
Qu’est-ce qu’un fichier CSV ?
Introduction : Le simple fichier CSV
Les fichiers CSV remontent aux débuts de l’informatique et restent un format fiable pour l’échange de données. Dans les années 1970 et début 1980, le langage Fortran 77 d’IBM a introduit le type de données caractères, permettant la prise en charge des entrées et sorties séparées par des virgules. Ces fichiers simples mais puissants ont résisté à l’épreuve du temps.
Nous avons précédemment décrit les capacités de DataSunrise pour gérer les données semi-structurées en JSON. Si vous traitez des ensembles de données structurées ou non structurées, n’oubliez pas de consulter notre présentation de ses fonctionnalités de protection des données.
Avec DataSunrise, vous pouvez masquer et découvrir les informations sensibles à l’intérieur de fichiers au format CSV stockés localement ou dans Amazon S3. Voici un exemple d’application du masquage sur un fichier CSV lors du traitement.
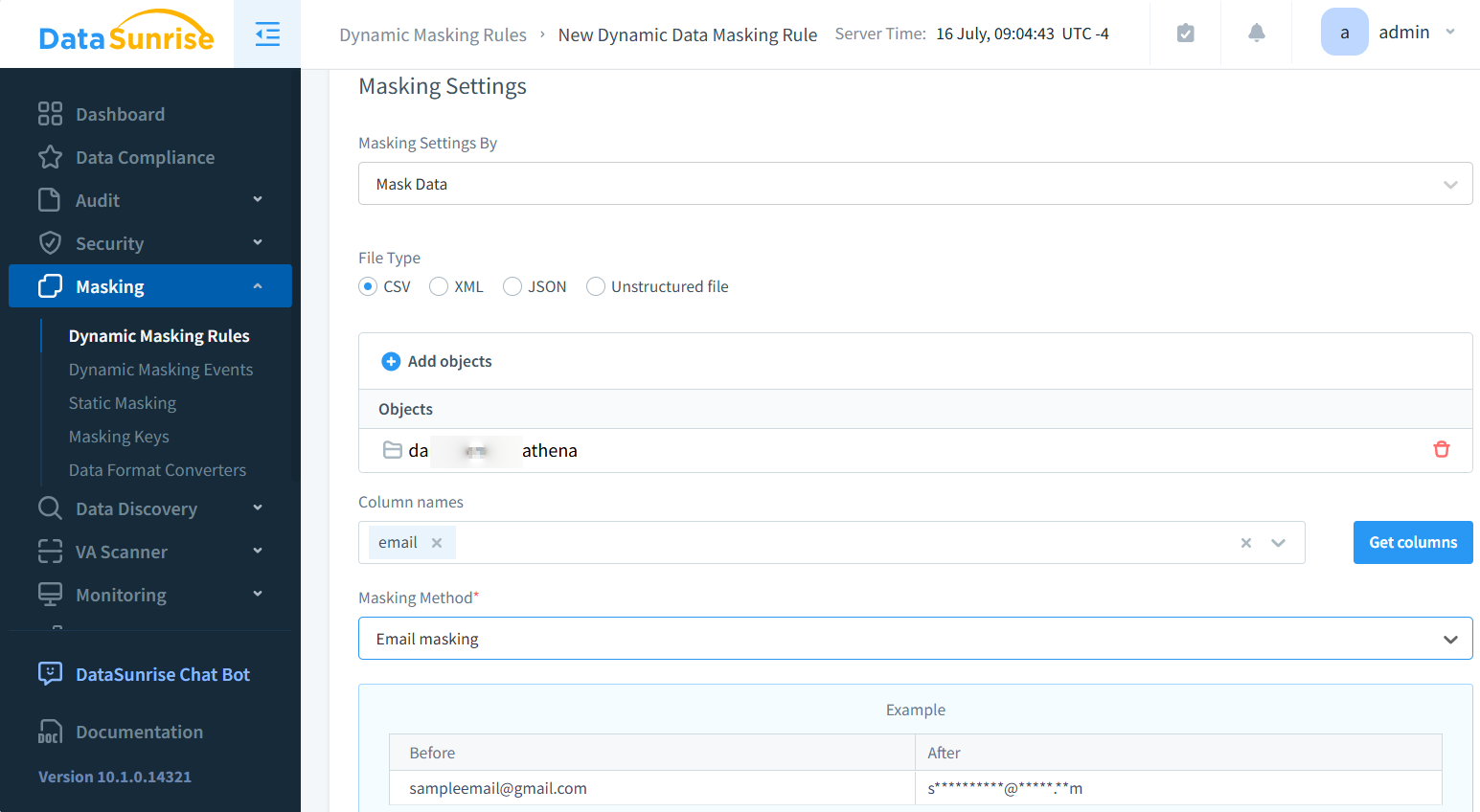
Après une configuration simple, le fichier masqué peut être consulté via le proxy S3 de DataSunrise en utilisant des clients comme S3Browser. Veillez à configurer correctement les paramètres du proxy pour afficher le contenu masqué, comme illustré ci-dessous :

Dans le vaste univers des formats de données, le fichier CSV se distingue par sa clarté et sa portabilité. Il stocke des données tabulaires dans une structure simple où chaque ligne représente une ligne du tableau et les valeurs sont séparées par des virgules. Cette simplicité permet au format de rester compatible sur différentes plateformes et systèmes.
Qu’est-ce qu’un fichier CSV ?
Utilisé pour représenter des lignes et colonnes en texte brut, un fichier CSV offre un moyen léger de stocker et d’échanger des données structurées. Chaque ligne contient une ligne de tableau, et les virgules divisent les champs qui la composent. Le résultat est un format facile à lire et à générer de façon programmatique.
Les fichiers utilisent généralement l’extension « .csv » — par exemple « contacts.csv » ou « report_data.csv ». Ouvrez-les dans un éditeur de texte, et vous verrez une liste de valeurs séparées par des virgules. Les outils tableurs comme Excel ou Google Sheets interprètent le contenu comme des tableaux structurés.
