
Dynamic Data Masking für Amazon Redshift

Einführung
Organisationen stehen unter zunehmendem Druck, persönliche Daten zu schützen und gleichzeitig die Einhaltung von Vorschriften zu gewährleisten. Hier kommt Dynamic Data Masking für Amazon Redshift ins Spiel – eine leistungsstarke Lösung, die Unternehmen dabei unterstützt, ihre Daten zu sichern, ohne die Funktionalität zu beeinträchtigen.
Tauchen wir ein in die Welt des Dynamic Data Masking und erkunden, wie es Ihre Datensicherheitsstrategie revolutionieren kann.
Laut dem Dashboard der National Vulnerability Database (NVD) wurden bis August 2024 in diesem Jahr 24.457 neue Common Vulnerabilities and Exposures (CVE)-Datensätze gemeldet – und wir sind erst zur Hälfte des Jahres.
Diese erstaunliche Statistik verdeutlicht die dringende Notwendigkeit robuster Datenschutzmaßnahmen. Dynamic Data Masking bietet einen hochmodernen Ansatz zum Schutz sensibler Informationen in Amazon Redshift-Datenbanken.
Verstehen der AWS Redshift Fähigkeiten für Data Masking
Amazon Redshift bietet mehrere integrierte Funktionen, die für grundlegendes Data Masking verwendet werden können. Auch wenn diese Funktionen nicht so umfassend wie spezielle Maskierungslösungen sind, bieten sie einen Ausgangspunkt zum Schutz sensibler Daten.
Testdaten
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email) values (6, 'Bartlet', 'Wank', '[email protected]'); insert into MOCK_DATA (id, first_name, last_name, email) values (7, 'Leupold', 'Gullen', '[email protected]'); insert into MOCK_DATA (id, first_name, last_name, email) values (8, 'Chanda', 'Matiebe', '[email protected]'); …
Verwendung von REGEXP_REPLACE
Eine der einfachsten Methoden zur Datenmaskierung in Redshift ist die Verwendung der REGEXP_REPLACE-Funktion. Mit dieser Funktion können Sie Teile eines Strings basierend auf einem regulären Ausdrucksmuster ersetzen.
Hier ist ein Beispiel, wie Sie Beschränkungen und REGEXP_REPLACE verwenden können, um eine Telefonnummer zu maskieren:
SELECT RIGHT(email, 4) AS masked_email FROM mock_data;
SELECT REGEXP_REPLACE(email, '.', '*') AS masked_email FROM mock_data;
Diese Abfrage ersetzt die ersten sechs Ziffern einer Telefonnummer durch ‘X’-Zeichen, sodass nur die letzten vier Ziffern sichtbar bleiben.
Oder noch einfacher:
SELECT '[email protected]' AS masked_email FROM mock_data;
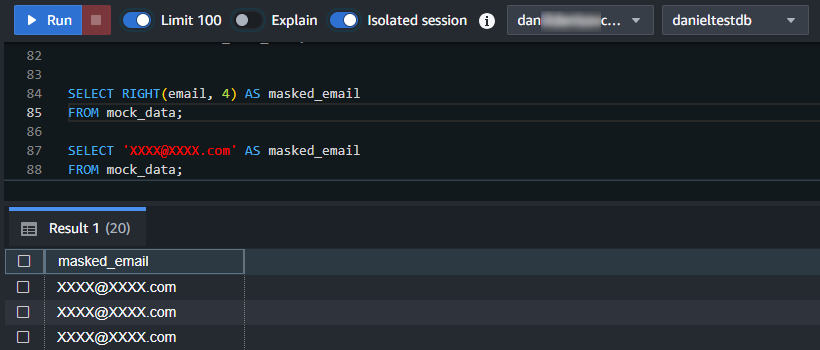
Ansichten maskieren
CREATE VIEW masked_users AS
SELECT
id,
LEFT(email, 1) || '****' || SUBSTRING(email FROM POSITION('@' IN email)) AS masked_email,
LEFT(first_name, 1) || REPEAT('*', LENGTH(first_name) - 1) AS masked_first_name
FROM mock_data;
SELECT * FROM masked_users;
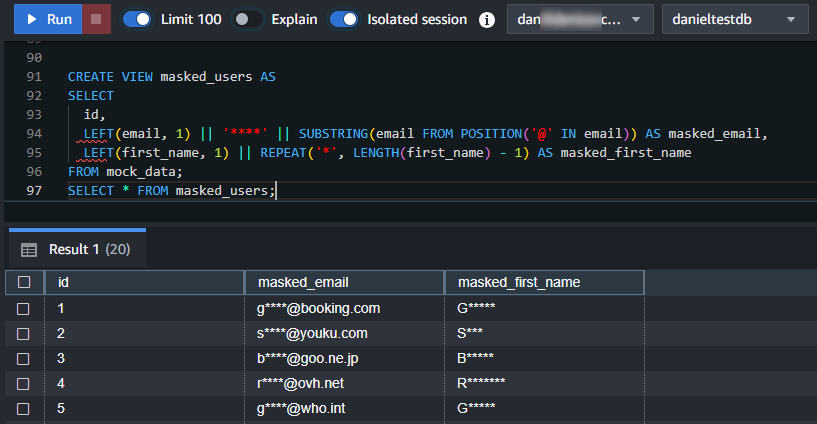
Verwendung integrierter Python-Funktionen
Redshift unterstützt auch benutzerdefinierte Funktionen (UDFs) geschrieben in Python. Diese können leistungsstarke Werkzeuge zur Implementierung komplexerer Maskierungslogiken sein.
