Wie man die Audit-Datenbankdaten zu AWS S3 auslagert und mit dem AWS Athena-Dienst liest
Audit-Archivierung ist eine optionale Funktion der Aufgabe zur Audit-Datenbankbereinigung in DataSunrise Database Security. Diese Funktion ermöglicht es einem DataSunrise-Installationsadministrator, ältere Audit-Daten zu entfernen und sie im AWS S3-Dienst zu speichern, um eine bessere und kosteneffizientere Methode zur Speicherung abgelaufener Daten bereitzustellen. Mit der Verwendung des AWS Athena-Dienstes können Sicherheitsteams und externe Prüfer die für Audits und Vorfalluntersuchungen benötigten historischen Daten untersuchen. Darüber hinaus ermöglicht die Nutzung der Audit-Archivierung DataSunrise-Kunden die Verwaltung größerer Datensätze von auditfähigen Ereignissen, ohne alles in der einzigen Audit-Speicher-Datenbank zu speichern und längere Berichtszeiten zu erleben. Zudem ist die Verwendung von S3 für kalte Daten eine kosteneffizientere Lösung, die dazu beitragen kann, das Budget für das Projekt zu optimieren, indem die Größe der Audit-Datenbank unter Kontrolle gehalten wird.
Für die Audit-Archivierung stellt das DataSunrise-Team ein spezielles Skript für Linux-Implementierungen bereit, das angepasst werden kann, um die entfernten Daten an einem anpassbaren S3-Standort abzulegen. Es ist Teil des standardmäßigen DataSunrise-Installationspakets, sodass Sie es nicht zusätzlich irgendwo herunterladen müssen.
Dieser Artikel führt Sie durch den Prozess des Setups der Audit-Bereinigungsaufgabe, des Auslagerns der entfernten Daten an den S3-Bucket-Standort Ihrer Wahl und des Einrichtens der Umgebung in AWS Athena für die Forensik.
Konfigurieren einer Bereinigungsaufgabe für Audit-Daten mit der Audit-Archivierungsoption
- Öffnen Sie die DataSunrise-Web-UI und navigieren Sie zu Konfiguration → Periodische Aufgaben. Klicken Sie auf die Schaltfläche Neue Aufgabe und geben Sie die allgemeinen Informationen wie Name, Aufgabentyp (z. B. Bereinigen von Audit-Daten) an und wählen Sie den Server aus, auf dem die Aufgabe ausgeführt werden soll, falls Sie einen Cluster von DataSunrise-Knoten verwenden.
- Setzen Sie die Archivierungsoptionen im Abschnitt Bereinigung von Audit-Daten:
- Überprüfen Sie die Option Zum Archivieren Entfernte Daten, bevor Sie bereinigen.
- Geben Sie den Pfad des Archivordners an, in dem die Audit-Daten vorübergehend gespeichert werden sollen, bevor sie in S3 verschoben werden.
- Geben Sie den Pfad zum Skript an, das die Daten zu AWS S3 hochlädt, indem Sie das Eingabefeld “Befehl nach der Archivierung ausführen” verwenden. Standardpfad – /opt/datasunrise/scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
(erforderlich) - Geben Sie zusätzliche Parameter für das Skript an, um das Verhalten anzupassen (siehe unten für die Option-Skriptargumente).
- Passen Sie die Aufgabenfrequenz an im Abschnitt “Startfrequenz”, Sie können festlegen, wie oft die Aufgabe basierend auf den Anforderungen der Organisation für die Aufbewahrung und Archivierung von Audit-Daten ausgeführt werden soll (z. B. täglich, wöchentlich, monatlich).
- Speichern Sie die Aufgabe, nachdem Sie alle notwendigen Einstellungen konfiguriert haben.
- Starten Sie die Aufgabe manuell oder automatisch. Wenn der Benutzer die Aufgabe konfiguriert hat, manuell zu starten, kann er sie starten, indem er die Aufgabe auswählt und auf Jetzt starten klickt. Falls sie basierend auf einem Zeitplan gestartet wird, läuft sie automatisch zu den angegebenen Zeiten.
- Nach Ausführung der Aufgabe wird ein Archivordner im Dateisystem des DataSunrise-Servers erstellt, auf dem die Aufgabe ausgeführt wurde (bei Linux-Distributionen ist der Standardpfad /opt/datasunrise/).