Si les virgules sont les délimiteurs standard, des points-virgules, tabulations ou barres verticales peuvent apparaître dans certaines implémentations régionales ou personnalisées. Inclure une ligne d’en-tête est optionnel mais recommandé, surtout quand l’ensemble de données comporte plusieurs champs.
Contrairement à des formats plus sophistiqués, celui-ci ne prend pas en charge les formules intégrées, styles ou données imbriquées. Ce compromis en fait un format idéal pour des exportations propres mais inadapté aux rapports complexes.
Pourquoi utiliser les fichiers CSV ?
Ce format reste populaire grâce à sa simplicité et sa polyvalence :
- Simplicité : Facile à lire, même pour les utilisateurs sans expérience technique.
- Compatibilité : Pris en charge par quasiment tous les outils tableurs et bases de données.
- Échange de données : Utile pour transférer des données entre systèmes avec différents formats.
- Efficacité de taille : Plus petit que les formats binaires, ce qui facilite le stockage et les performances.
Exemple CSV
Voici un exemple simple pour illustrer la présentation des données dans un fichier CSV :
Nom, Âge, Ville John Doe, 30, New York Jane Smith, 25, Londres Bob Johnson, 35, Paris
Chaque enregistrement est sur une ligne distincte, avec les virgules séparant les champs individuels. Cette structure est cohérente dans la plupart des fichiers CSV.
Travailler avec les fichiers CSV en Python
Python propose des bibliothèques intégrées qui facilitent le travail avec les fichiers CSV. Le module csv est souvent utilisé pour lire et écrire ces fichiers dans des scripts basiques.
import csv
# Lecture d’un fichier
with open('data.csv', 'r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
# Écriture dans un fichier
with open('output.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['Nom', 'Âge', 'Ville'])
csv_writer.writerow(['Alice', '28', 'Berlin'])
Utilisation de Pandas
Pour des workflows plus avancés, la bibliothèque pandas est souvent préférée. Elle permet aux développeurs de charger des fichiers CSV, de les manipuler grâce à des structures DataFrame riches, et d’exporter des résultats propres.
import pandas as pd
# Lecture
df = pd.read_csv('data.csv')
print(df.head())
# Écriture
df.to_csv('output.csv', index=False)
Des tâches comme le filtrage, le tri et l’agrégation de données sont beaucoup plus simples avec pandas. La bibliothèque facilite également la sauvegarde des ensembles de données modifiés au format CSV pour le partage ou le stockage.