Hier ist ein einfaches Beispiel für eine Python-UDF, die E-Mail-Adressen und Vornamen maskiert:
-- Email maskieren --
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;
-- Vorname maskieren --
CREATE OR REPLACE FUNCTION f_mask_name(name VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
if not name:
return name
# Behalte den ersten Buchstaben, maskiere den Rest
masked = name[0] + re.sub(r'[a-zA-Z]', '*', name[1:])
return masked
$$ LANGUAGE plpythonu;
SELECT id, f_mask_name(first_name) AS masked_first_name, last_name FROM MOCK_DATA;
Erstellen einer DataSunrise-Instanz für Dynamic Data Masking
Während die integrierten Fähigkeiten von Redshift grundlegende Maskierungsfunktionen bieten, fehlt ihnen die Flexibilität und Benutzerfreundlichkeit spezialisierter Lösungen wie DataSunrise. Lassen Sie uns erkunden, wie man Dynamic Data Masking mit DataSunrise einrichtet.
Konfiguration von Dynamic Data Masking
Um Dynamic Data Masking einzurichten:
- Navigieren Sie im Dashboard zum Abschnitt “Masking”.
- Wählen Sie im Menü “Dynamic Masking Rules” aus.
- Klicken Sie auf “Add New Rule”, um eine Maskierungsregel zu erstellen.
- Wählen Sie Ihre Amazon Redshift Datenbankinstanz aus der Liste der verbundenen Datenbanken aus.
- Wählen Sie die Tabelle und die Spalte, die Sie maskieren möchten.
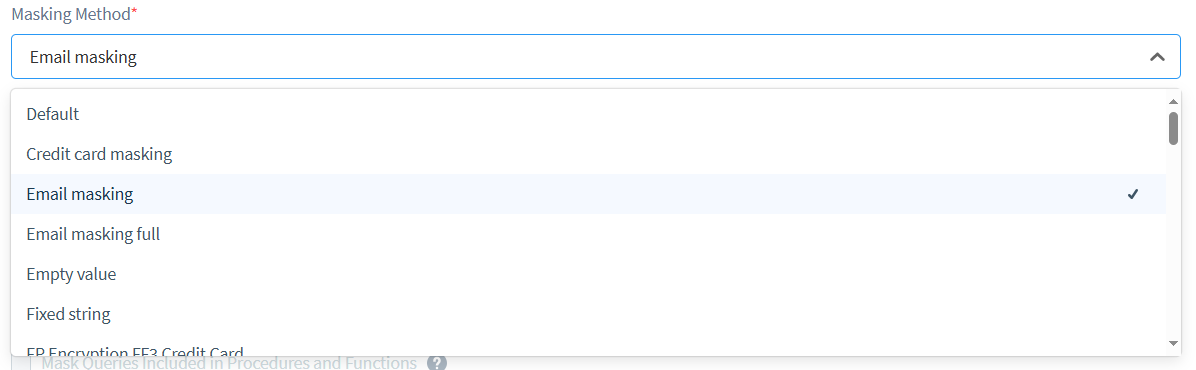
- Wählen Sie eine Maskierungsmethode (mehr dazu im nächsten Abschnitt).
- Speichern Sie Ihre Regel und übernehmen Sie die Änderungen.
