Apprendimento Automatico Avversariale
Man mano che l’intelligenza artificiale si diffonde nei flussi di lavoro critici per le imprese, , secondo Elastic Insights (2025).
Mentre la maggior parte delle organizzazioni investe molto in sicurezza dei database e controlli infrastrutturali, l’apprendimento automatico avversariale (AML) espone una nuova minaccia, più sottile — che prende di mira gli algoritmi stessi anziché i sistemi circostanti.
Questo articolo esplora come funzionano gli attacchi avversariali, perché sono così pericolosi per le pipeline di IA e come tecnologie come l’approccio di sicurezza basata sui dati di DataSunrise possono rafforzare l’integrità dei modelli dal training alla distribuzione.
Comprendere l’Apprendimento Automatico Avversariale
L’apprendimento automatico avversariale si concentra sulla creazione intenzionale di input che inducono i modelli di IA a commettere errori — dalla errata classificazione delle immagini alla generazione di previsioni false. In sostanza, è la scienza che trasforma l’intelligenza di un modello in una debolezza.
A differenza delle classiche minacce di sicurezza informatica che sfruttano vulnerabilità software, gli attacchi avversariali prendono di mira il nucleo statistico stesso dell’apprendimento automatico. Pochi byte di input perturbato possono manipolare l’output del modello senza alcuna modifica visibile agli esseri umani. Ecco perché difendere i sistemi di IA richiede una fusione di monitoraggio in tempo reale, rilevamento delle anomalie e tracciamento della provenienza dei dati in tutte le fasi di apprendimento.
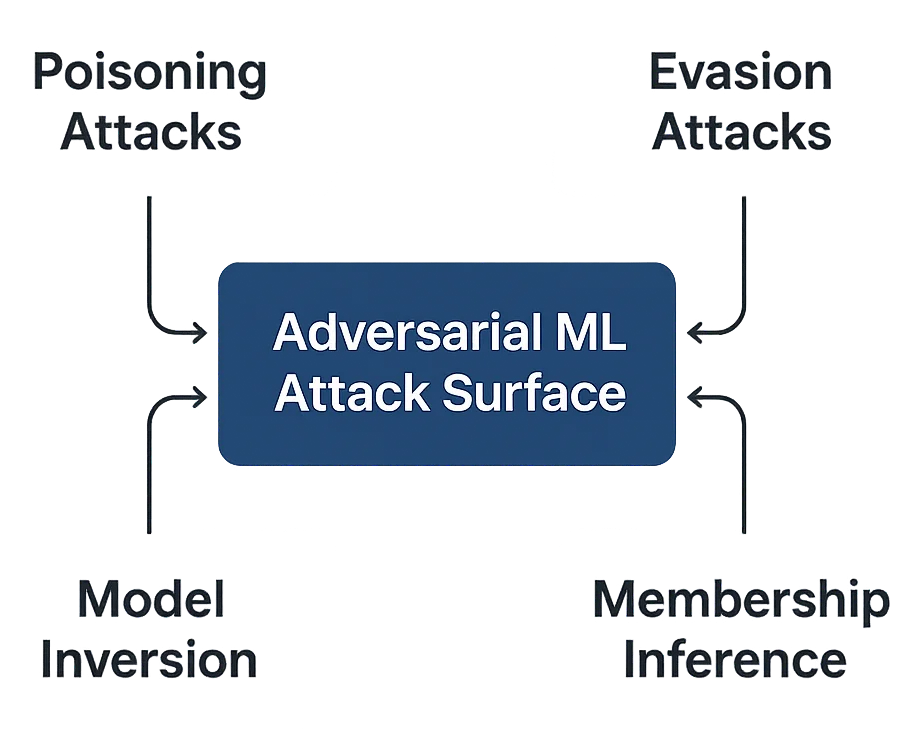
Le Minacce Avversariali Principali
L’ML avversariale può manifestarsi in diverse forme, a seconda di quando e come gli attaccanti interferiscono:
- Attacchi di Avvelenamento – Corruzione dei dataset di training con esempi malevoli. Anche piccole contaminazioni dei dati possono distorcere i modelli e sabotare previsioni critiche per la conformità.
- Attacchi di Evasione – Creazione di input che eludono la rilevazione del modello. Comune nel riconoscimento facciale, nei filtri antispam e nella rilevazione delle frodi.
- Inversione del Modello – Ricostruzione dei dati sensibili di training dagli output del modello, minacciando l’esposizione di informazioni personali identificabili (PII).
- Inferenza di Appartenenza – Indovinare se un determinato record faceva parte del set di training, compromettendo le garanzie di confidenzialità dei dati.
Rilevare in Tempo Reale il Comportamento Avversariale
Gli strumenti di monitoraggio tradizionali non riescono facilmente a riconoscere un input avversariale. Un leggero cambiamento in una matrice di pixel o in un embedding testuale può sembrare normale ma può mandare completamente fuori strada il comportamento del modello. Per questo, i team di sicurezza si affidano a rilevatori basati su ML che segnalano anomalie nel comportamento dei gradienti, nella varianza delle caratteristiche o nell’entropia dell’output.
