
Datenverlustprävention für GenAI & LLM-Pipelines

Generative KI (GenAI) und große Sprachmodelle (LLMs) haben die datengetriebene Innovation revolutioniert, jedoch führt ihre Abhängigkeit von enormen Datensätzen und promptgetriebenem Zugriff zu einer gefährlichen blinden Stelle: unkontrollierter Datenverlust. Vom Training mit sensiblen Aufzeichnungen bis hin zur Erzeugung von Ausgaben, die unbeabsichtigt proprietäre oder persönliche Informationen preisgeben, ist das Risiko nicht länger theoretisch. Die Verhinderung von Datenverlust in diesen Pipelines ist unerlässlich.
Dieser Artikel untersucht praktische Methoden der Datenverlustprävention für GenAI & LLM-Pipelines und konzentriert sich dabei auf Echtzeit-Prüfung, dynamische Maskierung, Datenerkennung und Sicherheitsdurchsetzung. Diese Techniken bieten umsetzbare Kontrollen, die Organisationen dabei unterstützen, compliant und sicher zu bleiben, ohne die Innovation zu beeinträchtigen.
Warum herkömmliche DLP-Tools unzureichend sind
Die meisten herkömmlichen Systeme zur Verhinderung von Datenverlust arbeiten auf Dateiebene. Sie überwachen ausgehende E-Mails, Datentransfers oder Clipboard-Aktivitäten und verlassen sich auf vordefinierte Mustererkennungen. Diese Methoden stoßen in GenAI-Kontexten an ihre Grenzen, in denen Daten durch Modelle und nicht durch Dateien fließen. LLM-Pipelines greifen auf Echtzeitquellen wie Datenbanken und APIs zu, mischen sensible und öffentliche Daten und speichern potenziell regulierte Inhalte während des Trainings.
Ein Beispiel: Eine Eingabeaufforderung wie “Fasse die interne Leistungsbewertung des letzten Quartals zusammen” kann einen Datenverlust auslösen, wenn das Modell auf gespeicherte Abfragen zugreift oder vorherige Anfragen protokolliert. Dies bedeutet, dass DLP-Kontrollen in die Schnittstelle zwischen Daten und Modell eingebettet werden müssen. Wie im NIST AI Risk Management Framework hervorgehoben, benötigen KI-Systeme maßgeschneiderte Sicherheitsvorkehrungen, die sich parallel zu den unterstützten Modellen weiterentwickeln.
Erkennen von Daten, bevor sie geschützt werden
Bevor präventive Maßnahmen implementiert werden, müssen Organisationen verstehen, welche Daten sie besitzen, wo diese gespeichert sind und wer darauf zugreift. Dies beginnt mit einer automatisierten Datenerkennung, die sowohl strukturierten als auch unstrukturierten Speicher nach sensiblen Elementen wie personenbezogenen Daten (PII), Gesundheitsinformationen (PHI) und geistigem Eigentum absucht.
Die DataSunrise-Erkennungstools scannen kontinuierlich nach sensiblen Feldern, ordnen sie den relevanten Compliance-Anforderungen zu und halten die Klassifizierung auf dem neuesten Stand. Diese proaktive Transparenz ist essenziell, bevor Prüf- oder Maskierungsrichtlinien durchgesetzt werden.
Aktuelle Forschungsergebnisse von Google DeepMind zeigen, dass selbst anonymisierte Trainingsdaten von LLMs re-identifiziert werden können, was die frühzeitige Datenerkennung zu einer unverhandelbaren Voraussetzung macht.
Echtzeit-Prüfung und Rückverfolgbarkeit
Sobald die Transparenz hergestellt ist, wird die Echtzeit-Prüfung zum Rückgrat einer sicheren GenAI-Einführung. Jede Anfrage an das LLM, jede Datenbankabfrage und jede Inferenzaktivität muss protokolliert werden. Die Rückverfolgung der Identität des Anfragenden, der abgerufenen Daten und des Ergebnisses ermöglicht proaktive Sicherheit.
