Datenanonymisierung im Percona Server für MySQL
Datenanonymisierung im Percona Server für MySQL ist keine kosmetische Sicherheitsfunktion. Es handelt sich um eine strukturelle Kontrollmaßnahme, die eingesetzt wird, wenn echte Produktionsdaten außerhalb ihres ursprünglichen Vertrauensbereichs geteilt werden müssen, ohne Identitäten, Zugangsdaten oder regulierte Attribute offenzulegen. In der Praxis reduziert Anonymisierung langfristige Risikoexpositionen und unterstützt direkt umfassendere Datensicherheits-Strategien.
Im Gegensatz zu Auditing oder Aktivitätsverfolgung verändert die Anonymisierung die Daten selbst. Ziel ist es, die Möglichkeit der Re-Identifizierung von Personen dauerhaft zu entfernen, während gleichzeitig genügend Struktur erhalten bleibt, um Tests, Analysen und Entwicklungsabläufe zu ermöglichen. Dieser Ansatz ist besonders wichtig beim Umgang mit personenbezogenen Daten (PII) und anderen regulierten Datenkategorien.
Dieser Artikel erklärt, wie Anonymisierung im Percona Server für MySQL mithilfe nativer SQL-Techniken funktioniert, wo diese Ansätze an ihre Grenzen stoßen und wie zentrale Plattformen die Anonymisierung in einen gesteuerten, wiederholbaren Prozess integrieren, der mit Daten-Compliance-Vorschriften und Sicherheitsanforderungen in Einklang steht.
Was Datenanonymisierung im MySQL-Kontext bedeutet
Datenanonymisierung ist die irreversible Transformation sensibler Werte, sodass Betroffene selbst von Administratoren nicht mehr re-identifiziert werden können. Nach Anwendung fallen anonymisierte Daten in der Regel nicht mehr unter Daten-Compliance-Vorschriften und reduzieren langfristig das Risiko für die Datensicherheit erheblich.
In MySQL-basierten Systemen wird Anonymisierung verwendet, wenn Produktionsdaten für Tests, Analysen oder Speicherung außerhalb kontrollierter Umgebungen wiederverwendet werden. Sie kommt häufig bei persönlichen Identifikatoren, finanziellen Attributen sowie Verhaltens- oder standortbezogenen Daten zum Einsatz, insbesondere in Nicht-Produktions-Workflows und Testdatenmanagement-Szenarien.
Im Unterschied zur Datenbank-Aktivitätsüberwachung oder Zugriffskontrollen basierend auf dem Prinzip der minimalen Rechtevergabe schützt Anonymisierung ruhende Daten, indem sensible Werte vollständig ersetzt werden. Einmal anonymisierte Daten können exportiert, repliziert oder archiviert werden, ohne dass zusätzliche Laufzeitkontrollen erforderlich sind.
Native Techniken zur Datenanonymisierung im Percona Server für MySQL
Der Percona Server für MySQL bietet keine native Anonymisierungs-Engine, kein Richtlinienmodell oder Lifecycle-Kontrollen für anonymisierte Daten. Es gibt keine eingebauten Mechanismen zur Identifikation sensibler Spalten, zur Durchsetzung des Anonymisierungsumfangs oder zur Validierung der Ergebnisse. Daher wird Anonymisierung durch die Kombination von Standard-SQL-Primitiven wie UPDATE, Funktionen, Joins und Hilfstabellen implementiert.
Diese Verfahren können irreversible Transformationen erreichen, basieren jedoch vollständig auf manueller Logik und operativer Disziplin.
Deterministischer Ersatz mit UPDATE-Anweisungen
Die direkteste Anonymisierungstechnik besteht darin, sensible Spalten mit generierten oder synthetischen Werten zu überschreiben. Diese Methode wird häufig verwendet, wenn Kopien von Produktionsdatenbanken für Tests oder Entwicklung vorbereitet werden.
