
Was ist Datenmaskierung?
Was ist Datenmaskierung?
Um Datenmaskierung zu verstehen, ist es wichtig, sie im weiteren Kontext zunehmender Datenschutzverletzungen und immer strengerer Datenschutzvorschriften zu betrachten. Organisationen müssen heute sensible Informationen schützen und sie gleichzeitig für wesentliche Geschäftsprozesse nutzbar halten. Laut aktueller Gartner-Studie ist Datenmaskierung zu einem grundlegenden Element moderner datenschutzverstärkender Technologien geworden – insbesondere in Umgebungen, in denen Daten intern zwischen Teams, externen Partnern und Cloud-Plattformen geteilt werden.
Datenmaskierung ersetzt echte Datenwerte durch realistische, aber fiktive Versionen. So wird sichergestellt, dass sensible Informationen vor unbefugter Offenlegung geschützt bleiben, während gleichzeitig eine sichere Nutzung der Daten für Entwicklung, Tests, Analysen und die Zusammenarbeit mit Dritten möglich ist.
Um den steigenden Datenschutzanforderungen gerecht zu werden und Compliance-Anforderungen wie DSGVO, HIPAA und PCI DSS zu erfüllen, benötigen Organisationen skalierbare, richtliniengesteuerte Maskierungslösungen. DataSunrise bietet sowohl statische als auch dynamische Maskierung, unterstützt von intelligenten Regeln, die sich automatisch basierend auf Benutzerrollen, Kontext und Zugriffsrechten anpassen.
Bei effektiver Umsetzung verändert Datenmaskierung die Art und Weise, wie sensible Informationen verwaltet werden – unterstützt sichere Zusammenarbeit, reduziert Insider-Bedrohungen und gewährleistet Compliance über komplexe, verteilte Datenökosysteme hinweg.
Warum Datenmaskierung in modernen Sicherheitsstrategien wichtig ist
Moderne Datenschutzmaßnahmen gehen weit über traditionelle Verschlüsselungsansätze hinaus. Datenmaskierung spielt eine entscheidende Rolle bei der Durchsetzung von Prinzipien der minimalen Rechtevergabe und stellt sicher, dass sensible Informationen auch dann geschützt bleiben, wenn autorisierte Benutzer ohne vollständige Dateneinsicht darauf zugreifen.
Egal ob unter der DSGVO in Europa, HIPAA im Gesundheitswesen oder PCI DSS im Finanzsektor: Organisationen müssen proaktive Datenschutzmaßnahmen nachweisen. Durch umfassende Maskierungsrichtlinien können Teams mit realistischen Datensätzen arbeiten, analysieren und testen, ohne dass originale sensible Werte unbefugten Personen zugänglich gemacht werden.
Ohne Maskierung könnten gutmeinende interne Nutzer Einsicht in vertrauliche Daten erhalten, die sie nicht benötigen – was das Risiko von Datenlecks, Missbrauch oder regulatorischer Nichteinhaltung erhöht. Durch die Integration von Maskierung in alltägliche Arbeitsabläufe reduziert sich die Datenexposition in Entwicklungs-Pipelines, Analysetools und bei Interaktionen mit Anbietern erheblich – ohne Produktivität oder Datenqualität zu beeinträchtigen.
| Vorschrift | Abschnitt | Maskierungsanforderung |
|---|---|---|
| DSGVO | Art. 32 | Pseudonymisierung personenbezogener Daten |
| PCI DSS 4.0 | 3.4 | PAN unlesbar machen (tokenisieren, maskieren) |
| HIPAA | §164.514(b) | Entfernung von 18 PHI-Kennzeichen |
| DORA | Art. 9 | Schutz der für Resilienztests verwendeten Datensätze |
Dynamische Maskierung ermöglicht sicheren Zugriff auf produktive Live-Systeme, während statische Maskierung bereinigte Datensätze erzeugt, die perfekt für Trainingsumgebungen, Zusammenarbeit mit Anbietern oder Qualitätssicherungstests geeignet sind. DataSunrise vereinfacht beide Methoden durch intuitive Konfigurationsoberflächen und robuste Unterstützung komplexer Datenbankschemata und hybrider Cloud-Einsätze.
Datenmaskierung – Zusammenfassung, Schritte und Schnellchecks
Zusammenfassung
- Zweck: Begrenzung der Offenlegung sensibler Werte bei gleichzeitiger Erhaltung der Datennützlichkeit.
- Modi: dynamisch (zur Abfragezeit), statisch (bereinigte Kopien), in-place (nicht-produktive Umgebungen).