Betrachten Sie dieses SQL-Protokoll als Beispiel:
SELECT customer_ssn, diagnosis FROM patient_records WHERE status = 'active';
Wenn es von einem GenAI-Systemkonto ohne PHI-Zugriff ausgegeben wird, kann eine Prüf-Engine wie DataSunrise die Abfrage blockieren oder markieren und in Echtzeit Sicherheitsanalysten alarmieren. Prüfprotokolle stellen sicher, dass selbst flüchtige Interaktionen erfasst werden.
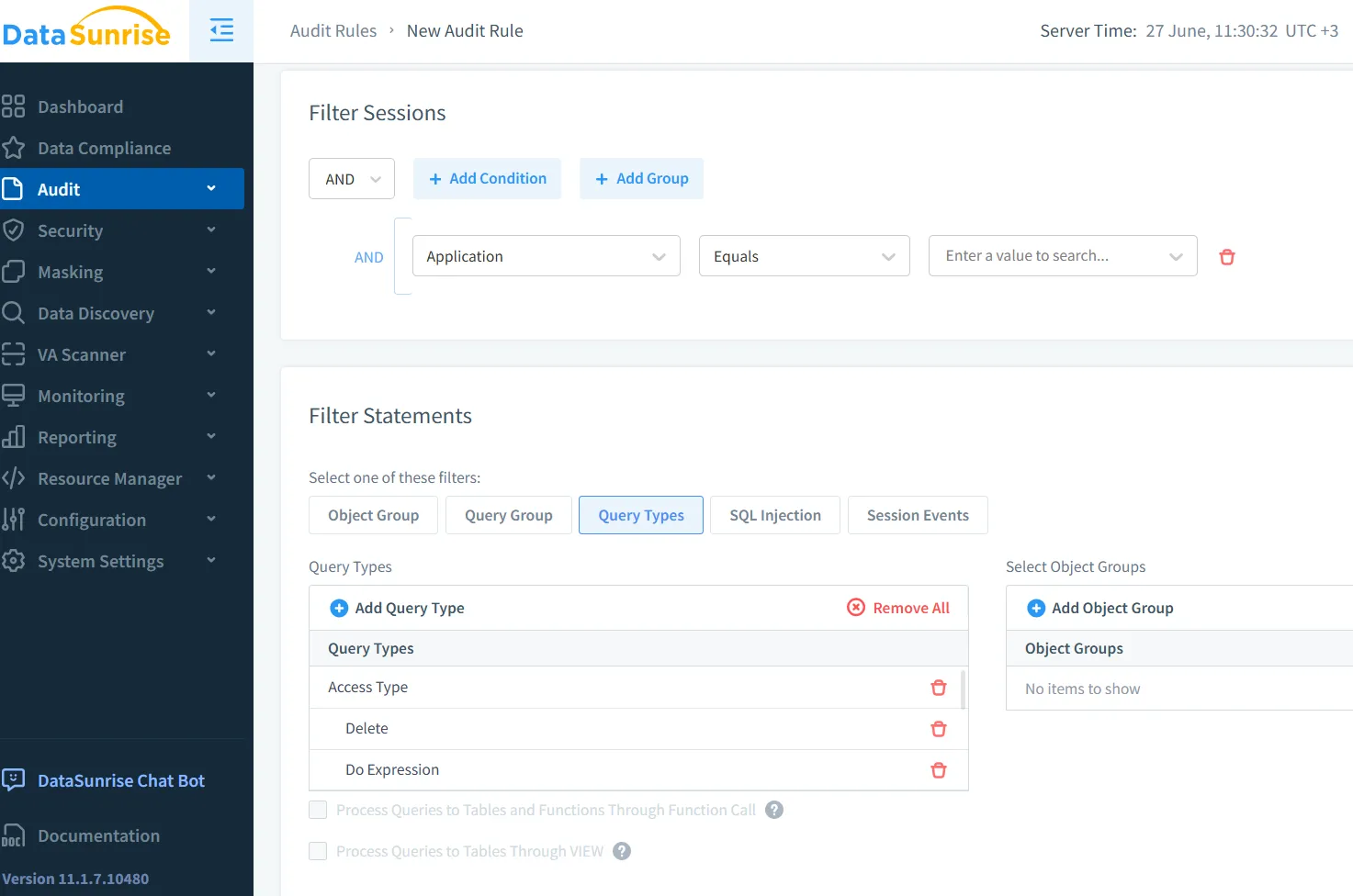
Zudem bieten Plattformen wie Microsoft Purview integrierte Prüfprotokolle mit rollenbasierter Analyse, die Einblicke in benutzerbezogene Dateninteraktionen innerhalb von KI-Pipelines ermöglichen.