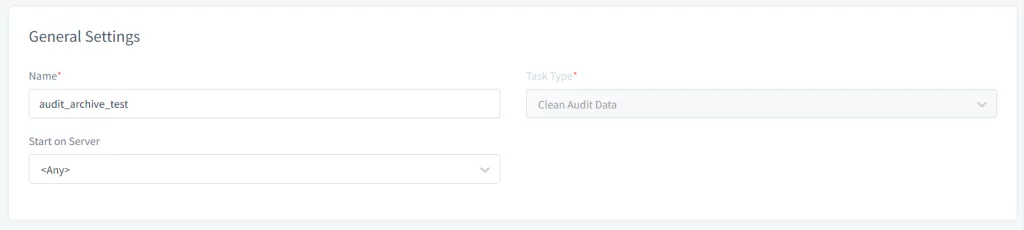
Bild 1. Allgemeine Einstellungen
Hinweis: Wenn Sie DataSunrise auf AWS ECS Fargate betreiben, verwenden Sie stattdessen das Skript ecs_upload_ds_audit_to_aws_s3.sh im gleichen Verzeichnis.
Hinweis: Sie können Pfade relativ zum DataSunrise-Installationsordner angeben (d. h. ./scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
Hinweis: Wenn Sie den Standardnamen des Archivordners angeben, den das Skript erwartet (d. h. /ds-audit-folder), müssen Sie ihn nicht in den Skriptargumenten angeben.
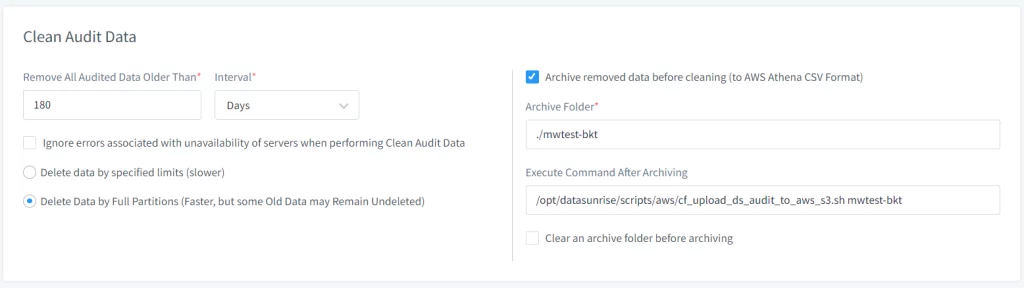
Bild 2. Zusätzliche Befehle für die Bereinigungsaufgabe
Bild 3. Die Aufgabe starten
Hinweis: Die obigen Schritte können auch verwendet werden, um die Aufbewahrung von Audit-Daten in DataSunrise zu verwalten. Benutzer können die Funktion „Periodisches Bereinigen von Audit-Daten“ nutzen, um regelmäßig veraltete Audit-Daten zu entfernen. Dies gewährleistet die Effizienz des DataSunrise-Servers, indem eine Überlastung der Speicher mit veralteten Daten verhindert wird.
Das Skript zur Hochladung archivierter Audit-Daten
Um den Archivordner in einen AWS S3-Bucket hochzuladen, verwenden Sie das von DataSunrise bereitgestellte Skript, das sich im Ordner
Um einen Bucket zu definieren, in den archivierte Audit-Daten geladen werden sollen, geben Sie den Namen Ihres AWS S3-Buckets ohne das s3://-Schema an:
./scripts/aws/cf_upload_ds_audit_to_aws_s3.sh datasunrise-audit-archive
Um den Archivierungsprozess anzupassen, können Sie die folgenden optionalen Flags verwenden:
- –-archive-folder: Geben Sie Ihren eigenen Pfad auf dem DataSunrise-Server an, um die archivierten Audit-Daten-Dateien abzulegen. Standardmäßig wird der Ordner ds-audit-archive an der /opt/datasunrise/-Stelle erstellt. Sie müssen diese Option nicht angeben, wenn Sie den Audit-Archivordner als ds-audit-archive innerhalb des DataSunrise-Installationsverzeichnisses definieren.
- –folder-in-bucket: Geben Sie Ihr eigenes Präfix an, um die Audit-Daten abzulegen. Standardmäßig entlädt das Skript die Daten zum Präfix
/ds-audit-archive . - –predefined-credentials: Falls Sie DataSunrise außerhalb von AWS betreiben, benötigen Sie entweder eine Anmeldeinformationsdatei oder das ACCESS/SECRET Key-Paar für den IAM-Benutzer, der berechtigt ist, auf den gewünschten S3-Bucket zuzugreifen, um Daten auf S3 hochladen zu können. Erfordert keinen Eingaben.
Hinweis: Die Ordnergröße wird während der Audit-Entladung überwacht, und wenn sie einen bestimmten Schwellenwert überschreitet, wird der Befehl ausgeführt. Wenn kein Skript angegeben ist, tritt ein Fehler auf, wenn der Schwellenwert überschritten wird. Der Schwellenwert wird mit dem zusätzlichen Parameter “AuditArchiveFolderSizeLimit” festgelegt und hat standardmäßig einen Wert von 1 GB. Ein Benutzer kann einen Archivordner vorab mit der Option “Ein Archivordner vor dem Archivieren löschen” bereinigen.
Audit-Archivordnerstruktur
Die Struktur des Archivordners, in dem DataSunrise Daten speichert, folgt normalerweise einem hierarchischen Format, das nach Datum organisiert ist. Diese Organisation hilft beim effizienten Management der Daten und erleichtert das Auffinden spezifischer Audit-Datensätze basierend auf dem Datum. Hier ist eine allgemeine Übersicht über die Struktur:
Allgemeine Ordnerstrukturvorlage
Basiskatalog: /opt/datasunrise/ds-audit-archive/
└── Jahr: {YYYY}/
└── Monat: {MM}/
└── Tag: {DD}/
└── Audit Dateien: audit_data_{YYYY}-{MM}-{DD}.csv.gz
Sobald die Audit-Daten zu S3 hochgeladen sind, bleibt die Struktur genauso erhalten, wie sie auf dem DataSunrise-Server eingerichtet wurde:
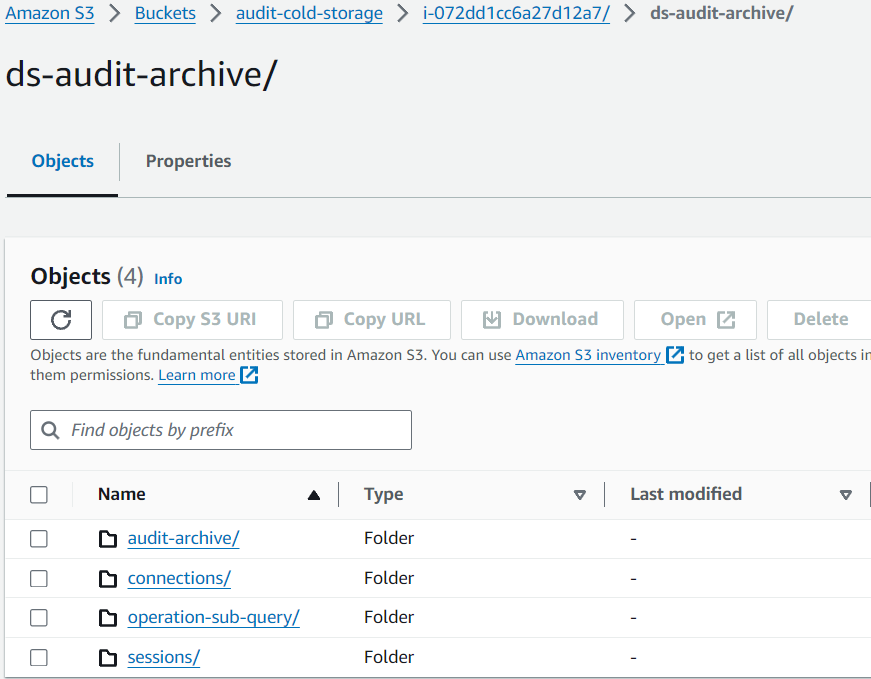
Bild 4. Daten im Amazon S3-Bucket
Verwendung von AWS Athena zum Lesen archivierter Audit-Daten von S3
Sobald die Audit-Daten zu S3 hochgeladen sind, können Sie das Audit-Datenbankschema im AWS Athena-Dienst für weitere Analysen erstellen. Gehen Sie zu AWS Athena in der AWS-Managementkonsole, um eine Datenbank und Tabellen einzurichten, um Ihre archivierten Daten zu lesen. Um den AWS Athena-Dienst vollständig nutzen zu können, empfehlen wir die Verwendung der AmazonAthenaFullAccess AWS Managed IAM-Policy für den erstellten IAM-Benutzer, der mit den archivierten Audit-Daten arbeiten soll.
Erstellen von Tabellen für das Audit-Archiv in AWS Athena
Die SQL-Skripte nehmen Folgendes für die LOCATION-Klausel der CREATE EXTERNAL TABLE-Befehle an:
– Der Name des S3-Buckets ist datasunrise-audit
Die DDL-SQL-Datei für die Tabellen des AWS Athena-Audit-Archivs ist ebenfalls in der DataSunrise-Distribution mit dem Standardpfad verfügbar: /opt/datasunrise/scripts/aws/aws-athena-create-audit-archive-tables.sql.