Avantages et inconvénients des fichiers séparés par des virgules
Avantages
- Lisible par l’humain : les fichiers peuvent être ouverts et interprétés manuellement
- Léger : surcharge minimale par rapport aux formats binaires
- Universellement supporté : fonctionne dans presque tous les outils liés aux données
Inconvénients
- Complexité limitée : ne prend pas en charge les données imbriquées ou complexes
- Pas de schéma obligatoire : l’ordre des colonnes et leurs types sont faiblement définis
- Risques d’intégrité : absence de contrôles intégrés pour la validation ou la gestion des erreurs
Fichiers CSV dans l’échange de données
Ce format est utilisé dans de nombreux domaines et processus :
- Intelligence d’affaires : déplacement de rapports entre des outils comme Tableau et des entrepôts SQL
- Recherche scientifique : publication d’ensembles de données pour réutilisation et validation
- Applications web : permettre aux utilisateurs d’exporter des données pour sauvegarde ou analyse
- IoT et enregistrement de capteurs : format simple pour capturer des relevés
Fichiers CSV en environnement d’entreprise
De nombreux systèmes d’entreprise utilisent encore des fichiers CSV pour les importations, exportations et audits de données. Les institutions financières génèrent des bilans de transactions dans ce format. Les systèmes de santé s’appuient sur des transferts CSV sécurisés pour partager les données patients. Pour les migrations, le CSV sert souvent de pont entre les systèmes hérités et modernes.
Fichiers CSV dans le domaine du Big Data
Malgré l’essor des formats Parquet et Avro, les fichiers CSV n’ont pas disparu du monde du Big Data. Ils remplissent encore des fonctions clés dans certains pipelines.
- Ingestion : les données arrivent souvent sous forme CSV avant transformation
- Compatibilité héritée : de nombreux systèmes amont produisent du texte brut
- Exportation des résultats : le CSV facilite le partage ou l’archivage des données
Cependant, ses limites en termes de schéma, compression et parsing le rendent moins adapté aux analyses à grande échelle. C’est là que les formats binaires excellent généralement.
Quand utiliser un fichier CSV vs un format binaire
| Cas d’utilisation | Meilleur format | Pourquoi |
|---|---|---|
| Échange de données inter-systèmes | CSV | Simple, lisible par l’humain, supporté partout |
| Analyses à grande échelle | Parquet / Avro | Support du schéma et compression haute performance |
| Exports ou journaux quotidiens | CSV | Facile à automatiser et à examiner manuellement |
Conclusion : La valeur durable des fichiers CSV
Même avec l’essor des formats de données modernes et des systèmes de stockage complexes, le CSV reste l’un des composants les plus polyvalents et fiables de l’écosystème des données actuel. Sa simplicité, sa compatibilité universelle et sa structure lisible par un humain en font un format essentiel pour l’échange de données, l’analyse rapide, le prototypage et l’archivage à long terme.
Dans les environnements d’entreprise, des outils comme DataSunrise renforcent encore la praticité des fichiers CSV en ajoutant des capacités critiques telles que le masquage dynamique ou statique des données, la journalisation d’audit détaillée, la classification des données, et la découverte automatisée des champs sensibles. Ces fonctionnalités aident les organisations à gérer en toute sécurité les workflows basés sur CSV, réduire les risques opérationnels, et répondre aux exigences de conformité dans des cadres comme le RGPD, HIPAA et PCI DSS. Si vos équipes manipulent des jeux de données CSV sensibles, envisagez d’explorer les solutions de sécurité DataSunrise — consultez la présentation de la plateforme ou planifiez une démo pour découvrir comment simplifier la protection et la gouvernance.
