
Sécurité des agents LLM dans les scénarios RAG/RLHF

Les agents des grands modèles de langage (LLM) gagnent en popularité dans les flux de travail de Génération Augmentée par la Recherche (RAG) et d’Apprentissage par Renforcement avec des Rétroactions Humaines (RLHF). Ces agents intelligents améliorent la compréhension du contexte, automatisent les flux de données et fournissent des réponses adaptatives. Toutefois, leur intégration dans des pipelines de données sensibles engendre des risques de sécurité et de conformité qui doivent être gérés de manière proactive.
Lacunes de sécurité introduites par les agents LLM
Les LLM opèrent souvent sur des données hétérogènes extraites en temps réel tant des référentiels internes que des bases de connaissances externes. Dans les flux de travail RAG, les agents interrogent des bases de données vectorielles et injectent le contexte récupéré dans les invites. Dans les pipelines RLHF, ils interagissent avec des données d’entraînement étiquetées par des humains ou avec des journaux de rétroaction. Cette vaste surface d’accès ouvre des risques d’injection dans les invites, de fuite de données et de reproduction de comportements non régulés.
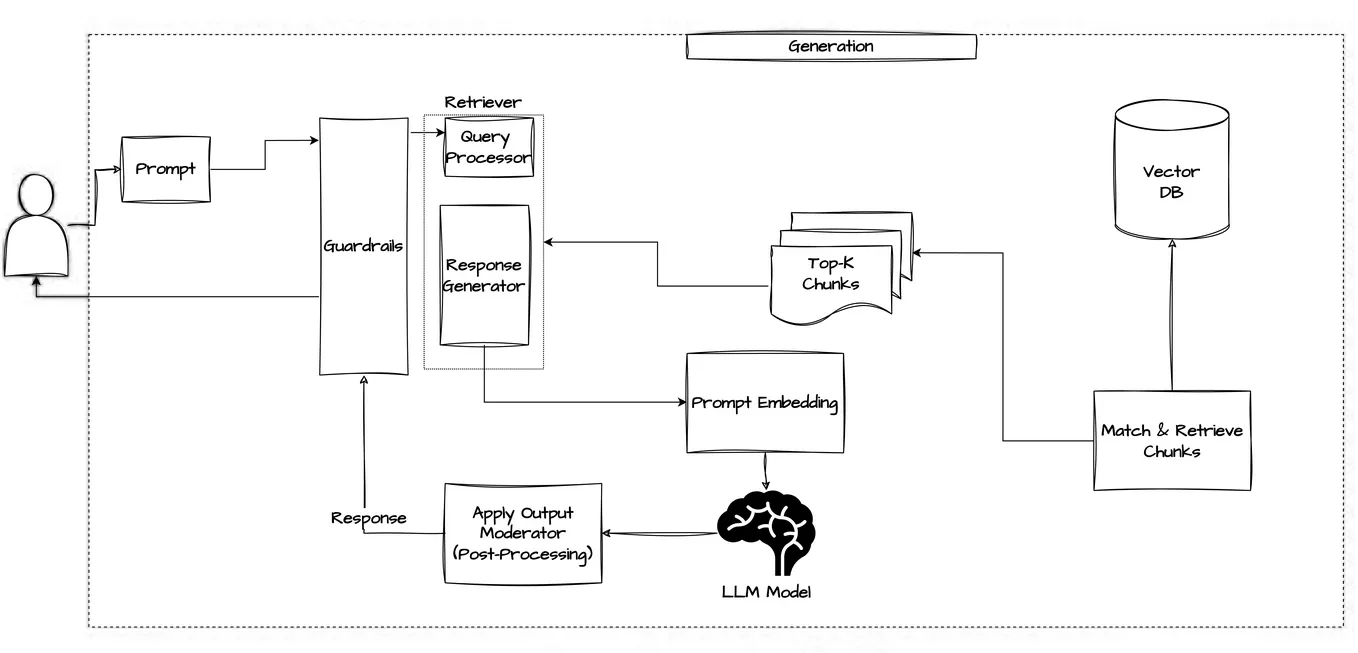
Sans contrôles adéquats, les agents LLM peuvent accéder à des données commerciales sensibles, en exposer le contenu, propager des rétroactions manipulées ou interagir avec des jeux de données non conformes. Ces risques exigent une surveillance continue, un masquage des données et l’application de politiques sur l’ensemble des boucles d’inférence et de rétroaction des LLM. Comme le souligne la conception de systèmes d’IA sécurisés de Google, ces défis doivent être relevés de manière proactive dès la phase de conception.
Audit en temps réel des interactions avec les LLM
Pour retracer le fonctionnement des agents et déterminer les données qu’ils manipulent, un audit en temps réel est indispensable. Cela inclut le suivi du contenu des requêtes, l’association entre utilisateur et agent, les résultats vectoriels récupérés, la structure des invites et les complétions résultantes. La consignation de ces métadonnées aide à détecter des comportements anormaux, à reconstruire les chaînes de prise de décision et à démontrer la conformité avec HIPAA, le RGPD et le PCI DSS.