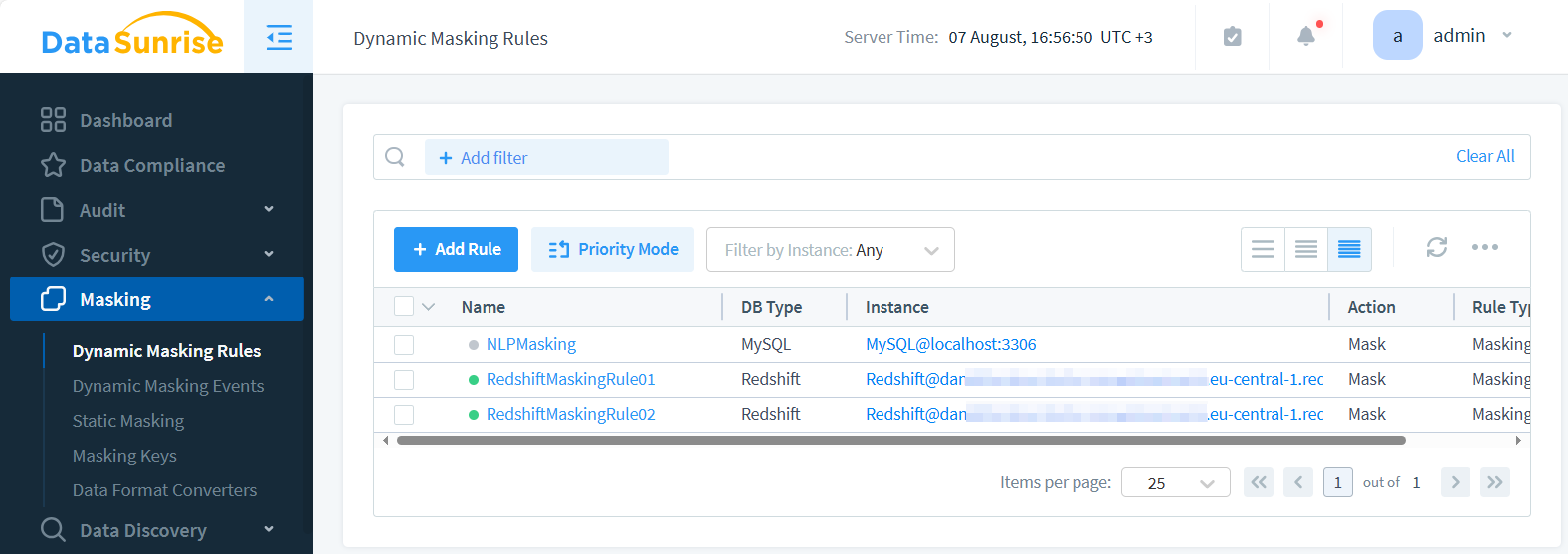
Das Bild zeigt zwei dynamische Datenmaskierungsregeln. Die erste Regel, mit dem Label ‘RedshiftMaskingRule01’, ist so konfiguriert, dass E-Mail-Adressen maskiert werden. Die zweite Regel, ‘RedshiftMaskingRule02’, ist so eingerichtet, dass Vornamen maskiert werden.
Nach der Konfiguration der Regeln können Sie eine Testabfrage ausführen, um die dynamisch maskierten Daten in Aktion zu sehen. Maskierte Datenzugriffe in DBeaver sind nachstehend dargestellt.
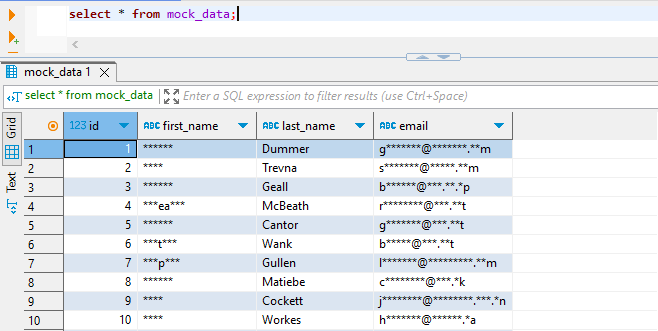
Das Erstellen dynamischer Maskierungsregeln mit DataSunrise ist bemerkenswert einfach und erfordert nur wenige Klicks. Dieser schlanke Prozess steht im deutlichen Gegensatz zu den komplexeren nativen Ansätzen. Am besten ist, dass diese Benutzerfreundlichkeit über Dutzende unterstützte Datenbanken und Speichersysteme hinweg gilt, was unvergleichliche Vielseitigkeit und Effizienz beim Datenschutz bietet.
