
Datenmaskierung für Amazon Redshift: Schützen und Steuern Sensibler Informationen

Einleitung
Mit der zunehmenden Nutzung von Cloud-Datenlagerlösungen wie Amazon Redshift stehen Organisationen vor neuen Herausforderungen, ihre wertvollen Daten zu schützen. Interne Akteure sind verantwortlich für nahezu die Hälfte (49%) der Datenverletzungen in Europa, dem Nahen Osten und Afrika, was auf häufige Vorkommnisse von Insider-Bedrohungen wie Berechtigungsmissbrauch und unbeabsichtigte Mitarbeiterfehler hinweist. Diese alarmierende Statistik unterstreicht die Bedeutung der Umsetzung robuster Sicherheitsmaßnahmen, wie z. B. der Datenmaskierung, um sensible Informationen zu schützen und die Einhaltung gesetzlicher Vorgaben sicherzustellen.
Verständnis der Datenmaskierung für Amazon Redshift
Datenmaskierung ist eine leistungsstarke Technik, mit der sensible Daten in Redshift geschützt werden, indem sie durch fiktive, jedoch realistische Informationen ersetzt werden. Bei Anwendung auf Amazon Redshift unterstützt sie Organisationen dabei, die Datenprivatsphäre zu wahren und gleichzeitig autorisierten Benutzern den Zugriff auf sowie die Analyse der benötigten Informationen zu ermöglichen.
Warum ist die Datenmaskierung wichtig?
- Schützt sensible Daten vor unbefugtem Zugriff
- Sichert die Einhaltung gesetzlicher Vorschriften wie DSGVO und HIPAA
- Verringert das Risiko von Datenverletzungen und Insider-Bedrohungen
- Ermöglicht die sichere Nutzung von Produktionsdaten in nicht-produktiven Umgebungen
Integrierte Datenmaskierungsfunktionen von Amazon Redshift
Amazon Redshift bietet integrierte Datenmaskierungsfunktionen, die dazu beitragen, sensible Informationen zu schützen. Diese Funktionen ermöglichen es Ihnen, Daten direkt in Ihren Abfragen oder Ansichten zu maskieren.
Wichtige Datenmaskierungsfunktionen von Redshift
Wir verwenden die folgende Tabelle mit synthetischen Daten von mockaroo.com:
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email) values (1, 'Garvey', 'Dummer', '[email protected]'); insert into MOCK_DATA (id, first_name, last_name, email) values (2, 'Sena', 'Trevna', '[email protected]'); …
Bei der Nutzung nativer Maskierungsfunktionen können Sie Konstruktionen verwenden wie:
SELECT RIGHT(email, 4) AS masked_email FROM mock_data;
SELECT '[email protected]' AS masked_email FROM mock_data;
CREATE VIEW masked_users AS
SELECT
id,
LEFT(email, 1) || '****' || SUBSTRING(email FROM POSITION('@' IN email)) AS masked_email,
LEFT(first_name, 1) || REPEAT('*', LENGTH(first_name) - 1) AS masked_first_name
FROM mock_data;
SELECT * FROM masked_users;
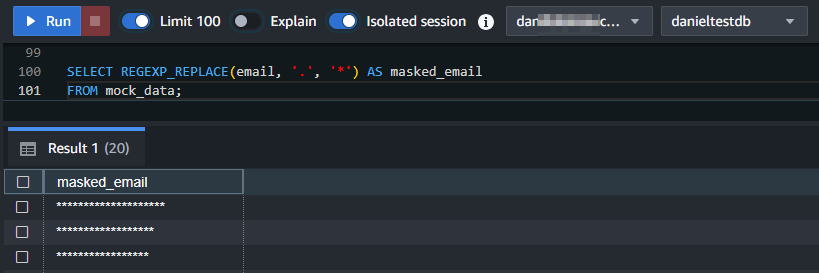
SELECT REGEXP_REPLACE(email, '.', '*') AS masked_email FROM mock_data;
Das Ergebnis für das REGEXP_REPLACE-Beispiel wird unten gezeigt:
Ein komplexerer Ansatz könnte die integrierten Python-Funktionen von Redshift beinhalten.
-- E-Mail maskieren --
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;
SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
Dynamische vs. Statische Datenmaskierung
Bei der Implementierung der Datenmaskierung für Amazon Redshift ist es wichtig, den Unterschied zwischen dynamischer und statischer Maskierung zu verstehen.
Dynamische Datenmaskierung
Die dynamische Maskierung wendet die Maskierungsregeln in Echtzeit bei der Abfrage der Daten an. Dieser Ansatz bietet Flexibilität und verändert die Originaldaten nicht.
Vorteile der dynamischen Maskierung:
- Keine Änderungen an den Quelldaten
- Maskierungsregeln können einfach aktualisiert werden
- Unterschiedliche Benutzer können verschiedene Ebenen maskierter Daten sehen
Statische Datenmaskierung
Die statische Maskierung verändert die Daten in der Datenbank dauerhaft. Diese Methode wird typischerweise verwendet, wenn Kopien von Produktionsdaten für Test- oder Entwicklungszwecke erstellt werden.
Vorteile der statischen Maskierung:
- Konsistente Maskierung in allen Umgebungen
- Geringere Auswirkung auf die Abfrageleistung
- Geeignet zur Erstellung bereinigter Datensätze
Erstellung einer DataSunrise-Instanz für dynamische Datenmaskierung
Um eine fortschrittliche dynamische Datenmaskierung für Amazon Redshift umzusetzen, können Sie Lösungen von Drittanbietern wie DataSunrise verwenden. So starten Sie mit DataSunrise:
- Melden Sie sich in Ihrem DataSunrise-Dashboard an
- Navigieren Sie zum Abschnitt “Instanzen”
- Klicken Sie auf “Instanz hinzufügen” und wählen Sie “Amazon Redshift”
- Geben Sie Ihre Redshift-Verbindungsdetails ein
Das untenstehende Bild zeigt die neu erstellte Instanz, die am Ende der Liste erscheint.
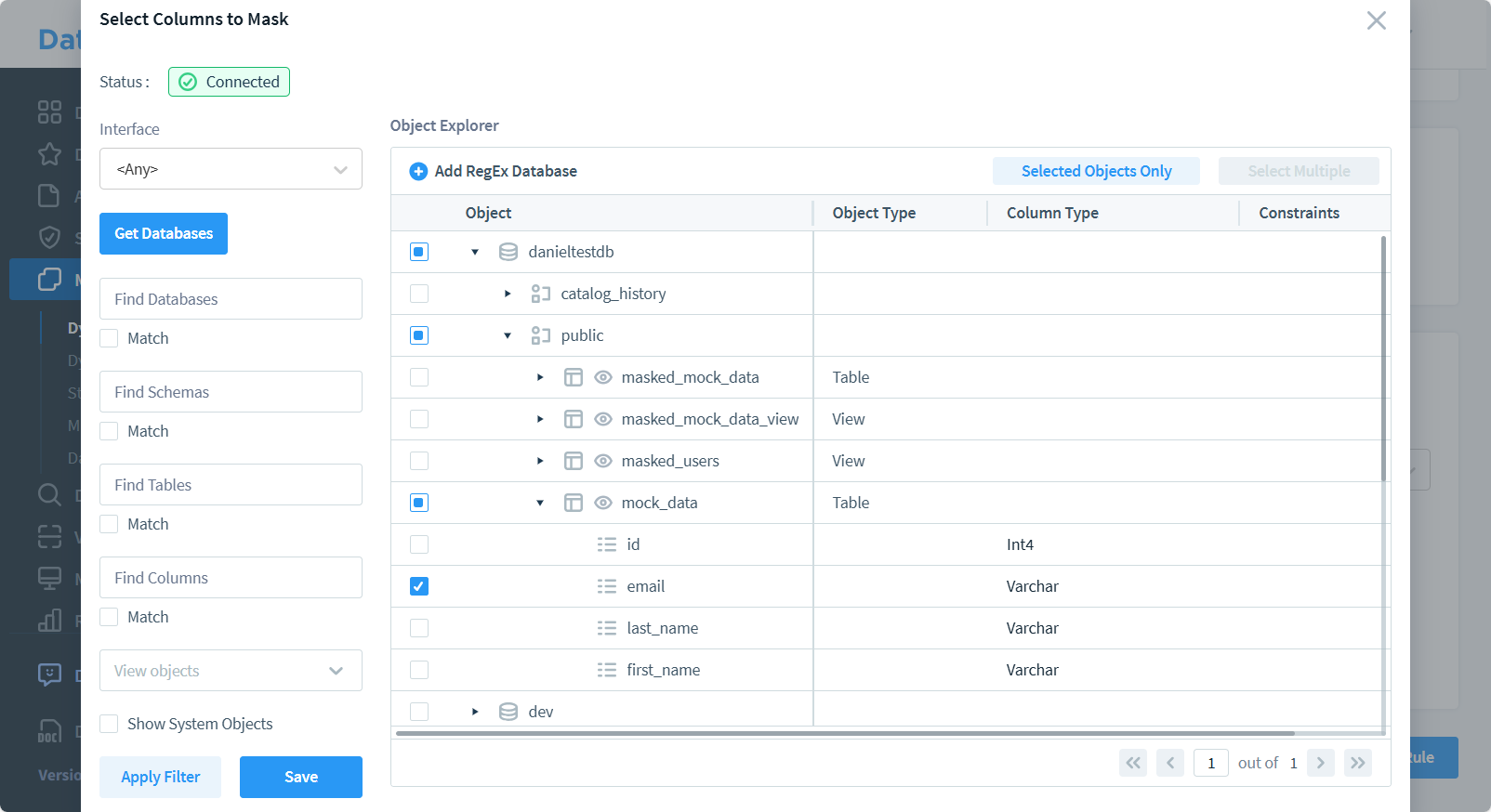
- Konfigurieren Sie die Maskierungsregeln für sensible Spalten
- Speichern und übernehmen Sie die Konfiguration
Sobald eingerichtet, können Sie dynamisch maskierte Daten anzeigen, indem Sie Ihre Redshift-Instanz über den DataSunrise-Proxy abfragen.
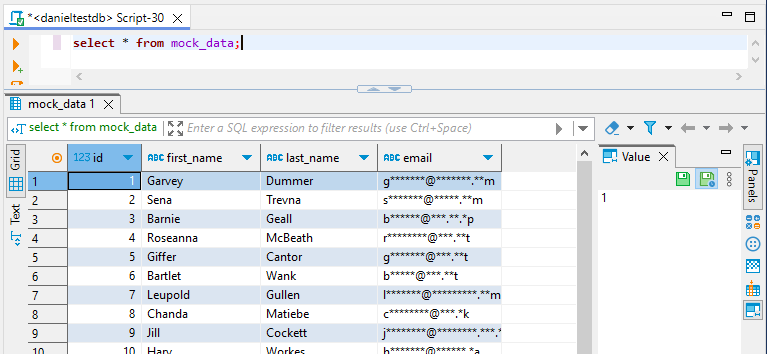
Beachten Sie, dass die E-Mail-Spalte maskiert ist. Dies demonstriert eine dynamische Maskierungsregel in Aktion. Die Daten werden in Echtzeit verschleiert, während die Abfrage ausgeführt wird, und schützen so sensible Informationen, ohne die zugrunde liegenden Daten zu verändern.
Best Practices für die Datenmaskierung in Amazon Redshift
Um einen effektiven Datenschutz zu gewährleisten, befolgen Sie diese Best Practices:
- Identifizieren und klassifizieren Sie sensible Daten
- Verwenden Sie eine Kombination von Maskierungstechniken
- Überprüfen und aktualisieren Sie regelmäßig die Maskierungsregeln
- Überwachen Sie den Zugriff auf maskierte Daten
- Schulen Sie Mitarbeiter in Datenschutzrichtlinien
Sicherstellung der Einhaltung gesetzlicher Vorschriften durch Datenmaskierung
Datenmaskierung spielt eine entscheidende Rolle bei der Erfüllung gesetzlicher Anforderungen. Durch die Implementierung robuster Maskierungsstrategien können Organisationen:
- Persönlich identifizierbare Informationen (PII) schützen
- Prinzipien der Datenminimierung einhalten
- Die Datenintegrität wahren und gleichzeitig die Privatsphäre schützen
- Sorgfalt im Datenschutz demonstrieren
Herausforderungen und Überlegungen
Obwohl die Datenmaskierung erhebliche Vorteile bietet, ist es wichtig, sich potenzieller Herausforderungen bewusst zu sein:
- Auswirkungen auf die Abfrageleistung
- Wahrung der Datenkonsistenz über Systeme hinweg
- Ausbalancieren von Sicherheit und Datenverwendbarkeit
- Umgang mit komplexen Datenbeziehungen
Zukunftstrends bei der Datenmaskierung für Cloud-Datenlager
Da die Cloud-Adoption weiter zunimmt, können wir Fortschritte in den Datenmaskierungstechnologien erwarten:
- KI-basierte Maskierungsalgorithmen
- Integration in Plattformen für Daten-Governance
- Verbesserte Kompatibilität zwischen Clouds
- Automatisierte Compliance-Berichterstattung
DataSunrise hat bereits alle hier aufgeführten Feature-Trends implementiert, was unser Produkt zur führenden Lösung für Multi-Storage-Umgebungen macht.
Fazit
Die Datenmaskierung für Amazon Redshift ist ein kritischer Bestandteil einer umfassenden Datenschutzstrategie. Durch die Implementierung effektiver Maskierungstechniken können Organisationen sensible Informationen schützen, gesetzliche Anforderungen einhalten und die mit Datenverletzungen verbundenen Risiken minimieren. Da sich die Bedrohungslage weiterentwickelt, ist es entscheidend, über die neuesten Technologien und Best Practices in der Datenmaskierung informiert zu bleiben.
Für diejenigen, die fortschrittliche Datenschutzlösungen suchen, bietet DataSunrise benutzerfreundliche und moderne Werkzeuge für die Datenbanksicherheit, einschließlich Audit– und Data Discovery-Funktionen. Um die Leistungsfähigkeit der umfassenden Datenschutzsuite von DataSunrise zu erleben, besuchen Sie unsere Website für eine Online-Demo und machen Sie den ersten Schritt zur Sicherung Ihrer wertvollen Datenbestände.
