 27559 soulignent également l’importance de pratiques d’anonymisation robustes.
Cet article explore les principes clés du masquage statique des données, explique en quoi il diffère du masquage dynamique et examine son rôle crucial dans la gestion de la conformité, l’assurance de la confidentialité et la réduction des risques. Il montre aussi comment DataSunrise facilite le déploiement grâce à des flux de travail automatisés, garantit l’intégrité référentielle au sein de jeux de données complexes et prend en charge des environnements de bases de données hétérogènes — aussi bien sur site que dans le cloud. De plus, le masquage statique est indispensable pour le partage sécurisé des données avec des fournisseurs tiers, des partenaires de recherche ou des équipes de test, ainsi que pour permettre des processus de migration vers le cloud sécurisés où seuls des jeux de données anonymisés et conformes quittent le périmètre protégé de production.
Masquage Statique vs Dynamique : Principales Différences
Les deux techniques protègent les champs sensibles, mais elles répondent à des besoins opérationnels différents.
Le masquage statique des données génère une nouvelle copie masquée de la base de données où le contenu sensible est remplacé par des valeurs synthétiques — idéal pour le développement/test, la transmission aux fournisseurs et le partage sécurisé des données.
En revanche, le masquage dynamique opère à l’exécution — masquant les résultats des requêtes selon le contexte d’accès sans modifier les données stockées — ce qui est préférable pour le contrôle d’accès en temps réel dans les applications.
| Caractéristique | Masquage Statique | Masquage Dynamique |
|---|---|---|
| Fonctionnement | Crée une copie masquée de la base de données | Modifie la sortie des requêtes à l’exécution |
| Cas d’utilisation | Dev/test, accès externes | Contrôle d’accès en production en direct |
| Performance | Aucun impact à l’exécution | Appliqué à la volée |
| Sécurité des données | Sûr pour export/partage | Nécessite des politiques de protection en temps réel |
Quand Utiliser le Masquage Statique
Le masquage statique des données est particulièrement utile lorsque les informations sensibles doivent être déplacées en dehors de leur environnement de production d’origine. Il permet aux équipes de travailler avec des jeux de données réalistes tout en garantissant qu’aucune donnée personnelle identifiée ou régulée ne soit exposée. Les cas d’usage typiques incluent :
- Environnements de développement et de test : Permet aux développeurs et aux ingénieurs de construire, déboguer et optimiser des fonctionnalités en utilisant des données reflétant la complexité réelle — sans révéler les identités clients réelles, les informations de paiement ou les dossiers confidentiels.
- Systèmes d’assurance qualité et de préproduction : Reproduire les conditions de production pour des tests fonctionnels, de performance ou d’intégration sans introduire de risques de conformité ou de confidentialité.
- Formation et intégration des employés : Fournir aux nouvelles recrues et aux équipes de support des exemples réalistes améliorant la compréhension tout en protégeant pleinement les informations sensibles.
- Collaboration externe : Partager en toute sécurité des jeux de données avec des consultants, des équipes externalisées, des chercheurs ou des fournisseurs sans donner accès aux données régulées.
- Migrations vers le cloud, sauvegardes et archivage : Transférer ou stocker des jeux de données masqués pour réduire les risques d’exposition lors du déplacement, de la réplication ou de la conservation à long terme.
Avec DataSunrise, ces processus peuvent être standardisés et automatisés. Le masquage préservant le format assure une cohérence analytique et relationnelle, l’intégrité référentielle est maintenue entre tables et schémas, et les tâches de masquage planifiées garantissent que chaque jeu de données généré reste conforme dans le temps. De plus, les fonctions intégrées d’audit et de contrôle des politiques aident les organisations à valider le processus de masquage et à démontrer la conformité aux auditeurs et aux régulateurs.
Comment DataSunrise Applique le Masquage Statique des Données
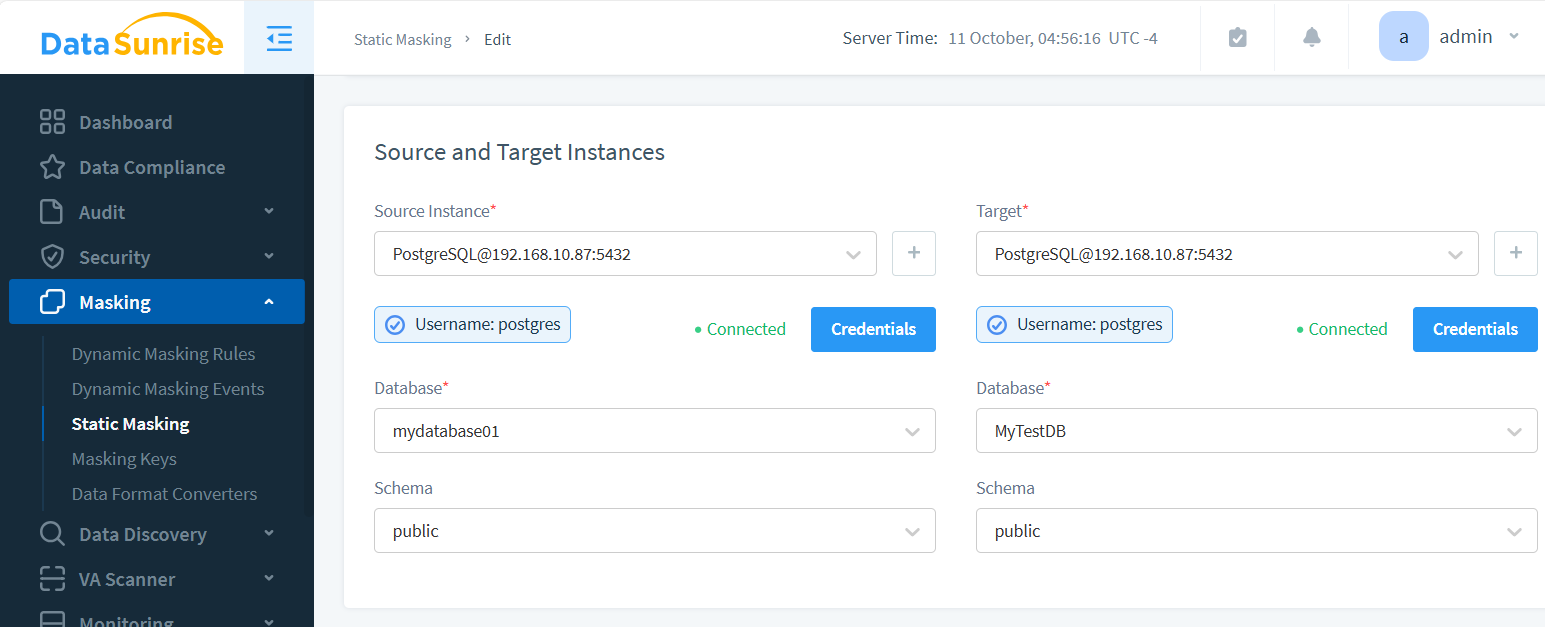
DataSunrise supporte le masquage statique sur SQL Server, Oracle, PostgreSQL, MongoDB et les bases cloud comme Amazon Redshift. Il fonctionne via le serveur DataSunrise (sans modification des schémas). La configuration définit quatre éléments : instances source/cible, tables transférées, fréquence de planification et règles de nettoyage optionnelles.
Fonctions de masquage courantes et quand les utiliser
| Fonction | Exemple d’entrée | Sortie masquée | Idéal pour |
|---|---|---|---|
| FPE (AES-FFX) | 4111 1111 1111 1111 | 4129 6034 5821 4410 | Simulations de cartes de crédit |
| Rédaction par sous-chaîne | [email protected] | al***@***.com | Emails, noms d’utilisateur |
| Mélange de dates (+/- 365j) | 1990-05-09 | 1990-12-17 | Dates de naissance |
| Échange dans un dictionnaire | Chicago | Frankfurt | Champs ville/pays |
Instances Source et Cible
Le processus de masquage génère une nouvelle instance avec des données masquées. La source contient le contenu original ; la cible est l’endroit où résideront les données obfusquées.