Erkundung von Maskierungsmethoden
DataSunrise bietet mehrere Maskierungsmethoden, um unterschiedlichen Datentypen und Sicherheitsanforderungen gerecht zu werden. Schauen wir uns drei gängige Ansätze an:
Format erhaltende Verschlüsselung (FPE)
FPE ist eine fortschrittliche Maskierungstechnik, die Daten verschlüsselt und gleichzeitig ihr Originalformat beibehält. Dies ist besonders nützlich für Felder wie Kreditkartennummern oder Sozialversicherungsnummern, bei denen die maskierten Daten die gleiche Struktur wie die Originaldaten behalten müssen.
Beispiel: Original: 1234-5678-9012-3456 Maskiert: 8736-2940-5281-7493
Festgelegter Zeichenfolgewert
Diese Methode ersetzt das gesamte Feld durch eine vordefinierte Zeichenfolge. Sie ist einfach, aber effektiv für Fälle, in denen die tatsächliche Datenstruktur nicht wichtig ist.
Beispiel: Original: John Doe Maskiert: [REDACTED]
Nullwert
Manchmal ist es der beste Weg, sensible Daten zu schützen, sie vollständig zu verbergen. Die Nullwertmethode ersetzt die Originaldaten durch einen Nullwert und entfernt sie damit effektiv aus den Abfrageergebnissen für unbefugte Benutzer.
Beispiel: Original: [email protected] Maskiert: NULL
DataSunrise bietet eine vielfältige Auswahl an Maskierungsmethoden, die Ihnen zahlreiche Optionen zur Anpassung Ihrer Datenschutzstrategie bieten:
Vorteile von Dynamic Data Masking
Die Implementierung von Dynamic Data Masking für Amazon Redshift bietet mehrere entscheidende Vorteile:
- Verbesserte Datensicherheit: Schützen Sie sensible Informationen vor unbefugtem Zugriff.
- Einhaltung von Vorschriften: Erfüllen Sie Anforderungen an den Datenschutz wie GDPR und CCPA.
- Flexibilität: Wenden Sie verschiedene Maskierungsregeln basierend auf Benutzerrollen oder spezifischen Datenelementen an.
- Nahtlose Integration: Maskieren Sie Daten dynamisch, ohne die zugrunde liegende Datenbankstruktur zu ändern.
- Verbessertes Testen und Entwickeln: Bereitstellung realistischer, aber sicherer Daten für Nicht-Produktionsumgebungen.
Best Practices für die Implementierung von Dynamic Data Masking
Um die Effektivität Ihrer Datenmaskierungsstrategie zu maximieren:
- Identifizieren Sie sensible Daten: Führen Sie einen umfassenden Datenentdeckungsprozess durch, um alle sensiblen Informationen zu finden.
- Definieren Sie klare Richtlinien: Etablieren Sie konsistente Maskierungsregeln in Ihrer Organisation.
- Testen Sie gründlich: Überprüfen Sie, dass die Maskierung die Anwendungsfunktionalität nicht beeinträchtigt.
- Überwachen und prüfen Sie regelmäßig: Überprüfen Sie Maskierungsregeln und deren Wirksamkeit.
- Schulen Sie Ihr Team: Stellen Sie sicher, dass alle Beteiligten die Bedeutung der Datenmaskierung verstehen und wissen, wie man sie richtig verwendet.
Fazit
Dynamic Data Masking für Amazon Redshift ist ein leistungsstarkes Werkzeug im modernen Datensicherheitsarsenal. Durch die Implementierung robuster Maskierungsstrategien können Organisationen sensible Daten schützen, Compliance-Anforderungen erfüllen und die Risiken im Zusammenhang mit Datenverletzungen mindern.
Da der Datenschutz immer wichtiger wird, bieten Lösungen wie DataSunrise benutzerfreundliche und hochmoderne Werkzeuge für umfassende Datenbanksicherheit. Neben Dynamic Data Masking bietet DataSunrise Funktionen wie Datenprüfung und -entdeckung, die Ihre Fähigkeit zum Schutz wertvoller Informationen weiter verbessern.
Bereit, die Datensicherheit Ihres Amazon Redshift auf die nächste Stufe zu heben? Besuchen Sie die DataSunrise-Website für eine Online-Demo und entdecken Sie, wie unsere fortschrittlichen Werkzeuge Ihren Ansatz zum Datenschutz transformieren können.
Nächste
