
Datenmaskierungsansätze in KI & LLM-Workflows

Da künstliche Intelligenz (KI) und große Sprachmodelle (LLMs) die modernen Geschäftsabläufe transformieren, ist der Schutz sensibler Daten wichtiger denn je geworden. Datenmaskierung hilft, diese Herausforderung zu meistern, ohne die Innovation zu bremsen. In diesem Artikel untersuchen wir praktische Ansätze der Datenmaskierung in KI & LLM-Workflows, mit einem besonderen Schwerpunkt auf Echtzeitschutzmaßnahmen und der Integration von Compliance.
Warum Datenmaskierung in KI-Workflows entscheidend ist
Generative KI-Modelle verarbeiten häufig sensible Eingaben wie interne Protokolle, E-Mails, persönliche Daten und Finanzunterlagen. Diese Systeme können diese Daten unbeabsichtigt speichern oder reproduzieren. Durch Maskierung werden diese Risiken vermieden, indem sensible Informationen verborgen oder verändert werden, bevor sie das Modell erreichen.
Zum Beispiel, wenn ein feinabgestimmter LLM-Prompt den echten Namen und die Telefonnummer eines Kunden enthält, könnte das Modell diese Daten einprägen und wiederverwenden. Eine Maskierungsebene verhindert dies, indem sie Identifikatoren vor der Verarbeitung ersetzt. Die Datennutzungsrichtlinie von OpenAI erklärt, wie LLMs Benutzerinhalte unbeabsichtigt speichern könnten.
Statische und dynamische Maskierung im Kontext von LLMs
Statische Maskierung zur Vorverarbeitung
Statische Maskierung verändert ruhende sensible Daten und wird häufig während der Datenvorbereitung eingesetzt. Die statische Maskierung von DataSunrise transformiert Exporte dauerhaft, während die Struktur erhalten bleibt.
Google Cloud DLP unterstützt eine ähnliche statische Maskierung, einschließlich formatbewahrender Techniken für strukturierte Daten.
Dynamische Maskierung für den Echtzeiteinsatz
Dynamische Maskierung arbeitet mit Live-Daten. Wenn beispielsweise LLMs Benutzereingaben verarbeiten, können Maskierungs-Engines Kreditkartennummern oder nationale Identifikationsnummern unterdrücken, bevor das Modell sie sieht. Die dynamische Maskierung von DataSunrise ist für diesen Einsatz in der Produktion gut geeignet.
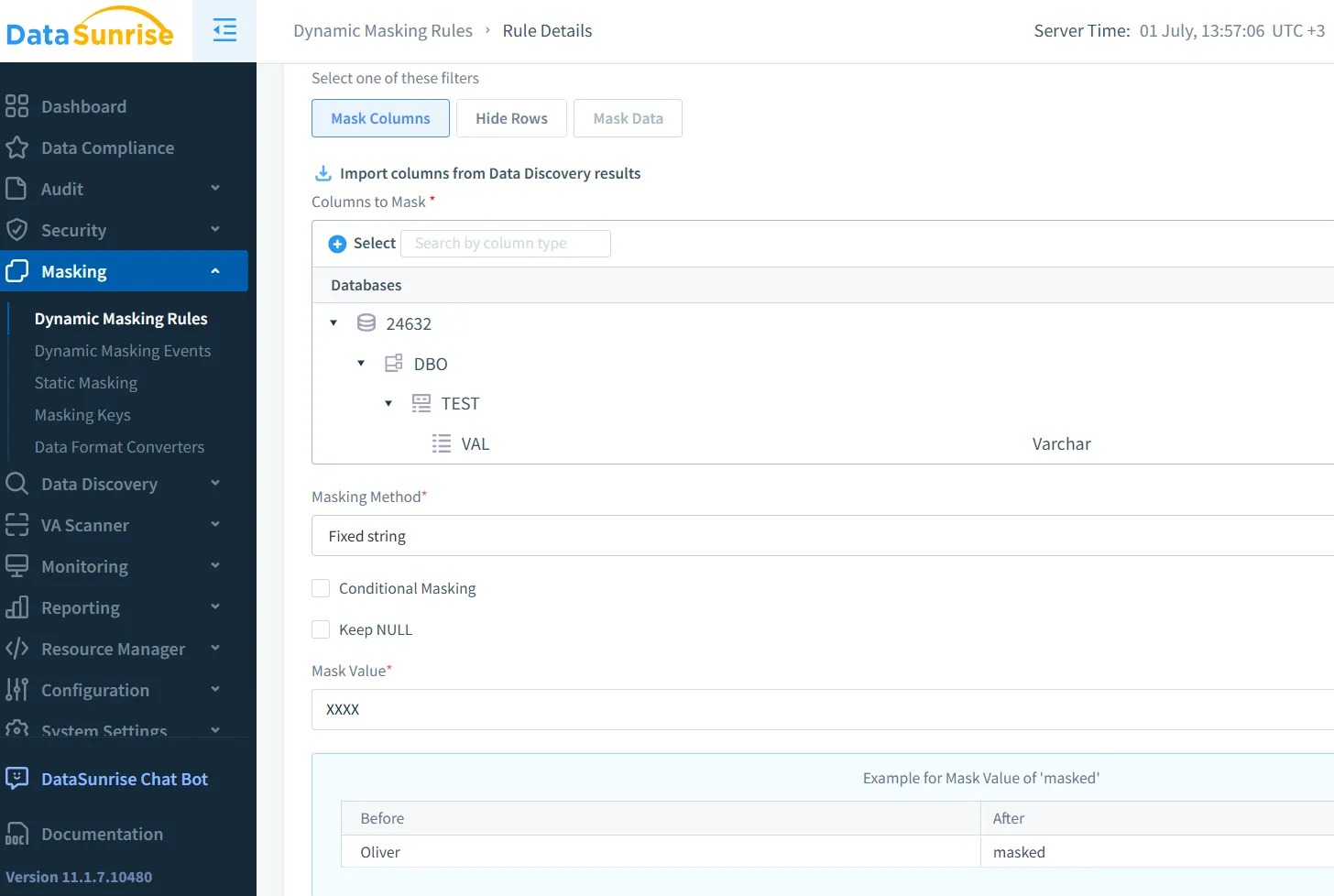
Amazon Macie bietet einen verwandten Service, der Daten in AWS-Umgebungen scannt und maskiert. Weitere Informationen finden Sie in diesem AWS-Beitrag.