UPDATE customers
SET
email = CONCAT('user_', id, '@example.com'),
phone = NULL,
full_name = CONCAT('Customer_', id),
address = 'REDACTED',
birth_date = NULL;
Dieser Ansatz bewahrt Primärschlüssel und Zeilenanzahl, was hilft, die grundlegende referenzielle Stabilität aufrechtzuerhalten. Nachgelagerte Systeme, die auf Identifikatoren wie id angewiesen sind, funktionieren weiterhin, während echte persönliche Daten entfernt werden.
Diese Methode skaliert jedoch schlecht. Jede Tabelle benötigt ihre eigene Anonymisierungslogik und jede sensible Spalte muss explizit behandelt werden. Wenn später eine neue Spalte hinzugefügt wird, bleibt sie unanonymisiert, sofern das Skript nicht aktualisiert wird. Die referenzielle Konsistenz zwischen verwandten Tabellen muss manuell gepflegt werden, und die Ausführungsreihenfolge wird in Schemata mit gemeinsamen Bezeichnern kritisch. Es gibt keine eingebaute Validierung, um zu bestätigen, dass die Anonymisierung vollständig ist; und nach Ausführung ist ein Rollback ohne Backup-Wiederherstellung unmöglich. Die Originaldaten sind dauerhaft zerstört.
Hash-basierte Anonymisierung
Hashing ersetzt sensible Werte durch fixlange Hashwerte, macht sie unlesbar und bewahrt gleichzeitig die Einzigartigkeit. Dies wird manchmal verwendet, wenn eine Korrelation oder Duplikatserkennung erforderlich ist, ohne die Originalwerte preiszugeben.
UPDATE users
SET
national_id = SHA2(CONCAT(national_id, 'static_salt_123'), 256),
email = SHA2(CONCAT(email, 'static_salt_123'), 256);
Hash-basierte Anonymisierung ist irreversibel, birgt jedoch subtile Risiken. Vorhersehbare oder wiederverwendete Salts schwächen den Schutz und machen Hashes anfällig für Rückschlüsse. Da identische Eingaben stets identische Hashes erzeugen, bleiben Zusammenhänge zwischen Tabellen und Datensätzen sichtbar.
UPDATE payments
SET
payer_id = SHA2(CONCAT(payer_id, 'static_salt_123'), 256);
Die Gewährleistung der Konsistenz über Tabellen hinweg erfordert nun die exakte Anwendung der gleichen Hashing- und Salting-Logik überall. Jede Abweichung zerstört Joins und Korrelationen. Zusätzlich können gehashte Werte je nach Kontext und Re-Identifizierungsrisiko weiterhin als personenbezogene Daten gelten. Mit wachsender Datenmenge wird die Verwaltung von Salts und die konsequente Durchsetzung von Hashing über Umgebungen hinweg fragil und fehleranfällig.
Token-Ersetzungstabellen
Eine kontrolliertere Technik verwendet Nachschlagetabellen, die Originalwerte auf synthetische Tokens abbilden. So bleibt anonymisierte Daten realistisch und verhindert gleichzeitig direkte Identifizierung.
CREATE TABLE token_emails (
original_email VARCHAR(255),
token_email VARCHAR(255)
);
INSERT INTO token_emails VALUES
('[email protected]', '[email protected]'),
('[email protected]', '[email protected]');
Die Anonymisierung erfolgt dann durch join-basierte Ersetzung:
UPDATE orders o
JOIN token_emails t
ON o.email = t.original_email
SET
o.email = t.token_email;
Dieser Ansatz verbessert die Datenqualität für Tests und Analysen, erhöht jedoch erheblich den administrativen Aufwand. Die Token-Generierung muss Kollisionen vermeiden, Tokens müssen in allen zugehörigen Tabellen konsistent bleiben und das Wiederverwenden muss sorgfältig kontrolliert werden, um Rückschlüsse zu verhindern. Mit der Zeit werden die Token-Tabellen selbst sensible Assets, die Schutz, Rotation und Zugriffskontrolle erfordern. Ohne zentrale Governance wird das Lifecycle-Management der Tokens schnell schwer zu pflegen und zu auditieren.