Di seguito un esempio semplificato di un tale rilevatore:
import numpy as np
class AdversarialDetector:
"""Rileva perturbazioni avversariali basate sull’analisi della deviazione delle caratteristiche."""
def __init__(self, baseline_vector: np.ndarray, threshold: float = 0.15):
self.baseline = baseline_vector
self.threshold = threshold
def detect(self, input_vector: np.ndarray) -> dict:
delta = np.linalg.norm(input_vector - self.baseline) / len(input_vector)
is_adversarial = delta > self.threshold
return {
"threat_detected": is_adversarial,
"risk_score": float(delta * 100),
"severity": "ALTO" if is_adversarial else "BASSO",
"recommendations": ["Ri-addestrare con dati verificati"] if is_adversarial else []
}
Questa routine confronta nuovi input con una base di distribuzioni dati fidate, fornendo indicatori sia quantitativi sia qualitativi per l’analisi comportamentale a valle.
Rafforzare i Modelli con un Addestramento Difensivo
Oltre alla rilevazione, le organizzazioni devono rafforzare i propri modelli contro future manipolazioni. Una tecnica efficace è il training avversariale — esporre volutamente il modello a campioni modificati durante l’apprendimento affinché impari a resistervi.
class RobustTrainer:
"""Esegue training avversariale per migliorare la resilienza del modello."""
def __init__(self, model, epsilon: float = 0.1):
self.model = model
self.epsilon = epsilon
def perturb(self, x):
noise = np.random.uniform(-self.epsilon, self.epsilon, x.shape)
return np.clip(x + noise, 0, 1)
def train(self, data, labels):
adv_data = self.perturb(data)
combined = np.vstack((data, adv_data))
combined_labels = np.concatenate((labels, labels))
self.model.fit(combined, combined_labels)
return {"status": "Modello addestrato con robustezza avversariale"}
Best Practice per la Sicurezza dell’Apprendimento Automatico Avversariale
Per le Organizzazioni
- Sicurezza del Ciclo di Vita dei Dati – Stabilire un monitoraggio continuo della storia delle attività per individuare anomalie precoci.
- Definire la Governance del Modello – Definire responsabilità e policy in linea con i quadri normativi quali GDPR e HIPAA.
- Audit Completo – Abilitare tracciamenti di audit trail unificati per verificare l’origine e l’integrità del training del modello.
- Formazione degli Stakeholder – Assicurare che i data scientist comprendano le implicazioni di sicurezza del rumore avversariale.
Per i Team Tecnici
- Utilizzare Strumenti di IA Spiegabile – Interpretare gli output del modello e rintracciare anomalie tramite cruscotti di sicurezza.
- Integrare la Validazione Continua – Automatizzare i controlli nelle pipeline usando proxy inversi per filtrare le richieste.
- Applicare Accesso Basato su Ruoli – Limitare l’accesso all’addestramento e all’inferenza del modello con il controllo degli accessi basato sui ruoli (RBAC).
- Crittografare i Dataset – Usare crittografia a livello di campo per prevenire il recupero non autorizzato dei dati.
DataSunrise: Protezione Completa contro l’Apprendimento Automatico Avversariale
DataSunrise estende la protezione oltre l’infrastruttura — incorporando la resilienza direttamente nel flusso di lavoro dell’IA. La sua piattaforma offre Orchestrazione della Sicurezza Zero-Touch con Protezione Context-Aware e Rilevamento Autonomo delle Minacce su oltre 50 piattaforme supportate.
Funzionalità Chiave
- Rilevamento Anomalie Potenziato da ML – Correlazione di comportamenti anomali di gradienti e caratteristiche.
- Tracciamento della Provenienza dei Dati – Garantisce che ogni record usato nel training sia verificabile.
- Autopilota per la Conformità – Mappa operazioni di modelli e dati ai controlli normativi.
- Framework Unificato di Audit – Collega log, eventi e attività utente in un unico cruscotto.
- Motore di Mascheramento Adattivo – Nasconde dinamicamente funzionalità ad alto rischio durante la valutazione del modello.
Insieme, questi moduli garantiscono la conformità dell’IA per impostazione predefinita — prevenendo sia manipolazioni avversariali intenzionali sia accidentali negli ambienti enterprise.
Conclusione: Costruire Modelli di IA Affidabili
L’apprendimento automatico avversariale ci ricorda che i sistemi intelligenti possono essere ingannati tanto facilmente quanto gli esseri umani — e che la loro protezione richiede pari intelligenza nella difesa.
Combinando controlli forti sui dati, modelli spiegabili e un’applicazione continua del firewall per database, le organizzazioni possono trasformare la vulnerabilità in vigilanza.