- Passend zu: DSGVO-Pseudonymisierung, HIPAA-De-Identifizierung, PCI DSS-Maskierung.
Implementierungsschritte
- Entdecken und klassifizieren von Feldern (PII/PHI/PCI) über alle Quellen hinweg.
- Definition von Rollen und erforderlichen Sichtbarkeitsstufen.
- Auswahl des Modus je nach Anwendungsfall (dynamisch für Produktion; statisch für Entwicklung/Test/Anbieter).
- Auswahl der Algorithmen (Schwärzung, Substitution, FPE, Tokenisierung) entsprechend Spaltentyp.
- Konfiguration der Regeln auf Schema-/Tabellen-/Spaltenebene; Erhaltung der referenziellen Integrität.
- Validierung in Staging; Überprüfung von Anwendungsverhalten und Analysegenauigkeit.
- Überwachung der Performance und Anpassung des Umfangs zur Kontrolle der Latenz.
- Dokumentation der Richtlinien; Planung periodischer Überprüfungen bei Schemaänderungen.
Algorithmusauswahl
| Datenart | Empfohlener Ansatz | Hinweise |
|---|---|---|
| PAN / Kartendaten | Maskiere BIN + letzte 4 Ziffern / Tokenisierung | PCI DSS Anforderung 3.4 |
| E-Mails / Benutzernamen | Format-erhaltende Substitution | Behalte Domäne/Benutzerstruktur für Nutzerfreundlichkeit |
| Freitext-PII | Wörterbuch-/Regex-Substitution | Logs, Kommentare, JSON-Blobs durchsuchen |
| Datumsangaben / Beträge | Rauschzugabe / Gruppierung | Erhaltung von Reihenfolge/Statistik |
| IP-Adressen / Standorte | Generalisierung / Randomisierung | Region ggf. erhalten |
Schnellchecks
- Bleiben maskierte Spalten für Anwendungslogik und Berichte gültig?
- Sind Transformationen für nicht-berechtigte Nutzer irreversibel?
- Wird die referenzielle Integrität zwischen Tabellen gewahrt?
- Bleibt die Latenz auch unter Last im Ziel-SLO?
Gängige Anwendungsfälle für Datenmaskierung
Organisationen setzen Datenmaskierung in vielfältigen Szenarien ein, um Sicherheit zu gewährleisten und gleichzeitig Geschäftsprozesse zu ermöglichen:
- Zusammenarbeit mit Anbietern: Teilen von Datensätzen mit Drittpartnern bei gleichzeitiger Wahrung der Vertraulichkeit von Kunden- und Wettbewerbsinformationen. Datenmaskierung stellt sicher, dass externe Anbieter, Auftragnehmer und Dienstleister ihre Aufgaben effektiv erledigen können, ohne Zugriff auf unmaskierte sensible Daten zu erhalten, wodurch das Risiko von Sicherheitsvorfällen in weniger kontrollierten externen Umgebungen reduziert wird.
- Fehlerprävention: Schutz vor unbeabsichtigter Offenlegung durch Bedienerfehler, Verwaltungsfehler oder Systemfehlkonfigurationen. Maskierung dient als zusätzliche Sicherheitsebene, sodass selbst bei unsachgemäßem Export, Logging oder Zugriff sensible Felder unlesbar bleiben und die Auswirkungen menschlicher Fehler minimiert werden.
- Entwicklung und Test: Bereitstellung realistischer Datensätze für Anwendungstests, Machine Learning-Training und Performance-Optimierung ohne Datenschutzrisiken. Maskierung ermöglicht es Teams, strukturell korrekte, produktionsnahe Daten zu verwenden, unterstützt Debugging, Lasttests, Modelltraining und Integrationsprüfungen, ohne echte Kundenidentitäten oder regulierte Felder offenzulegen.
- Analytik und Berichterstattung: Ermöglicht Datenwissenschaftlern und Analysten die Arbeit mit produktionsähnlichen Daten bei gleichzeitiger Einhaltung von Datenschutzvorschriften. Maskierte Datensätze bewahren wichtige statistische Eigenschaften und Zusammenhänge, sodass hochwertige Insights, Dashboards und Vorhersagen möglich sind, ohne personenbezogene Daten zu exponieren oder Standards wie DSGVO, HIPAA oder PCI DSS zu verletzen.
Beispiele maskierter Daten
Maskierungsstrategien variieren stark je nach Datenklassifizierungsvorgaben, Benutzerberechtigungen und spezifischen Compliance-Richtlinien. Einige Systeme verlangen vollständige Schwärzung, andere erlauben format-erhaltende Substitution zur Wahrung der Datennützlichkeit. DataSunrise unterstützt beide Ansätze für strukturierte Datenbanken und unstrukturierte Datenbestände.