Maskierung von LLM-Prompts in der Praxis
Betrachten Sie einen Kundensupport-Chatbot, der ein LLM verwendet. Nachrichten enthalten oft private Daten. Eine dynamische Regel könnte folgendermaßen aussehen:
CREATE MASKING RULE mask_pii
ON inbound_messages.content
WHEN content LIKE '%SSN%'
REPLACE WITH '***-**-****';
Diese Regel verhindert, dass Modelle auf rohe Sozialversicherungsnummern zugreifen.
Indem diese Logik auf der Middleware-Ebene angewendet wird, müssen Teams das Modell nicht ändern. Die Tools von DataSunrise für LLM- und ML-Sicherheit helfen dabei, diesen Prozess mithilfe kontextbewusster Erkennung zu automatisieren.
Die Architekturrichtlinien von Microsoft heben ebenfalls die Echtzeitmaskierung und den verantwortungsvollen Umgang mit Daten in LLM-Workflows hervor.
Von der Maskierung zu kontextbezogenen Zugriffskontrollen
Maskierung ist am effektivsten, wenn sie mit rollenbasierten Zugriffskontrollen, Prüfprotokollen und Verhaltensanalysen kombiniert wird. Ein Entwickler in der Testumgebung sieht möglicherweise realistische, aber gefälschte Daten, während Produktionsdaten redigiert bleiben.
Wenn sie mit Aktivitätsüberwachungstools verbunden sind, können Teams unmaskierten Zugriff erkennen oder Alarm auslösen. Maskierung wird dann zu einer Sicherheitsebene und nicht nur zu einer Maßnahme zum Schutz der Privatsphäre.
Dieses Design steht im Einklang mit den NIST Zero Trust-Prinzipien, die eingeschränkte Sichtbarkeit und strikte Richtliniendurchsetzung priorisieren.
Synthetische Daten als Alternative zur Maskierung
Statt reale Daten zu maskieren, generieren viele Teams inzwischen synthetische Daten, um KI-Modelle zu trainieren oder zu testen. Diese Datensätze bewahren Schemata und Logik, ohne reale Personen offenzulegen.
Die UK ICO erkennt synthetische Daten als eine datenschutzfreundliche Methode gemäß der DSGVO an, insbesondere für die Entwicklung von KI und ML.
Compliance-Anforderungen und Risikomanagement in der KI
Vorschriften wie DSGVO, HIPAA und PCI DSS verlangen von Organisationen, sensible Daten in der Verarbeitung zu rechtfertigen, zu anonymisieren oder zu maskieren. Maskierung unterstützt diese Anforderungen durch Datenminimierung und Risikokontrolle.
Zudem fügt es sich in datenbasierte Sicherheitsmodelle ein, in denen Governance und Schutz in jeder Schicht verankert sind.