CREATE DATABASE IF NOT EXISTS datasunrise_audit;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.audit_archive (
operations__id STRING,
operations__session_id STRING,
operations__begin_time STRING,
operations__end_time STRING,
operations__type_name STRING,
operations__sql_query STRING,
operations__exec_count STRING,
sessions__user_name STRING,
sessions__db_name STRING,
sessions__service_name STRING,
sessions__os_user STRING,
sessions__application STRING,
sessions__begin_time STRING,
sessions__end_time STRING,
connections__client_host_name STRING,
connections__client_port STRING,
connections__server_port STRING,
connections__sniffer_id STRING,
connections__proxy_id STRING,
connections__db_type_name STRING,
connections__client_host STRING,
connections__server_host STRING,
connections__instance_id STRING,
connections__instance_name STRING,
operation_rules__rule_id STRING,
operation_rules__rule_name STRING,
operation_rules__chain STRING,
operation_rules__action_type STRING,
operation_exec__row_count STRING,
operation_exec__error STRING,
operation_exec__error_code STRING,
operation_exec__error_text STRING,
operation_group__query_str STRING,
operations__operation_group_id STRING,
operations__all_exec_have_err STRING,
operations__total_affected_rows STRING,
operations__duration STRING,
operations__type_id STRING,
connections__db_type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/audit-archive/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- Die nächste Abfrage lädt Partitionen, um Abfragen auf Daten abzurufen.
MSCK REPAIR TABLE datasunrise_audit.audit_archive;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.sessions (
partition_id STRING,
id STRING,
connection_id STRING,
host_name STRING,
user_name STRING,
scheme STRING,
application STRING,
thread_id STRING,
process_id STRING,
begin_time STRING,
end_time STRING,
error_str STRING,
params STRING,
db_name STRING,
service_name STRING,
os_user STRING,
external_user STRING,
domain STRING,
realm STRING,
sql_state STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/sessions/'
TBLPROPERTIES ('has_encrypted_data'='false','skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.sessions;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.connections (
partition_id STRING,
id STRING,
interface_id STRING,
client_host STRING,
client_port STRING,
begin_time STRING,
end_time STRING,
client_host_name STRING,
instance_id STRING,
instance_name STRING,
proxy_id STRING,
sniffer_id STRING,
server_host STRING,
server_port STRING,
db_type_id STRING,
db_type_name STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/connections/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.connections;
----------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.operation_sub_query (
operation_sub_query__operation_id STRING,
operation_sub_query__session_id STRING,
operation_sub_query__type_name STRING,
operations__begin_time STRING,
operation_sub_query__type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/operation-sub-query/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.operation_sub_query;
----------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.col_objects (
operation_id STRING,
session_id STRING,
obj_id STRING,
name STRING,
tbl_id STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/col-objects/' -- Pfad zum S3-Ordner
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.col_objects;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.tbl_objects (
tbl_objects__operation_id STRING,
tbl_objects__session_id STRING,
tbl_objects__obj_id STRING,
tbl_objects__sch_id STRING,
tbl_objects__db_id STRING,
tbl_objects__tbl_name STRING,
tbl_objects__sch_name STRING,
tbl_objects__db_name STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/tbl-objects/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.tbl_objects;
Abfragen der Daten in der AWS Athena-Konsole mit Standard-SQL-Abfragen:
--SELECT-Ausführung gegen die audit_archive-Tabelle mit Filtern nach Jahr, Monat und Tag
SELECT * FROM audit_archive WHERE year = '2024' and month = '05' and day = '16';
--Abrufen von Daten aus mehreren Tabellen über die JOIN-Klausel
SELECT
r.operations__type_name,
s.operation_sub_query__type_name,
r.operations__sql_query
FROM audit_archive AS r
JOIN operation_sub_query AS s
ON
r.operations__id = s.operation_sub_query__operation_id
AND
r.operations__session_id = s.operation_sub_query__session_id;
–-Extrahieren von 100 Zeilen ohne angewendete Filter
select * from audit_archive LIMIT 100;
Bild 5. Audit-Archiv
Fazit
Eine lange Aufbewahrungsdauer für sensible Daten wie auditierte Ereignisse kann eine echte Herausforderung und eine zusätzliche Belastung des Budgets bei der Verwaltung großer Datensätze innerhalb der Datenbankdateien sein. Die Audit-Archivierung von DataSunrise bietet eine effiziente und sichere Lösung, um ältere Daten lesbar zu halten, die Datenbankspeicherebene zu entlasten und unseren Kunden eine resiliente und kosteneffiziente Lösung basierend auf den AWS S3- und Athena-Diensten zu bieten, um alte Daten innerhalb Ihrer Organisation zu behalten und für Audits und die Compliance zugänglich zu machen.