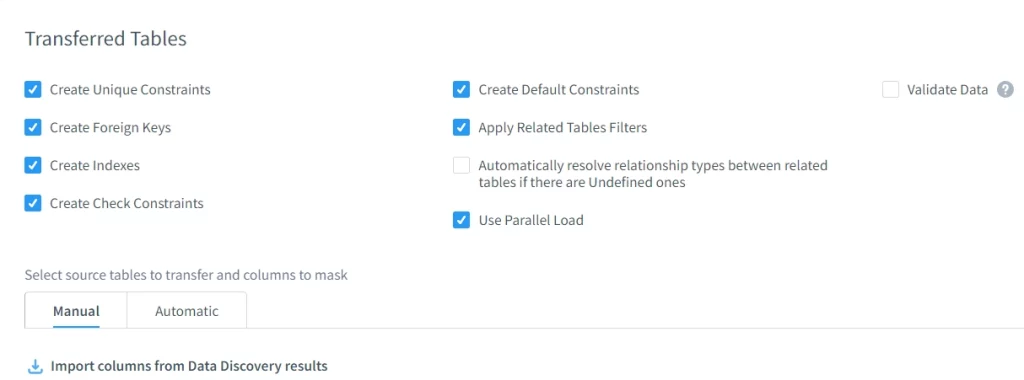
Tables transférées
DataSunrise préserve l’intégrité référentielle, les contraintes, les index et les relations entre les tables masquées — garantissant la continuité d’utilisation des données après obfuscation.
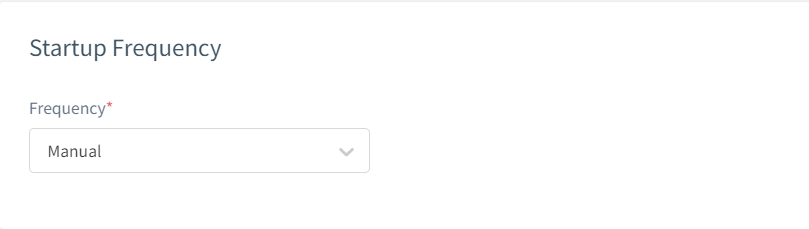
Fréquence de démarrage
Exécutez les tâches manuellement, planifiez-les une fois, ou configurez des intervalles récurrents. Cela automatise les pipelines de mises à jour des données et maintient les environnements de test à jour.
Supprimer les résultats plus anciens que
Appliquez une politique de conservation pour supprimer les bases masquées obsolètes. Cela économise de l’espace de stockage et réduit l’encombrement opérationnel.
Simulation du Masquage Statique dans PostgreSQL
Voici comment simuler manuellement un masquage statique sans automatisation :
-- Étape 1 : Créer une copie masquée d’une table
CREATE TABLE customers_masked AS
SELECT
id,
name,
email,
'XXXX-XXXX-XXXX-' || RIGHT(card_number, 4) AS card_number
FROM customers;
-- Étape 2 : Masquer le format de l’email
UPDATE customers_masked
SET email = CONCAT(LEFT(email, 2), '***@***.com');
Cela fonctionne pour un masquage à petite échelle, mais manque de logique de préservation du format, d’application des clés étrangères et de journalisation d’audit. DataSunrise automatise et met à l’échelle ce processus sur plusieurs plateformes.
Exemple Pratique : PostgreSQL + DataSunrise
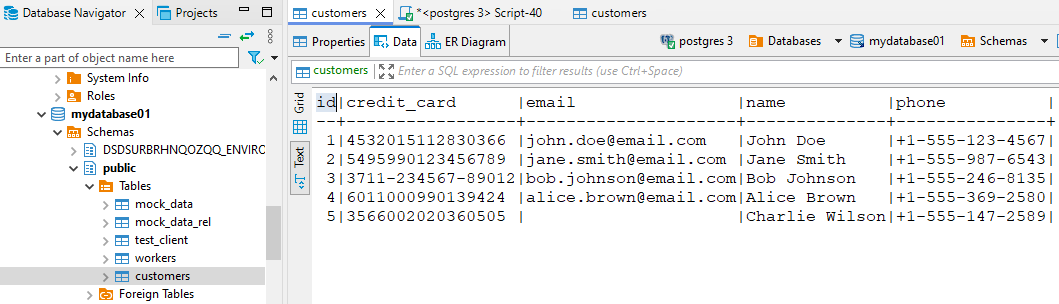
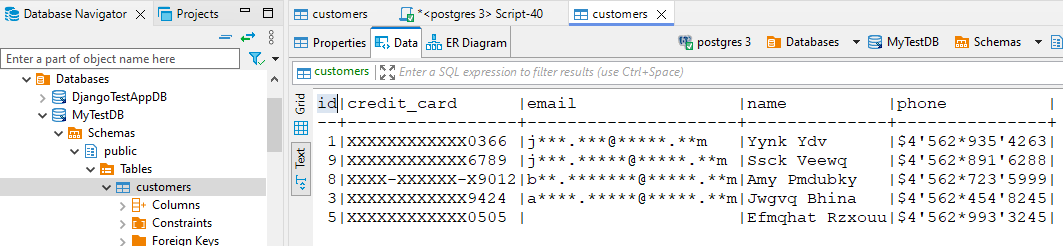
Considérons une base PostgreSQL avec des données clients comprenant noms, emails et numéros de carte. Vue non masquée :
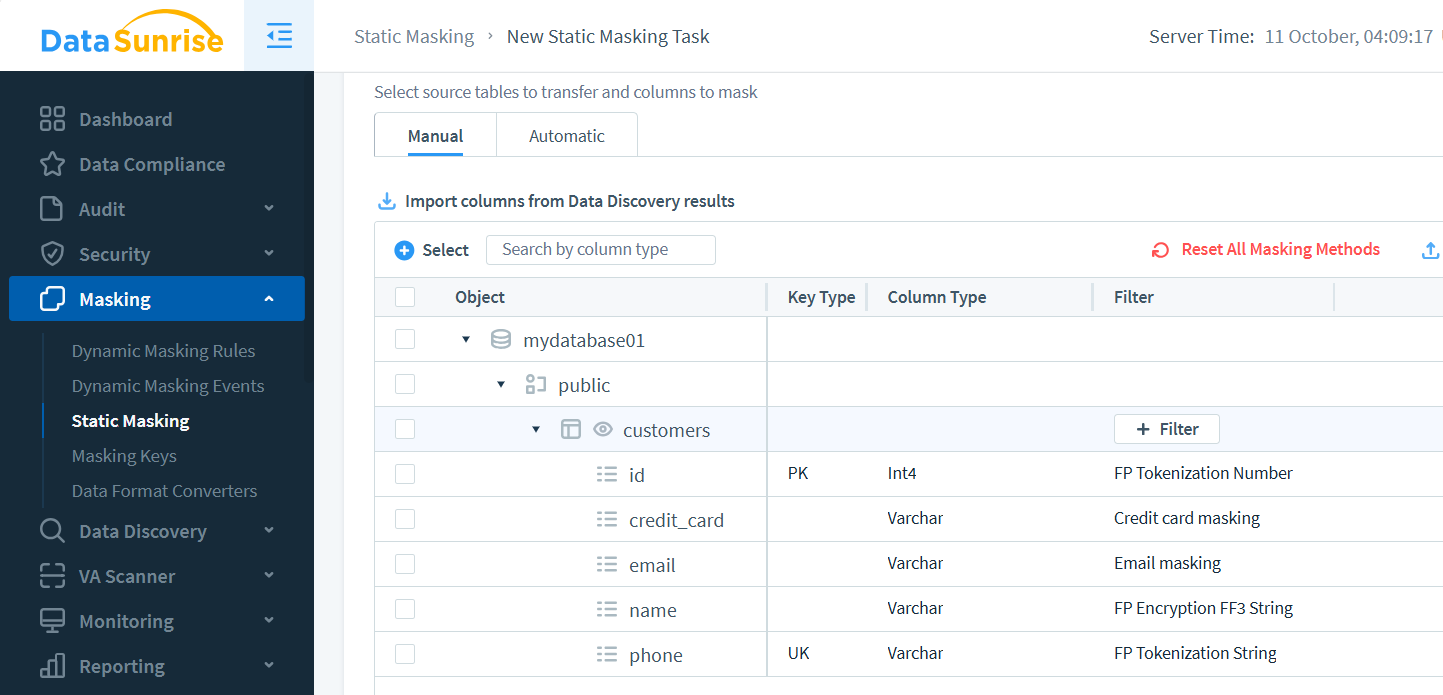
Dans DataSunrise, configurez une tâche via le panneau de Masquage Statique. Sélectionnez les instances, définissez les tables et choisissez les méthodes de masquage par colonne :
Une fois la tâche terminée, la confirmation s’affiche dans le statut de la tâche :
L’instance cible contient maintenant une version pleinement masquée des données :
Masquage Statique avec DataSunrise : Avantages Clés
- Données réalistes pour dev/test
- Obfuscation préservant le format
- Intégrité référentielle maintenue
- Aucun impact sur les systèmes source
- Conforme GDPR/PCI/HIPAA
Meilleures Pratiques pour le Masquage Statique des Données
Même avec le bon outil, l’efficacité dépend d’une mise en œuvre précise. Suivez ces pratiques pour garantir un masquage sécurisé, évolutif et prêt pour l’audit :
- Masquez au niveau des colonnes : Ciblez uniquement les champs à risque (noms, emails, numéros de carte) pour préserver la pertinence des données.
- Privilégiez les méthodes préservant le format pour l’analyse : Conservez la longueur, le type et les schémas référentiels pour la BI, les jointures et les exports.
- Masquez avant l’externalisation : Exportez des copies masquées vers S3, stockage froid ou fournisseurs pour réduire la responsabilité.
- Documentez chaque tâche : Suivez source/cible, tables affectées, méthodes et programmations — DataSunrise enregistre cela pour les revues.
- Révisez les politiques trimestriellement : Mettez à jour les configurations au fur et à mesure de l’évolution des schémas et réglementations.
Intégrez le masquage statique dans le CI/CD afin que chaque environnement de build récupère automatiquement des données assainies. Cela élimine les scripts fragiles, applique une logique cohérente et maintient les environnements de test alignés sur la production — sans exposer de contenu sensible.
Bien réalisé, le masquage statique devient un contrôle récurrent et intégré dans votre cycle de vie de développement, et non une tâche ponctuelle.
Pourquoi Utiliser le Masquage Statique des Données avec DataSunrise
- Protégez les champs sensibles comme les données personnelles, financières et les identifiants avant utilisation externe.
Le masquage statique transforme de manière irréversible les valeurs confidentielles, garantissant que les jeux de données exportés ou partagés ne puissent révéler de véritables informations clients — même s’ils quittent votre environnement sécurisé. - Respectez les exigences telles que GDPR, HIPAA et PCI DSS.
En anonymisant les éléments sensibles à la source, les organisations remplissent les obligations réglementaires relatives à la minimisation des données, au partage sécurisé et à la protection des informations personnelles. - Partagez les données en toute sécurité avec les contractants, analystes et tiers.
Les jeux masqués permettent la collaboration sans exposer les données de production en direct, réduisant les risques d’usage abusif interne ou de divulgation accidentelle. - Réduisez les risques tout en soutenant des environnements de test réalistes.
Les développeurs et équipes QA peuvent travailler avec des jeux de données fidèles qui conservent la valeur statistique et la logique métier — sans le danger d’utiliser de vraies identités ou informations financières. - Préservez l’intégrité référentielle dans des schémas complexes.
Le masquage DataSunrise maintient des relations cohérentes entre tables et champs, assurant que les applications, analyses et pipelines de test fonctionnent correctement après anonymisation.
Conclusion
Le masquage statique des données (MSD) demeure un élément fondamental des cadres modernes de sécurité des données, offrant une méthode fiable et efficace pour anonymiser les informations sensibles tout en préservant la structure, l’intégrité et l’utilisabilité des jeux de données. En substituant les valeurs confidentielles par des équivalents réalistes mais non identifiables, les organisations peuvent exploiter en toute sécurité des données proches de la production pour les tests, le développement, l’analyse et l’entraînement de modèles d’IA sans risquer l’exposition de données personnelles, financières ou propriétaires. Cette démarche assure non seulement la conformité avec des réglementations mondiales telles que le GDPR, HIPAA, SOX et PCI DSS, mais maintient aussi un équilibre optimal entre confidentialité, fonctionnalité et efficacité dans les pipelines DevOps et les écosystèmes de données d’entreprise.
Au-delà du respect des obligations de conformité, le masquage statique joue un rôle crucial dans des opérations complexes comme les migrations cloud, les collaborations externes et les échanges de données interservices. Ses capacités de gestion centralisée et d’automatisation garantissent une application cohérente des politiques dans des environnements hybrides et multi-cloud — réduisant les erreurs humaines et assurant une traçabilité complète tout au long du cycle de vie des données. Lorsqu’il est intégré à des technologies complémentaires telles que le masquage dynamique, la surveillance des activités des bases de données (DAM) et la découverte intelligente des données, le MSD devient une composante essentielle d’une stratégie unifiée de gouvernance des données.
Au sein de plateformes complètes comme DataSunrise, le masquage statique prévient non seulement l’exposition non autorisée des données mais améliore aussi la flexibilité opérationnelle en permettant le partage sécurisé, l’automatisation des tests et l’innovation à grande échelle. Grâce à la surveillance en temps réel, l’application automatisée des règles de conformité et la visibilité centralisée des audits, il transforme la confidentialité des données d’une obligation réactive en une force proactive pour la confiance, la résilience et la transformation numérique durable.