Umsetzungsmuster in der realen Welt
In realen Systemen erfolgt die Maskierung typischerweise durch:
- Preprocessing-Skripte für Trainingsdaten
- Middleware-Engines für die Maskierung zur Laufzeit
- Reverse-Proxy-Maskierung für Ausgaben
- Überwachung von Inferenzprotokollen
Durch den Einsatz eines Reverse Proxy können Entwickler sensible Daten abfangen und redigieren, bevor sie das Modell oder die Protokolle erreichen.
Dieser mehrschichtige Ansatz verbessert nicht nur den Schutz – er schafft Vertrauen. Benutzer interagieren eher, wenn sie wissen, dass ihre Eingaben privat bleiben.
Fazit: Sicherere LLM-Pipelines aufbauen
Maskierung ist nicht nur ein Häkchen bei der Einhaltung von Vorschriften. Es ist eine Designentscheidung, die bestimmt, wie sicher Ihre KI arbeitet. Sowohl statische als auch dynamische Maskierung spielen eine entscheidende Rolle beim Schutz der Benutzerdaten über den gesamten Lebenszyklus hinweg.
In Kombination mit Erkennungstools, Audit-Richtlinien und Sicherheitsautomatisierung tragen diese Techniken dazu bei, KI-Systeme zu entwickeln, die von Grund auf sicher sind.
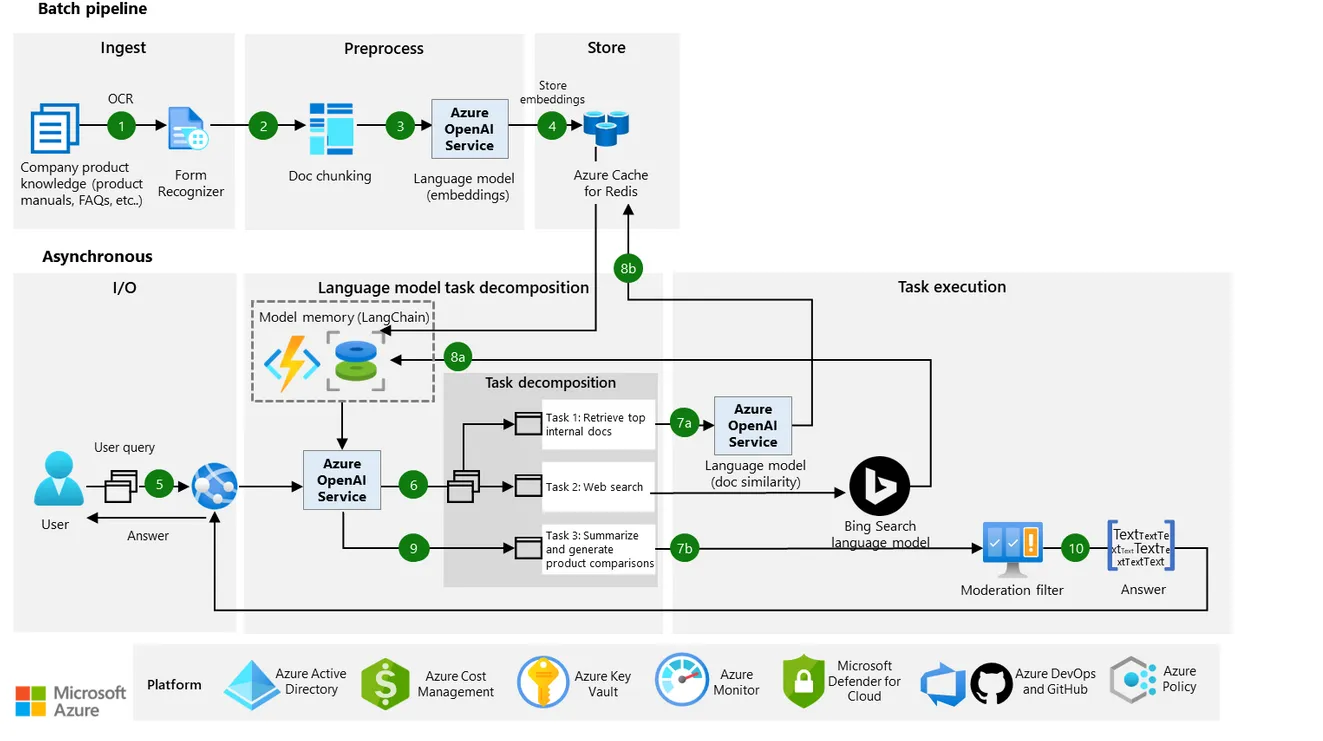
Für Teams, die GenAI skalieren, kann die richtige Maskierungsstrategie Sicherheitsverletzungen verhindern, die Haftung verringern und die Benutzer schützen, ohne die Innovation zu behindern.
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen