Outils de Conformité des Données NLP, LLM & ML pour Vertica
Les outils de conformité des données NLP, LLM & ML pour Vertica deviennent essentiels alors que les entreprises accélèrent leur adoption de l’IA générative, de la génération augmentée par récupération (RAG), de l’ingénierie des fonctionnalités et de l’analyse prédictive. Vertica sert fréquemment de backend analytique haute performance pour les pipelines d’apprentissage automatique, la préparation de données à grande échelle et les applications pilotées par l’IA. Cependant, ces mêmes flux de travail augmentent le risque d’exposer involontairement des informations réglementées ou confidentielles aux modèles, requêtes et consommateurs en aval. Par conséquent, les organisations doivent adopter des outils de conformité automatisés capables de surveiller, masquer et contrôler l’accès assisté par IA aux données Vertica.
Les systèmes d’IA modernes introduisent de nouveaux schémas d’exposition. Les grands modèles de langage, les agents autonomes et les charges de travail d’apprentissage automatique génèrent souvent des SQL imprévisibles, extraient des ensembles de données trop vastes ou traitent des champs sensibles comme matériel d’entraînement. Lorsqu’ils ne sont pas protégés, un LLM ou un moteur ML peut révéler des informations privées dans les réponses, les embeddings ou les artefacts dérivés du modèle — ce qui peut entraîner des violations potentielles de conformité au regard du RGPD, HIPAA, PCI DSS, ou NIST 800-53. Comme Vertica n’inclut pas nativement de contrôles d’accès adaptés aux LLM, de masquage dynamique, d’application contextuelle ni d’audit inter-pipelines, les organisations doivent intégrer une couche de conformité spécialisée qui opère de manière proactive avant que les données n’atteignent la couche modèle ou pipeline.
DataSunrise fournit ces fonctionnalités. La plateforme agit comme une passerelle de conformité centralisée pour Vertica en proposant la découverte des données sensibles, le masquage dynamique, l’application SQL et l’audit automatisé. Ensemble, ces fonctionnalités constituent la base des outils de conformité des données NLP, LLM & ML pour Vertica.
Pourquoi Vertica nécessite une automatisation de conformité adaptée aux LLM
Les charges de travail pilotées par l’IA posent des défis de conformité que les systèmes de gouvernance traditionnels ne parviennent pas à résoudre. Par exemple, le SQL généré par les LLM peut demander involontairement des quantités excessives de données sensibles. De plus, les pipelines ETL peuvent extraire des corpus d’entraînement depuis Vertica sans valider que les champs sous-jacents contiennent des données à caractère personnel (PII) ou des informations de santé protégées (PHI). Par ailleurs, les architectures RAG vectorisent souvent des colonnes textuelles — y compris celles comportant des identifiants personnels — en embeddings, rendant la gestion de la traçabilité extrêmement difficile.
De plus, l’architecture de Vertica amplifie ces risques. Des fonctionnalités telles que les projections, le stockage ROS/WOS et les schémas analytiques larges peuvent répartir des valeurs sensibles sur plusieurs structures physiques. Comme Vertica fonctionne en tant que plateforme analytique haute performance pour une variété de charges de travail — allant des tableaux de bord BI aux frameworks ML comme VerticaPy — toute faille de conformité peut rapidement se propager à travers plusieurs équipes et systèmes.
Pour éviter les échecs de conformité, les organisations ont besoin des outils de conformité des données NLP, LLM & ML pour Vertica qui automatisent :
- la découverte des colonnes sensibles de Vertica avant l’entraînement ML ou l’ingestion RAG,
- le masquage dynamique des attributs à haut risque pour les charges NLP et LLM,
- l’application de règles contextuelles SQL pour éviter les requêtes non sécurisées ou excessives générées par l’IA,
- l’audit automatisé de tous les accès générés par l’IA vers Vertica,
- la surveillance pour réduire le risque d’hallucinations LLM exposant des valeurs privées.
Ainsi, sans contrôles automatisés, les pipelines IA peuvent involontairement ingérer des données non masquées ou révéler des champs sensibles lors de l’inférence.
Architecture des outils de conformité des données NLP, LLM & ML pour Vertica
Le diagramme ci-dessous illustre comment les outils de conformité des données NLP, LLM & ML pour Vertica fonctionnent comme une couche de sécurité et de transformation entre Vertica et les charges de travail IA. Chaque requête LLM, ML, NLP et ETL transite par cette couche d’application, garantissant un masquage, un audit et une inspection SQL cohérents.