-- Vor der Maskierung: 4024-0071-8423-6700 -- Nach der Maskierung: XXXX-XXXX-XXXX-6700
| Maskierungsmethode | Originaldaten | Maskierte Daten |
|---|---|---|
| Kreditkartenmaskierung | 4111 1111 1111 1111 | 4111 **** **** 1111 |
| E-Mail-Maskierung | [email protected] | j***e@e*****e.com |
| URL-Maskierung | https://www.example.com/user/profile | https://www.******.com/****/****** |
| Telefonnummernmassierung | +1 (555) 123-4567 | +1 (***) ***-4567 |
| IP-Adressen-Randomisierung | 192.168.1.1 | 203.45.169.78 |
| Datum-Randomisierung mit Erhalt des Jahres | 2023-05-15 | 2023-11-28 |
| Maskierung mit benutzerdefinierter Funktion | Secret123! | S****t1**! |
| Wörterbuch-basierte Substitution | John Smith, Software Engineer, New York | Ahmet Yılmaz, Datenanalyst, Chicago |
Implementierungsschritte für Datenmaskierung
Eine erfolgreiche Implementierung von Datenmaskierung erfordert systematische Planung und Durchführung über mehrere Phasen hinweg:
- Datenerkennung und -klassifizierung: Auffinden sensibler Felder in der gesamten Infrastruktur mithilfe von automatisierten Erkennungstools, die PII, Finanzdaten und regulierte Informationen in Datenbanken und Anwendungen identifizieren.
- Richtlinienzuordnung und Rollendefinition: Erstellung umfassender Maskierungsrichtlinien basierend auf Benutzerrollen, Sensitivitätsklassifikationen und branchenspezifischen sowie regionalen regulatorischen Anforderungen.
- Regelkonfiguration und Tests: Definition granularer Maskierungsregeln auf Schema-, Tabellen-, Spalten- oder Datentyp-Ebene, um referenzielle Integrität und konsistente Geschäftslogik sicherzustellen.
- Validierung und Rollout: Umfassende Tests der Maskierungsfunktionalität in Staging-Umgebungen vor Produktionseinführung, um die korrekte Funktion der Anwendungen mit maskierten Datensätzen zu gewährleisten.
- Überwachung und Wartung: Einrichtung kontinuierlicher Überwachung, um die Wirksamkeit der Maskierungsrichtlinien sicherzustellen, während sich Datenstrukturen ändern und neue sensible Datentypen hinzukommen.
Arten der Datenmaskierung
| Algorithmus | Format behalten? | Re-Identifizierungsrisiko | Bestens geeignet für |
|---|---|---|---|
| Schwärzung (Redaction) | Nein | Am niedrigsten | Logs, Screenshots |
| Tokenisierung | Ja | Sehr niedrig* | Zahlungstoken |
| Randomisierung | Optional | Niedrig | PII Datensätze |
| Format-erhaltende Verschlüsselung (FPE) | Ja | Sehr niedrig | Legacy-Anwendungen |
*Vorausgesetzt sind kontrol-lierte detokenisierende Vault-Systeme.
Dynamische Maskierung
Dynamische Maskierung wendet die Datenverschleierung während der Abfrageausführung an, ohne die Quelldaten dauerhaft zu verändern. Dieser Ansatz bietet eine ideale Echtzeit-Zugriffssteuerung in Multi-User-Produktionssystemen, in denen die Datenansicht dynamisch je nach Benutzerrolle und Zugriffskontext variieren muss.
CREATE VIEW masked_customers AS
SELECT
id,
name,
CASE
WHEN current_user = 'admin_user' THEN credit_card
ELSE regexp_replace(credit_card, '^\d{4}-\d{4}-\d{4}-(\d{4})$', 'XXXX-XXXX-XXXX-\1')
END AS credit_card
FROM customers;
Statische Maskierung
Statische Maskierung erstellt dauerhaft bereinigte Kopien von Produktionsdatenbanken, die sicheren Datenaustausch und -verteilung erlauben, ohne anhaltende Datenschutzbedenken. Diese maskierten Datensätze können gefahrlos exportiert, mit externen Partnern geteilt oder für langfristige Analyseprojekte verwendet werden, ohne Datenschutzvorgaben zu verletzen. Besonders wertvoll für ISO 27001-Konformität und regulatorische Auditvorbereitung.
In-Place Maskierung
In-Place-Maskierung verändert Daten direkt innerhalb bestehender Nicht-Produktionsdatenbanken, insbesondere während Pre-Release-Testzyklen oder bei der Vorbereitung von Sandbox-Umgebungen. So wird die Notwendigkeit doppelter Speicherinfrastruktur eliminiert, während Entwickler mit realistischen, aber geschützten Datensätzen arbeiten können.
Wesentliche Anforderungen an Maskierung
Effektive Datenmaskierung muss mehrere kritische Anforderungen erfüllen, um Sicherheit und betriebliche Nutzbarkeit sicherzustellen:
- Erhaltung realistischer Daten: Maskierte Daten müssen wie echte Daten aussehen und sich so verhalten, um eine nahtlose Integration in bestehende Systeme zu ermöglichen. Die ersetzten Werte sollten dieselbe Struktur, dasselbe Format und dieselbe statistische Verteilung wie die Originale aufweisen – z. B. sollten maskierte Kreditkartennummern eine Prüfziffernvalidierung bestehen und maskierte Datumswerte innerhalb logischer Zeiträume bleiben. Diese Realitätsnähe erlaubt Anwendungen, Analysen und Testumgebungen, normal zu funktionieren, ohne Risiko einer Offenlegung sensibler Informationen.
- Irreversible Transformation: Der Maskierungsprozess muss so gestaltet sein, dass eine Wiederherstellung der Originaldaten mathematisch unmöglich ist. Starke Randomisierung und kryptographische Algorithmen verhindern jede Chance auf Reverse Engineering oder musterbasierte Re-Identifizierung. Diese Einweg-Transformation ist ein Eckpfeiler gesetzlicher Anforderungen wie DSGVO und HIPAA, die verlangen, dass anonymisierte Daten nicht auf Personen zurückgeführt werden können.
- Konsistentes Verhalten: Um Datenintegrität zu gewährleisten, sollte die Maskierungslogik für identische Eingaben überall und jederzeit dasselbe maskierte Ergebnis liefern. Wenn beispielsweise eine Kunden-ID in mehreren Tabellen auftaucht, muss sie überall gleich maskiert werden, um relationale Genauigkeit zu bewahren. Diese Konsistenz unterstützt verlässliches Testen, Reporting und Auditing, ohne Sicherheit zu kompromittieren.
- Performanceoptimierung: Durch effektive Maskierung muss ein Gleichgewicht zwischen Sicherheit und Effizienz erreicht werden. Der Prozess sollte minimalen Overhead verursachen und Produktionssysteme oder Analyseabfragen nicht verlangsamen. Optimierte Maskierungsalgorithmen und Parallelverarbeitung ermöglichen es, große Datensätze schnell zu schützen – mit starken Sicherheitskontrollen bei gleichzeitig hoher Systemperformance und guter Nutzererfahrung.
Datenmaskierung in Compliance-Rahmenwerken
Regulatoren definieren Datenmaskierung als Pseudonymisierung, De-Identifizierung oder Datenminimierung. Nachstehend eine Übersicht, wie große Rahmenwerke Anforderungen beschreiben und wie Maskierung diese erfüllt:
| Rahmenwerk | Anforderung | Maskierungs-Übereinstimmung |
|---|---|---|
| DSGVO | Art. 32 — personenbezogene Daten pseudonymisieren oder anonymisieren | Dynamische Maskierung verhindert die Offenlegung roher PII an unberechtigte Nutzer. |
| HIPAA | §164.514 — 18 PHI-Kennzeichen de-identifizieren | Statische Maskierung erzeugt PHI-freie Datensätze für Tests, Schulungen und Forschung. |
| PCI DSS | Req. 3.4 — PAN unlesbar machen außer BIN + letzte 4 Ziffern | Format-erhaltende Maskierung sorgt für Compliance bei Zahlungskartendaten. |
| SOX | Integrität der Finanzberichterstattungsdaten bewahren | Maskierung von Testkopien verhindert Offenlegung sensibler Finanzdaten. |
Durch die Abstimmung der Maskierungsrichtlinien an Compliance-Vorgaben ermöglicht DataSunrise Unternehmen, sensible Informationen zu schützen und gleichzeitig prüferfertige Nachweise über Datenbanken, Cloud- und Hybridumgebungen hinweg zu liefern.
Geschäftliche Ergebnisse der Datenmaskierung
- Reduziertes Risiko von Datenschutzverletzungen: Bis zu 60 % weniger sensible Felder für unbefugte Nutzer sichtbar
- Effizientere Compliance: Auditnachweise werden in Stunden statt Wochen erstellt
- Beschleunigte Abläufe: QA- und Testzyklen verkürzen sich um rund 30 % dank sicherer, produktionsnaher Datensätze
- Geringeres rechtliches Risiko: Direkte Einhaltung von DSGVO-, HIPAA- und PCI DSS-Regelungen
Branchenspezifische Anwendungen
- Finanzen: Maskierung von PANs und PII für PCI DSS- und SOX-Berichterstattung
- Gesundheitswesen: De-Identifizierung von PHI gemäß HIPAA-Datenschutzvorschriften
- SaaS & Cloud: Mandantenfähige Maskierung zur Gewährleistung datenschutzkonformer DSGVO-Trennung
- Einzelhandel: Schutz von Kundendaten in Analytik-Pipelines ohne Verlust von Insights
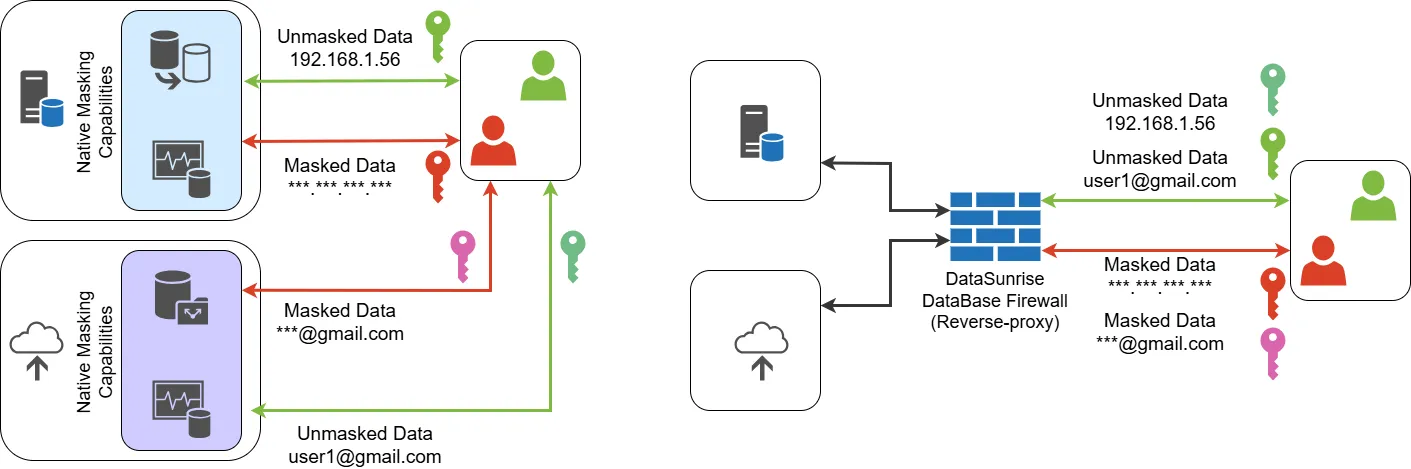
Native Datenmaskierungs-Snippets auf verschiedenen Plattformen
Die meisten Datenbanken bieten nur begrenzte native Maskierungsfunktionen an, die häufig benutzerdefinierten Code oder Erweiterungen erfordern. Nachfolgend Beispiele für SQL Server und Oracle:
SQL Server: Eingebaute dynamische Maskierung
-- Maskierung der Kreditkartenspalte mit teilweiser Offenlegung
CREATE TABLE Customers (
Id INT IDENTITY PRIMARY KEY,
FullName NVARCHAR(100),
CreditCard VARCHAR(19) MASKED WITH (FUNCTION = 'partial(0,"XXXX-XXXX-XXXX-",4)')
);
-- Ergebnis: 4111-2222-3333-4444 → XXXX-XXXX-XXXX-4444
Oracle: Virtual Private Database (VPD) Policy
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'HR',
object_name => 'EMPLOYEES',
policy_name => 'mask_ssn_policy',
function_schema => 'SEC_ADMIN',
policy_function => 'mask_ssn_fn',
statement_types => 'SELECT'
);
END;
/
Beide Beispiele zeigen plattformnative Maskierung, bieten jedoch nicht die Flexibilität, rollenbasierte Regeln über mehrere Datenbanken gleichzeitig anzuwenden.
Maskierung im Compliance-Kontext
Verschiedene Vorschriften definieren Maskierung als Pseudonymisierung, De-Identifizierung oder Datenminimierung. Übliche Anforderungen sind irreversible Transformation bei gleichzeitiger Nutzbarkeit. Nachfolgend eine Kurzübersicht:
| Rahmenwerk | Maskierungsziel | Native Lücke |
|---|---|---|
| DSGVO | Personenbezogene Daten pseudonymisieren | Keine konsistente rollenbasierte Maskierung |
| HIPAA | PHI-Kennzeichen de-identifizieren | Keine Durchsetzung auf Feldebene |
| PCI DSS | PAN maskieren außer BIN & letzte 4 Ziffern | Plattform-spezifisch, nicht einheitlich |
Native Maskierung erfüllt Grundanforderungen, aber einheitliche Plattformen wie DataSunrise bieten sofort umfassenden, übergreifenden Schutz.
Datenmaskierung mit DataSunrise
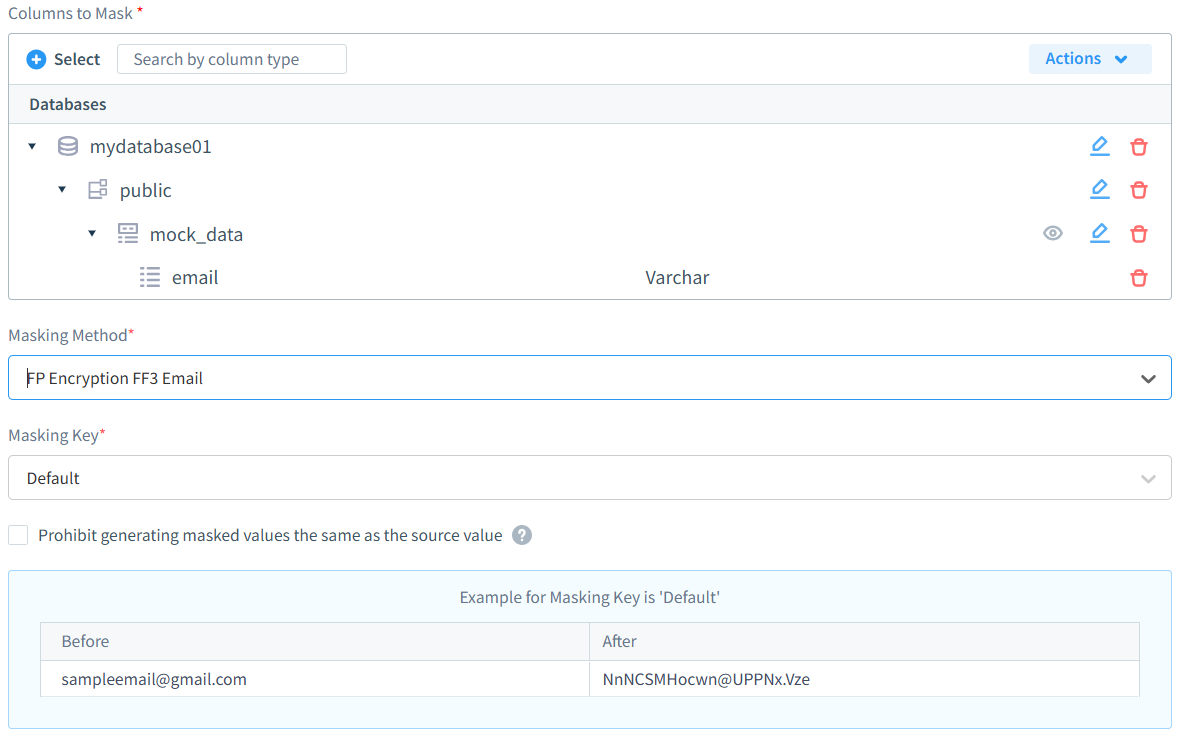
DataSunrise bietet enterprise-taugliche Maskierungsfunktionen, die auf moderne Datenschutzanforderungen zugeschnitten sind:
- Flexible Maskierungsmodi: Umfassende Unterstützung für Echtzeit-Dynamikmaskierung und Offline-statische Maskierung, sodass Organisationen optimale Ansätze je nach Anwendungsfall wählen können.
- Intelligente Zugriffskontrollen: Rollenbewusste Maskierungsrichtlinien und format-erhaltende Algorithmen, die Datenverwendbarkeit gewährleisten und gleichzeitig strengen Datenschutz durchsetzen.
- Enterprise-Integrationen: Nahtlose Einbindung in bestehende IAM-Systeme, SIEM-Plattformen und Richtlinien-Durchsetzungssysteme zur Optimierung von Sicherheitsoperationen und Compliance-Berichten.
- Compliance-Automatisierung: Eingebaute Audit-Logging- und Reporting-Funktionalität speziell für DSGVO, PCI DSS, HIPAA und SOX Compliance.
- Skalierbare Architektur: Unterstützung für cloud-native, hybride und Legacy-Datenbankumgebungen mit minimalen Performanceeinbußen und hoher Verfügbarkeit.
Skalierung der Datenmaskierung in komplexen Umgebungen
Mit wachsender Komplexität von Architekturen muss Datenmaskierung über hybride Clouds, verteilte Microservices und gemischte Workloads skalieren. Organisationen kämpfen oft damit, eine konsistente Maskierungslogik über relationale Datenbanken, NoSQL-Systeme und sogar unstrukturierte Speicher wie Objektspeicher oder Logs zu gewährleisten.
- Plattformübergreifende Richtliniendurchsetzung: Einheitliche Maskierungsregeln über PostgreSQL, Oracle, SQL Server, MongoDB und Amazon S3 hinweg – für einheitliches Verhalten und Compliance unabhängig von der Backend-Technologie.
- Unterstützung für unstrukturierte und semi-strukturierte Daten: Maskierung sensibler Werte in JSON, XML, Logdateien und nutzergenerierten Inhalten mittels regex-basierter oder wörterbuchbasierter Regeln.
- CI/CD-Maskierungsautomatisierung: Integration der DataSunrise-Maskierungsregeln in DevOps-Pipelines, um zu verhindern, dass unmaskierte sensible Felder in Staging- oder Testumgebungen gelangen.
- Validierungs- und QA-Frameworks: Automatisierte Plausibilitätsprüfungen, um sicherzustellen, dass Maskierungsregeln nachgelagerte Analysen, Reporting-Dashboards oder Anwendungslogik nicht beeinträchtigen.
- Versionsverwaltung und Rollback von Richtlinien: Verwaltung versionierter Maskierungsrichtlinien, die ohne Ausfallzeiten zurückgesetzt oder aktualisiert werden können – entscheidend für agile Umgebungen und regulatorische Änderungen.
Mit diesen Fähigkeiten entwickelt sich Datenmaskierung von einer isolierten Kontrollmaßnahme zu einer dynamischen, zentralisierten Datenschutzeinheit. Statt auf Ad-hoc-Skripte oder isolierte Sicherheitsupdates zu vertrauen, erhalten Teams eine einheitliche Durchsetzungs-Engine, die sich an jede Umgebung anpasst – sei es cloud-native, legacy oder hybrid.
FAQs zur Datenmaskierung
Was ist der Zweck der Datenmaskierung?
Datenmaskierung ersetzt sensible Werte durch realistische Surrogate, um unbefugten Zugriff zu verhindern. Sie ermöglicht die sichere Nutzung von Datensätzen in Tests, Analysen und beim Teilen mit Anbietern, ohne originale Informationen preiszugeben.
Wodurch unterscheidet sich Datenmaskierung von Tokenisierung?
Maskierung erzeugt nicht umkehrbare Surrogate zur Wahrung von Datenschutz und Compliance, während Tokenisierung Werte durch in einem Tresor gespeicherte Tokens ersetzt. Tokenisierung erlaubt reversible Wiederherstellung und ist ideal für Zahlungsabwicklungen unter PCI DSS.
Welche Compliance-Rahmenwerke verlangen Datenmaskierung?
Rahmenwerke wie DSGVO (Pseudonymisierung), HIPAA (De-Identifizierung) und PCI DSS (Maskierung von Karteninhaberdaten) fordern explizit Maskierung oder gleichwertige Schutzmaßnahmen für sensible Felder.
Wann sollte dynamische vs. statische Maskierung verwendet werden?
- Dynamische Maskierung: Echtzeitverschleierung während Abfrageausführung; ideal für produktive Datenbanken mit rollenbasiertem Zugriff.
- Statische Maskierung: Erstellung bereinigter Datenbankkopien; am besten für Entwicklung, Tests und Zusammenarbeit mit Anbietern.
Was sind wichtige Anforderungen für eine wirksame Maskierung?
- Erhaltung realistischer Formate und Geschäftslogik.
- Sicherstellung irreversibler Transformationen.
- Konsistente, reproduzierbare Regeln über alle Umgebungen.
- Geringe Latenz in Produktionssystemen.
Welche Tools vereinfachen eine unternehmensweite Datenmaskierung?
DataSunrise bietet zentrale statische und dynamische Maskierung mit rollenbewussten Richtlinien, regulatorischen Reports und Integration in DevOps-Pipelines – und ersetzt so Ad-hoc-Skripte und Insellösungen.
Die Zukunft der Datenmaskierung
Datenmaskierung hat sich weit über den ursprünglichen Zweck hinaus entwickelt, lediglich Kreditkartennummern oder Kundenkennungen in Testumgebungen zu verbergen. Heute stellt sie eine dynamische, intelligente Ebene der Unternehmenssicherheit dar. Neue Innovationen transformieren die Erkennung, den Einsatz und die Wartung von Maskierungslösungen in großem Maßstab. KI-gestützte Datenerkennung ermöglicht es Systemen nun, sensible Informationen automatisch in strukturierten und unstrukturierten Quellen zu erkennen und zu klassifizieren, während Policy-as-Code-Ansätze Unternehmen erlauben, Maskierungsregeln versioniert, auditierbar und konsistent in CI/CD-Pipelines und DevOps-Workflows anzuwenden.
Große Cloud- und Analyseanbieter integrieren ebenfalls native Maskierungsfunktionen direkt in ihre Ökosysteme, wodurch sensible Daten während des Imports, der Transformation und der analytischen Abfragen geschützt bleiben. Dies umfasst automatisierte Durchsetzung von Maskierung beim Datenfluss zwischen Umgebungen – z. B. zwischen Produktion, Test und KI-Trainings-Pipelines – und reduziert so die Wahrscheinlichkeit von Offenlegung bei großangelegter Verarbeitung.
Als Teil einer einheitlichen Datenschutzstrategie integrieren fortschrittliche Maskierungstechnologien nahtlos Datenbankaktivitätsüberwachung, Compliance-Automatisierung und aufwändige Datenerkennung. Gemeinsam bilden sie ein adaptives Sicherheitsgewebe, das auf sich wandelnde Bedrohungen, regulatorische Anforderungen und Geschäftsanforderungen reagiert. In den kommenden Jahren wird Maskierung nicht mehr nur als Datenschutzkontrolle verstanden, sondern als proaktiver, KI-gesteuerter Schutzmechanismus, der zentrale Bedeutung für moderne Datenverwaltung und sichere digitale Transformation hat.
Native Maskierung vs. DataSunrise
| Funktion | Native Datenbankmaskierung | DataSunrise |
|---|---|---|
| Abdeckung mehrerer Datenbanken | Begrenzt (nur SQL Server, Oracle) | Ja — Oracle, PostgreSQL, MySQL, MongoDB, SQL Server, Cloud-Datenbanken |
| Dynamische vs. statische Optionen | Entweder/oder, je nach Engine | Beides, zentral konfiguriert |
| Durchsetzung von Richtlinien | Manuell, DB-spezifisch | Rollenbewusst, Policy-as-Code, versioniert |
| Compliance-Berichtswesen | Nicht integriert | Vorbereitete Berichte für DSGVO, HIPAA, PCI DSS, SOX |
| Integration | Minimal | IAM, SIEM, CI/CD, cloud-native Pipelines |
Native Maskierung bietet einen Einstieg, aber DataSunrise liefert unternehmensgerechte, plattformübergreifende Kontrollen.
Fazit
Mit der stetig wachsenden Datenmenge in vielfältigen Systemen und Architekturen ist der Schutz sensibler Informationen zu einer strategischen Priorität und regulatorischen Verpflichtung geworden. Datenmaskierung hat sich als eine der zuverlässigsten Methoden etabliert, unbefugten Zugriff auf sensible Felder zu verhindern und dabei persönliche und vertrauliche Daten zu verschleiern, während Datensätze vollständig für legitime Zwecke nutzbar bleiben. Teams können so Analytics durchführen, mit externen Anbietern zusammenarbeiten und Entwicklungs- oder Testaktivitäten ausführen, ohne echte Daten preiszugeben – was Datenschutz stärkt, Compliance unterstützt und die betriebliche Effizienz erhält.
DataSunrise vereinfacht und automatisiert unternehmensweite Maskierung in On-Premises-, Hybrid- und Multi-Cloud-Umgebungen. Die einheitliche Plattform unterstützt den kompletten Datenschutzlebenszyklus – einschließlich Erkennung sensibler Daten, automatischer Klassifizierung, dynamischer und statischer Maskierung, detaillierter Richtlinienverwaltung und prüferfertigem Reporting. Funktionen wie Statische Datenmaskierung bieten eine sichere und konsistente Möglichkeit, geschützte Datensätze für Entwicklung, Analytik und externe Zusammenarbeit vorzubereiten. Mit intelligenter Automatisierung, geringem Performance-Overhead und breiter Kompatibilität mit führenden Datenbanktechnologien ermöglicht DataSunrise Unternehmen, strenge Datenschutzkontrollen durchzusetzen, globale Vorschriften einzuhalten und datengetriebene Innovation sicher zu unterstützen. In einer Welt mit wachsendem Datenexpositionsrisiko ist eine moderne, automatisierte Maskierungsstrategie essentiell für langfristige Sicherheit und Resilienz.