Des solutions telles que la plateforme Data Audit de DataSunrise permettent cela grâce à des règles d’audit personnalisables qui surveillent l’activité des requêtes structurées et non structurées. Les règles d’audit peuvent être configurées pour signaler des mots-clés spécifiques, des tentatives d’accès ou des charges utiles vectorielles injectées dans les invites. De même, Azure Monitor pour LLM de Microsoft montre comment les événements d’exécution peuvent être consignés et visualisés à grande échelle.
Masquage dynamique des données pour les pipelines GenAI
Le masquage dynamique des données garantit que des champs sensibles tels que les noms, les adresses e-mail ou les numéros de compte sont remplacés à l’exécution avant d’être transmis au modèle. Ceci est particulièrement crucial dans les configurations RAG, où un agent récupère des données pouvant inclure des attributs confidentiels.
Avec le masquage dynamique, les données sources originales demeurent intactes tandis que différents utilisateurs ou types d’agents bénéficient de vues adaptées en fonction de leur rôle ou du contexte. Par exemple:
SELECT full_name, credit_card FROM customers;
-- devient --
SELECT '***MASQUÉ***' AS full_name, 'XXXX-XXXX-XXXX-1234' AS credit_card;
Cela protège la vie privée tout en permettant aux modèles d’interagir avec des points de données réalistes mais anonymisés. Le masquage constitue également une part essentielle des recommandations d’atténuation des risques GenAI du NIST.
Découverte des données comme fondement de la sécurité
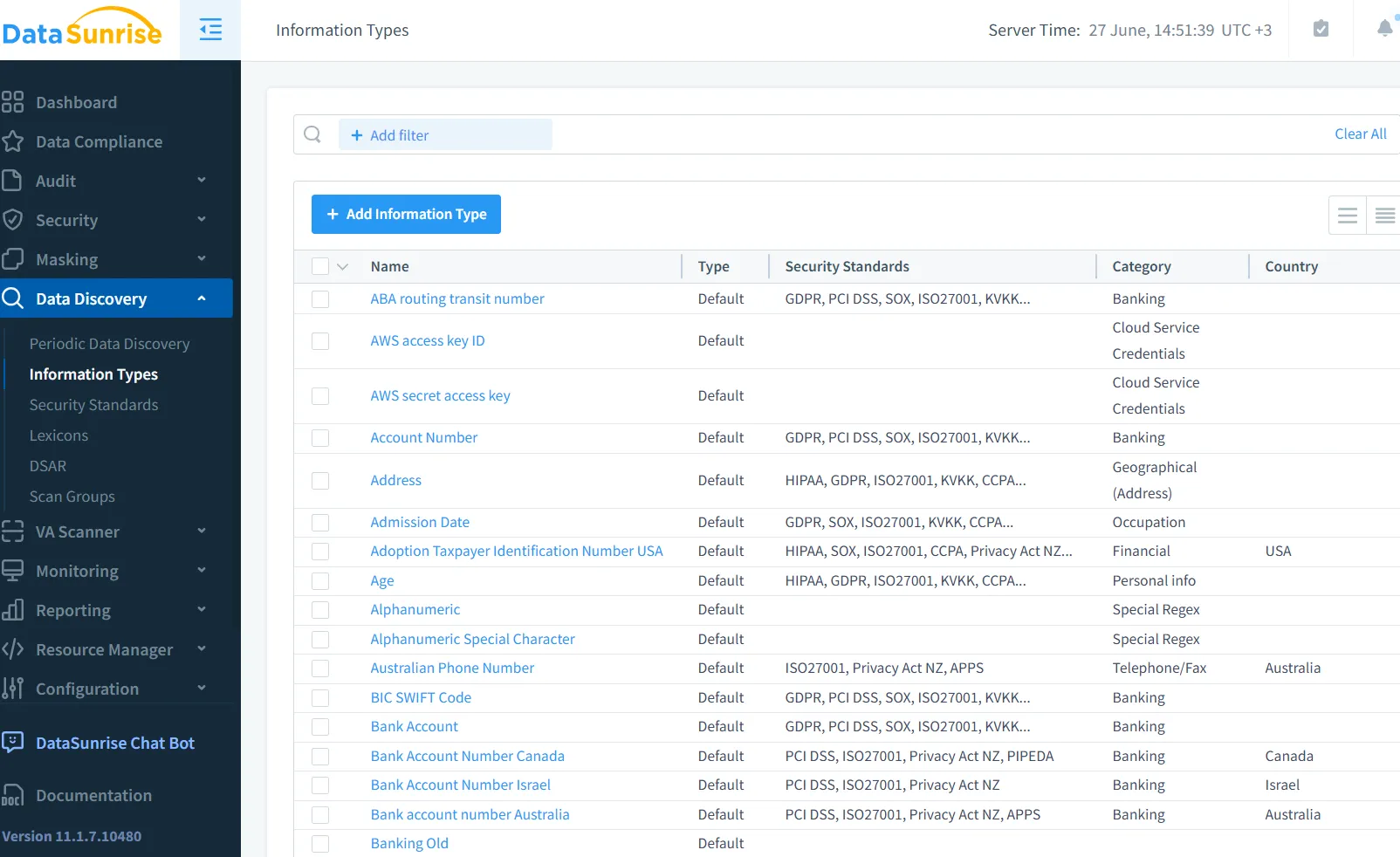
Avant de mettre en œuvre toute politique de masquage ou d’accès, il est essentiel d’identifier où résident les données. Les outils de découverte des données peuvent scanner les bases de données, les magasins vectoriels et les journaux non structurés à la recherche de types de données sensibles. Ceci revêt une importance particulière lors de la construction de LLM sur des systèmes hérités pour lesquels la documentation est limitée.
Le moteur de découverte de DataSunrise prend en charge la classification basée sur des motifs, les recherches dans des dictionnaires et la classification assistée par IA de nouveaux types de données. Une fois cartographiées, ces informations permettent de concevoir des politiques adaptées et d’établir des seuils appropriés pour le masquage, la consignation ou les alertes. De même, AWS Macie peut aider à identifier les données sensibles dans les compartiments S3 utilisés par les récupérateurs vectoriels.
Application de la sécurité grâce aux règles d’accès
La sécurité doit être gérée à plusieurs niveaux : la base de données, la passerelle API et le point de service des modèles. La définition et l’application de règles d’accès — telles que le blocage des adresses IP non fiables, la restriction des jointures entre différents domaines de données ou la limitation de la longueur des invites — contribuent à prévenir les abus.
Le moteur de règles de sécurité de DataSunrise permet aux équipes d’établir un contrôle granulaire contre l’injection, l’exfiltration ou l’utilisation abusive. Les agents LLM peuvent être ajoutés à une liste blanche ou se voir accorder un accès basé sur les rôles pour des types de requêtes spécifiques, limitant ainsi leurs capacités et réduisant leur exposition.
Cela aide également à atténuer les attaques par injection dans les invites, lorsque les agents tentent de contourner leurs contraintes pour accéder à la logique ou aux données internes. Pour obtenir des conseils sur la défense contre de telles attaques, consultez le Top 10 des risques LLM d’OWASP.
Cartographie de la conformité et assurance continue
Avec l’intégration des modèles GenAI dans les systèmes de production, la surveillance réglementaire se renforce. Aligner les pipelines LLM avec les normes de conformité nécessite la classification des données, leur documentation, le suivi des consentements, la limitation de l’exposition et des rapports périodiques.
Le Compliance Manager de DataSunrise prend en charge cette démarche en liant les pistes d’audit, les configurations de masquage et les hiérarchies de rôles dans une interface centralisée de conformité. Il propose des modèles intégrés pour HIPAA, PCI DSS, SOX et le RGPD, simplifiant ainsi les contrôles internes et les audits externes.
De plus, consultez les directives de l’EU AI Act pour comprendre les obligations légales émergentes concernant les modèles de base et les systèmes d’IA interagissant avec des données sensibles ou réglementées.
Application de ces outils dans les flux de travail RAG/RLHF
Dans un scénario RAG concret, un agent LLM pourrait lancer une recherche vectorielle pour des affaires juridiques contenant un texte de loi spécifique. Le magasin vectoriel peut inclure à la fois des documents juridiques publics et internes. Pour garantir la conformité, la découverte signale les enregistrements sensibles, le masquage réédite les identifiants des clients, les journaux d’audit capturent le contexte des requêtes et les règles d’accès restreignent les opérations risquées.
Dans les pipelines RLHF, les retours humains contiennent souvent des commentaires ou des étiquettes confidentiels. Ceux-ci doivent être correctement masqués, audités et stockés conformément à la politique en vigueur. Par exemple, le livre blanc RLHF d’Anthropic illustre comment les pipelines de rétroaction doivent être structurés en tenant compte de la confidentialité.
Réflexions finales
La sécurité des agents LLM dans les scénarios RAG/RLHF requiert bien plus qu’un simple ajustement du modèle ou une validation humaine. Le contrôle en temps réel du flux de données — ce qui est récupéré, masqué et consigné — est fondamental. En combinant les pistes d’audit, les stratégies de masquage, les analyses de découverte et le contrôle d’accès avec l’automatisation de la conformité, les organisations peuvent déployer des systèmes GenAI sûrs et responsables.
Découvrez-en davantage sur l’automatisation de la conformité des données ou consultez les outils de sécurité adaptés aux LLM pour préparer votre infrastructure à l’IA de niveau production.
Protégez vos données avec DataSunrise
Sécurisez vos données à chaque niveau avec DataSunrise. Détectez les menaces en temps réel grâce à la surveillance des activités, au masquage des données et au pare-feu de base de données. Appliquez la conformité des données, découvrez les données sensibles et protégez les charges de travail via plus de 50 intégrations supportées pour le cloud, sur site et les systèmes de données basés sur l'IA.
Commencez à protéger vos données critiques dès aujourd’hui
Demander une démo Télécharger maintenant