Cette architecture prend en charge :
- les assistants LLM générant du SQL de manière dynamique,
- les pipelines RAG interrogeant les tables Vertica pour la récupération,
- les processus d’ingénierie des fonctionnalités lisant des colonnes sensibles,
- l’entraînement ML en batch extrayant des jeux de données directement de Vertica.
Comme toute application des règles s’effectue avant que les données Vertica n’atteignent les systèmes IA, les organisations conservent une visibilité, une cohérence et une gouvernance complètes sur chaque flux de travail NLP, LLM et ML.
Découverte des données sensibles dans les pipelines IA Vertica
Une automatisation efficace commence par la découverte. Les outils de conformité des données NLP, LLM & ML pour Vertica doivent identifier tous les champs sensibles susceptibles d’affecter les données d’entraînement, les embeddings vectoriels, les requêtes ou les résultats d’inférence. La découverte des données sensibles par DataSunrise analyse les tables Vertica et identifie automatiquement les PII, PHI, les valeurs financières, les jetons d’authentification et les colonnes en texte libre contenant du contenu réglementé.
Ce mécanisme de découverte proactive empêche les jeux de données d’entraînement d’être contaminés par des informations sensibles. De plus, les résultats de découverte s’intègrent directement aux modules de masquage et d’application SQL, garantissant que les champs nouvellement détectés héritent automatiquement des protections de conformité requises.
Masquage dynamique pour les outils de conformité des données NLP, LLM & ML pour Vertica
Le masquage dynamique est l’un des outils centraux de conformité des données NLP, LLM & ML pour Vertica. Quand les systèmes IA génèrent du SQL, ils spécifient rarement quelles colonnes doivent rester protégées. En raison de cette imprévisibilité, le masquage doit se faire automatiquement — basé sur la politique — et non sur la logique applicative.
La capture d’écran ci-dessous montre comment les administrateurs configurent le masquage dynamique pour des champs Vertica fréquemment utilisés par les pipelines ML et NLP :
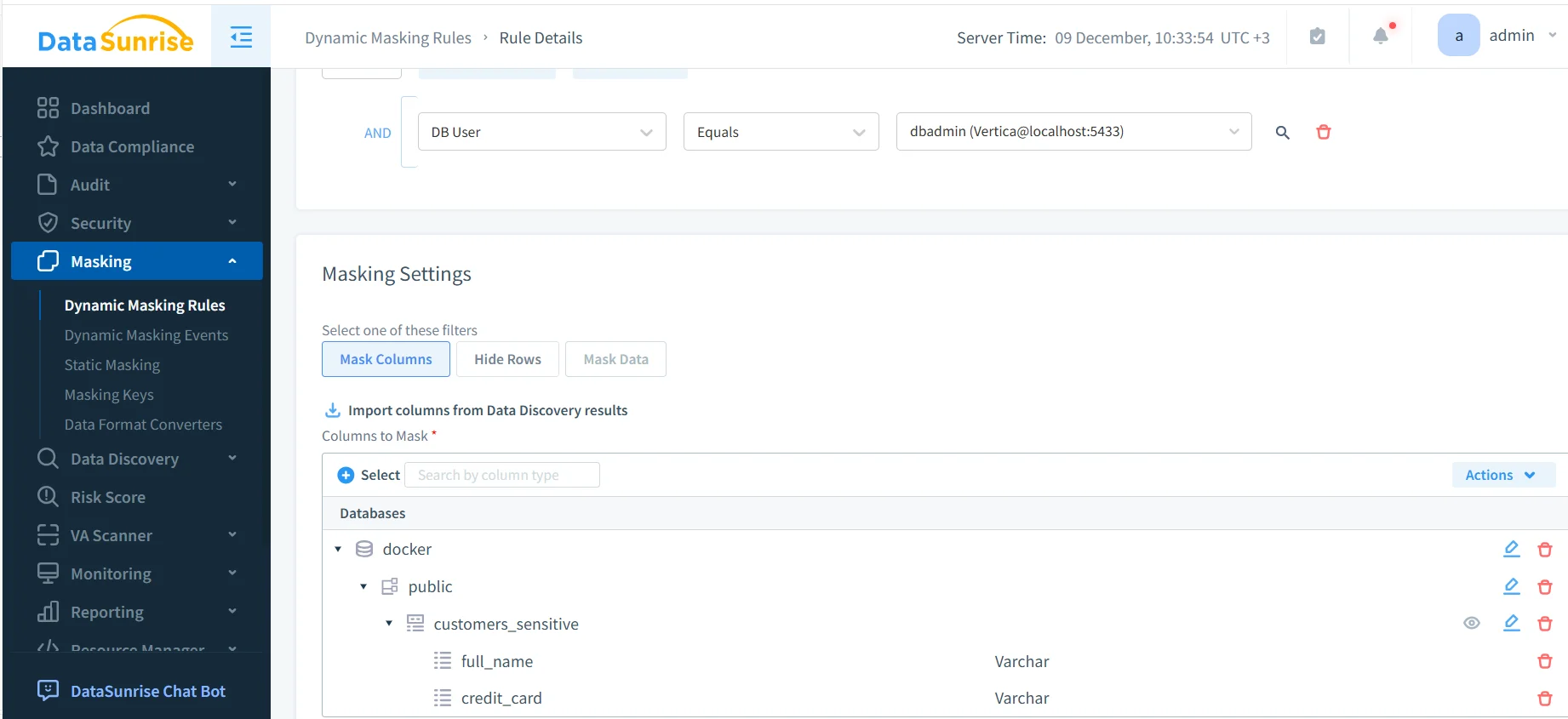
Ce masquage automatisé protège les attributs sensibles lors de :
- la génération de prompts pour les applications LLM,
- les flux de récupération basés sur RAG alimentant les magasins vectoriels,