Zentrale Datenanonymisierung mit DataSunrise
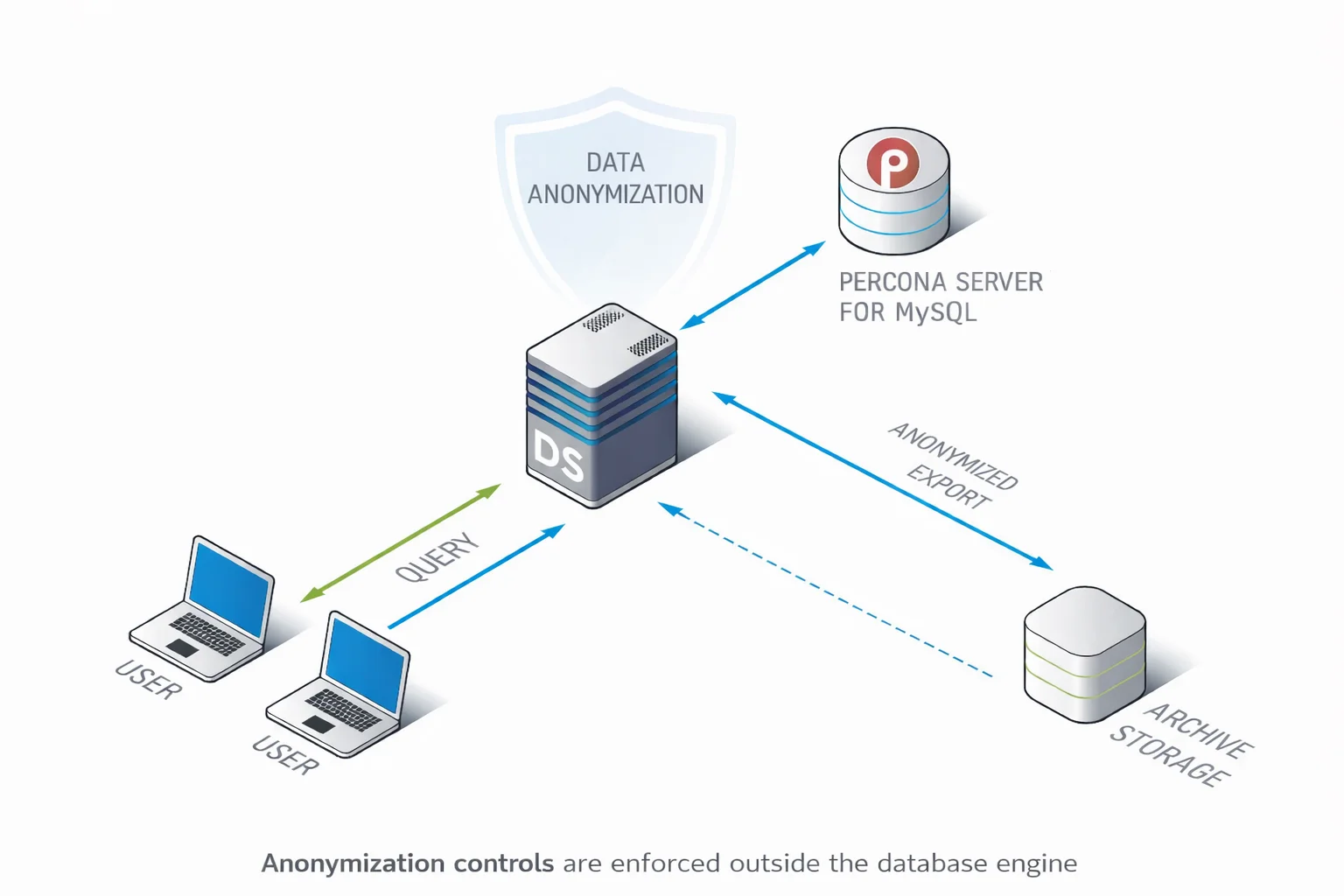
DataSunrise betrachtet Datenanonymisierung als einen gesteuerten Sicherheitsprozess und nicht als destruktive Einzel-SQL-Operation. Anstatt irreversible Logik in Datenbankschemata einzubetten oder fragile Anonymisierungsskripte zu pflegen, werden Anonymisierungsregeln zentral definiert und konsequent über Percona Server für MySQL-Umgebungen hinweg durchgesetzt.
Dieser Ansatz trennt Anonymisierung von der Datenbankstruktur. Die Datenbanken bleiben unverändert, während Anonymisierung als kontrollierte Transformationsebene angewandt wird. Dadurch können dieselben Richtlinien über Produktionsreplikate, Testumgebungen, Exporte und Archive hinweg ohne Umschreiben von SQL oder Risiko inkonsistenter Ergebnisse verwendet werden.
Zentrale Anonymisierung bietet zudem Sichtbarkeit und Kontrolle, die native Ansätze vermissen lassen. Administratoren können sehen, welche Daten anonymisiert wurden, wie sie transformiert wurden und wo diese Transformationen erfolgten.
Erkennung sensibler Daten
Der Prozess beginnt mit automatisierter Erkennung sensibler Daten. Anstatt sich auf manuelle Schemaüberprüfungen zu verlassen, scannt DataSunrise Datenbanken, um personenbezogene Daten, finanzielle Attribute, Zugangsdaten und andere regulierte Felder zu identifizieren. Die Erkennung arbeitet auf Spaltenebene und berücksichtigt sowohl Namensmuster als auch Dateninhalt, wodurch das Risiko versteckter Identifier reduziert wird.
Dieser Schritt legt den verifizierten Geltungsbereich der Anonymisierung fest und stellt sicher, dass Schutz auf alle relevanten Daten angewendet wird, anstatt auf eine erratene Teilmenge.
Definition von Richtlinien
Sobald sensible Daten identifiziert sind, werden Anonymisierungsrichtlinien zentral definiert. Richtlinien legen fest, wie verschiedene Datenkategorien transformiert werden sollen, z.B. Ersatz durch synthetische Werte, Tokenisierung oder irreversible Anonymisierung.
Richtlinien sind wiederverwendbar und versioniert. Dieselbe Anonymisierungslogik kann konsistent in mehreren Datenbanken und Umgebungen angewandt werden, wodurch Divergenzen durch kopierte SQL-Skripte entfallen. Änderungen an Richtlinien werden automatisch propagiert, ohne Datenbankschemata oder Anwendungscode zu ändern.
Auswahl des Ausführungsmodus
Anonymisierung wird dann kontextabhängig ausgeführt, nicht als hartcodierte SQL-Abfragen. So können Organisationen steuern, wo und wann Anonymisierung erfolgt, ohne Logik zu duplizieren.
Typische Ausführungsziele sind Test- und Entwicklungsumgebungen, Datenauszüge, die mit Dritten geteilt werden, Datenbank-Replikate für Analysen und archivierte Datensätze zur Langzeitspeicherung. Jeder Kontext kann dieselben Richtlinien wiederverwenden, bleibt dabei aber operativ isoliert.
Dieses Modell stellt sicher, dass Produktionssysteme unberührt bleiben, während nachgelagerte Datenkonsumenten sichere, anonymisierte Datensätze erhalten.
Verifikation und Berichterstattung
Nach der Ausführung bietet DataSunrise Verifikations- und Berichtsfunktionen, die native Ansätze vermissen lassen. Administratoren können bestätigen, welche Datensätze anonymisiert wurden, welche Richtlinien angewandt wurden und ob die Abdeckung vollständig war.
Diese Berichte dienen als Nachweis für interne Sicherheitsprüfungen und externe Compliance-Audits. Anstatt sich auf Vertrauen in Skripte zu verlassen, erhalten Organisationen dokumentierte Belege dafür, dass Anonymisierung konsistent und korrekt angewandt wurde.
Indem Anonymisierung in einen verwalteten Workflow statt in eine destruktive SQL-Aufgabe verwandelt wird, eliminiert zentrale Anonymisierung Spekulationen, reduziert operationelle Risiken und skaliert über Umgebungen ohne Steigerung der Komplexität.
Geschäftliche Auswirkungen korrekter Datenanonymisierung
| Geschäftsbereich | Auswirkung |
|---|---|
| Sicherheitsrisiko | Verminderung der Auswirkungen von Datenpannen durch Entfernen nutzbarer sensibler Daten in Nicht-Produktionssystemen und geteilten Datensätzen |
| Betriebseffizienz | Schnellere Bereitstellung von Test-, QA- und Analyseumgebungen ohne Wartezeit für manuelle Datenbereinigungen |
| Compliance | Reduzierung des Prüfungsumfangs bei Compliance-Audits durch Ausschluss anonymisierter Datensätze von regulatorischer Aufsicht |
| Technische Zuverlässigkeit | Eliminierung menschlicher Fehler durch manuelle SQL-Anonymisierungsskripte |
| Data Governance | Klare und durchsetzbare Trennung zwischen Produktions- und Nicht-Produktionsdaten |
Korrekte Anonymisierung verschiebt Sicherheit nach vorne. Sensible Daten werden entfernt, bevor sie in Umgebungen gelangen, in denen Zugriffskontrollen, Überwachung und operative Disziplin schwächer sind. Statt zu versuchen, Daten überall zu schützen, verhindern Organisationen die Exposition bereits an der Quelle.
Fazit
Der Percona Server für MySQL bietet genug Flexibilität, um grundlegende Datenanonymisierung mit nativen SQL-Techniken umzusetzen. Für kleine Datensätze und einmalige Operationen mag dieser Ansatz ausreichend sein, insbesondere wenn die Anonymisierung eng begrenzt und manuell kontrolliert wird. Dennoch muss Anonymisierung selbst in diesen Fällen als Teil umfassenderer Datensicherheits-Praktiken gesehen werden und nicht als isolierte Wartungsaufgabe.
Mit zunehmender Systemgröße und strenger werdenden Daten-Compliance-Vorschriften wird manuelle Anonymisierung schnell fragil, intransparent und schwer zu validieren. Skripte drifteten auseinander, sensible Spalten werden übersehen, und es gibt keine verlässliche Möglichkeit, zu belegen, dass Anonymisierung konsistent über Test-, Analyse- und Archivdatensätze angewandt wurde. Dies stellt insbesondere bei groß angelegten Testdatenmanagement-Workflows ein Problem dar, in denen Daten häufig kopiert und wiederverwendet werden.
Zentrale Plattformen wie DataSunrise verwandeln Anonymisierung in einen kontrollierten, prüfbaren und wiederholbaren Prozess. Durch die Kombination automatisierter Sensitiverkennung, richtliniengesteuerter Transformationen und compliance-gerechter Berichterstattung wird Anonymisierung Teil der Sicherheitsarchitektur und nicht nur ein zerstörerischer Nachgedanke. Dieses zentrale Modell fügt sich auch nahtlos in andere Schutzmechanismen wie dynamische Datenmaskierung ein, ohne Logik zu duplizieren oder den operativen Aufwand zu erhöhen.
Wird Anonymisierung richtig durchgeführt, geht es nicht nur um das Verbergen von Daten. Es geht darum, Risiken an der Quelle zu beseitigen, bevor sensible Informationen in Umgebungen gelangen, in denen sie nicht hingehören.