- les extractions ETL pour les magasins de fonctionnalités ML,
- la construction de jeux de données d’entraînement de modèles,
- l’exploration par les data scientists dans les notebooks.
De plus, le masquage empêche les modèles IA de divulguer des valeurs originales dans les réponses, les embeddings ou les artefacts d’entraînement — en conformité avec les règles de pseudonymisation RGPD et les exigences PCI DSS.
Application des règles SQL pour les outils de conformité des données NLP, LLM & ML pour Vertica
Le SQL généré par l’IA peut introduire des risques importants. Les LLM produisent souvent des requêtes comprenant des JOIN non contraints, des scans SELECT * ou des extractions à l’échelle du schéma. En outre, les agents IA peuvent accidentellement générer des instructions de modification telles que DROP TABLE ou ALTER TABLE. Pour relever ces défis, les outils de conformité des données NLP, LLM & ML pour Vertica appliquent des règles SQL contextuelles avant que la requête n’atteigne Vertica.
Cette application empêche :
- les attaques d’injection de prompt visant à extraire des tables sensibles ou restreintes,
- les scans à haut volume exposant des jeux de données entiers à un LLM,
- les altérations de schéma déclenchées par des agents autonomes,
- les récupérations excessives de données durant l’ingénierie des fonctionnalités ML.
Avec cette automatisation des règles en place, les organisations ont l’assurance que le SQL généré par les LLM ne peut pas dépasser les limites des politiques.
Audit automatisé pour les outils de conformité des données NLP, LLM & ML pour Vertica
Un audit complet est essentiel pour une gouvernance responsable de l’IA. Les outils de conformité des données NLP, LLM & ML pour Vertica doivent fournir une visibilité complète sur la manière dont les agents IA, pipelines et applications interagissent avec les données sensibles de Vertica. La journalisation manuelle est insuffisante car les charges IA génèrent des milliers de requêtes de manière autonome.
DataSunrise capture automatiquement l’activité SQL, les transitions de sessions, les résultats de masquage et les actions déclenchées par les règles. La capture d’écran ci-dessous présente une piste d’audit unifiée adaptée aux revues opérationnelles comme aux vérifications réglementaires.
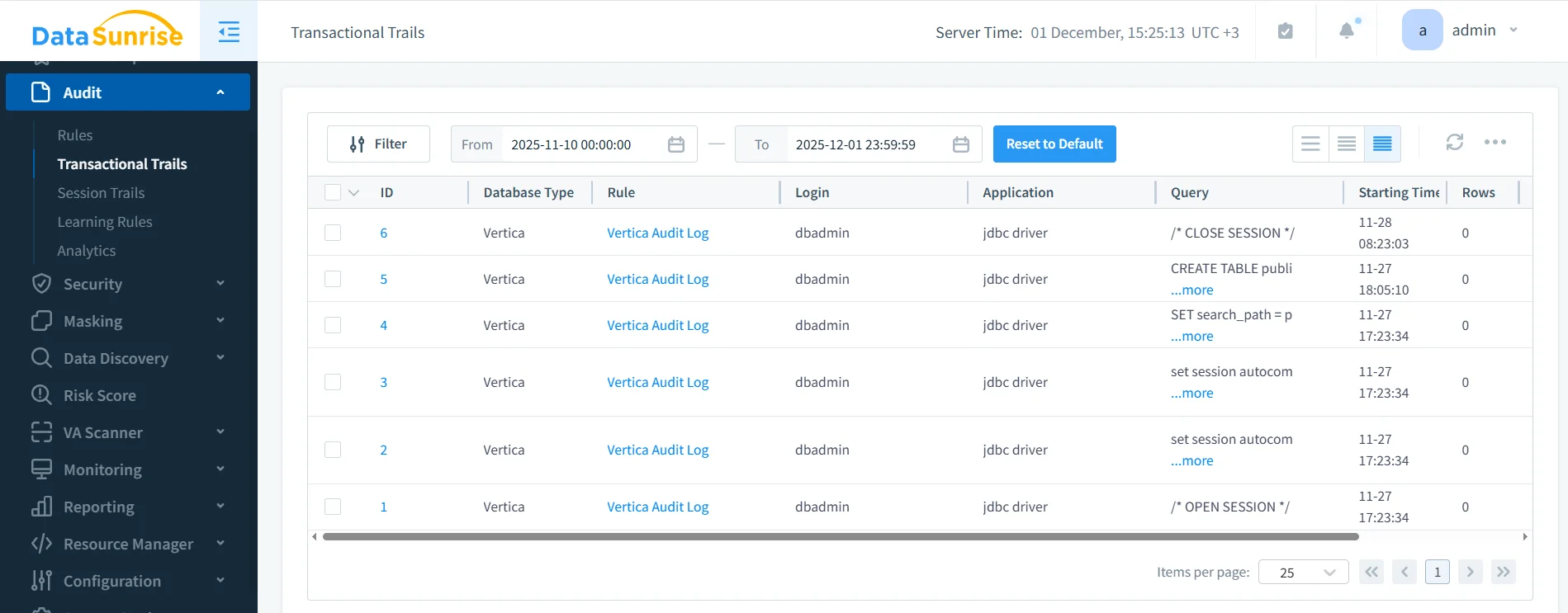
Ces journaux permettent aux équipes de conformité de :
- tracer comment un jeu de données construit par un LLM a été généré,
- valider que les champs sensibles ont été masqués lors de l’ingestion,
- investiguer les comportements anormaux ou à haut risque du modèle,
- produire des preuves d’explicabilité pour les déploiements IA régulés.
Parce que les données d’audit sont centralisées, les organisations maintiennent une supervision cohérente sur toutes les interactions LLM, NLP, ETL et ML.
Comparaison : Vertica vs. Outils de conformité des données NLP, LLM & ML pour Vertica
| Exigence de conformité IA | Capacité native Vertica | Outils de conformité des données NLP, LLM & ML pour Vertica |
|---|---|---|
| Détection PII/PHI avant entraînement | Revue manuelle | Découverte automatique des données sensibles |
| Masquage dynamique pour requêtes IA | Non disponible | Masquage en temps réel |
| Application SQL LLM | RBAC uniquement | Filtrage SQL basé sur des règles |
| Journaux d’audit centralisés | Journaux distribués | Piste d’audit unifiée |
| Traçabilité des données d’entraînement | Suivi manuel | Corrélation automatisée adaptée à l’IA |
Conclusion
Les outils de conformité des données NLP, LLM & ML pour Vertica offrent aux organisations la capacité de déployer des technologies IA de manière sécurisée et responsable. Le masquage dynamique bloque l’exposition des valeurs sensibles. L’application des règles SQL empêche les requêtes non sécurisées ou non intentionnelles générées par des systèmes autonomes. L’audit automatisé fournit une visibilité complète et des preuves pour les revues réglementaires. Ensemble, ces contrôles forment un cadre d’automatisation de conformité de bout en bout qui protège les données Vertica à travers toutes les charges NLP, LLM et ML.