Maskierung von Daten für KI-sichere Ausgaben
Statische Maskierung funktioniert in Testumgebungen, reicht aber für LLMs, die mit Echtzeitdaten arbeiten, nicht aus. GenAI-Pipelines erfordern eine dynamische Datenmaskierung, die Antworten basierend auf Benutzeridentität und Richtlinien abfängt.
Betrachten Sie folgenden Prompt:
“Liste VIP-Kunden in Kalifornien samt E-Mail-Adressen auf.”
Dynamische Maskierung sorgt dafür, dass Ausgaben wie:
Name: [REDACTED] | E-Mail: [MASKED]@domain.com
unberechtigten Benutzern angezeigt werden. Diese Technik, unterstützt durch die DataSunrise Dynamic Masking, ermöglicht eine sichere Interaktion, ohne die Integrität oder Verfügbarkeit der Datenbank zu gefährden.
Auch Open-Source-Modelle wie OpenMineds PySyft beginnen, privacy-preserving Inferenz-Pipelines zu unterstützen, was den wachsenden Fokus der Community auf dieses Thema unterstreicht.
Sicherheitsregeln auf Prompt-Schnittstellen anwenden
GenAI-Schnittstellen umfassen oft APIs, Slack-Bots, Dashboards oder interne Assistenten. Diese Schnittstellen sind anfällig für unüberwachte Eingaben. Das direkte Anwenden von Sicherheitsregeln auf der Abfrageebene kann Ausnutzung verhindern.
Nützliche Strategien umfassen das Blockieren von Prompts, die Schlüsselwörter wie SSN, Passwort oder Finanzen enthalten, sowie die Begrenzung der Zugriffshäufigkeit. Rollenbasierte Zugriffskontrolle stellt sicher, dass nur autorisierte Benutzer mit sensiblen Prompts interagieren können. Diese Kontrollen können durch Sicherheitsrichtlinien integriert in Prüf- und Maskierungsmechanismen durchgesetzt werden.
Darüber hinaus schlägt Anthropics Constitutional AI vor, Sicherheitsprinzipien direkt in das Denkprozess des Modells einzubetten, um so die perimeterbasierte Sicherheitsregeln zu ergänzen.
Compliance in GenAI-Pipelines
Compliance-Rahmenwerke wie GDPR, HIPAA und PCI-DSS verlangen einen strikten Umgang mit personenbezogenen und finanziellen Daten. LLMs ohne integrierte Durchsetzungsmechanismen können diese Standards leicht verletzen.
Um compliant zu bleiben:
- Führen Sie vollständige Prüfprotokolle für alle GenAI-Aktivitäten.
- Maskieren Sie personenbezogene Daten dynamisch in Trainings- und Inferenz-Ausgaben.
- Nutzen Sie einen Compliance-Manager, um die Richtliniendurchsetzung und Berichterstattung zu automatisieren.
Die Leitlinien des Europäischen Datenschutzbeauftragten zum Thema KI unterstreichen die Notwendigkeit von nachweisbaren Sicherheitsvorkehrungen und Transparenz in allen generativen Systemen.
Auf dem Weg zu transparenter und sicherer GenAI
Die Sicherung von GenAI-Pipelines erfordert mehr, als Schwachstellen nachträglich zu beheben. Es bedarf eines kontextsensitiven Ansatzes, bei dem Datenklassifikation, Prüfung, Maskierung und Richtliniendurchsetzung von Haus aus in die Pipeline integriert sind.
Mit Werkzeugen wie DataSunrise können Organisationen sichere, compliant und transparente LLM-Anwendungen entwickeln. Die Durchsetzung der Datenverlustprävention für GenAI & LLM-Pipelines ist nicht nur eine regulatorische Anforderung – sie stellt einen Wettbewerbsvorteil dar, der sowohl Innovation als auch Reputation schützt.
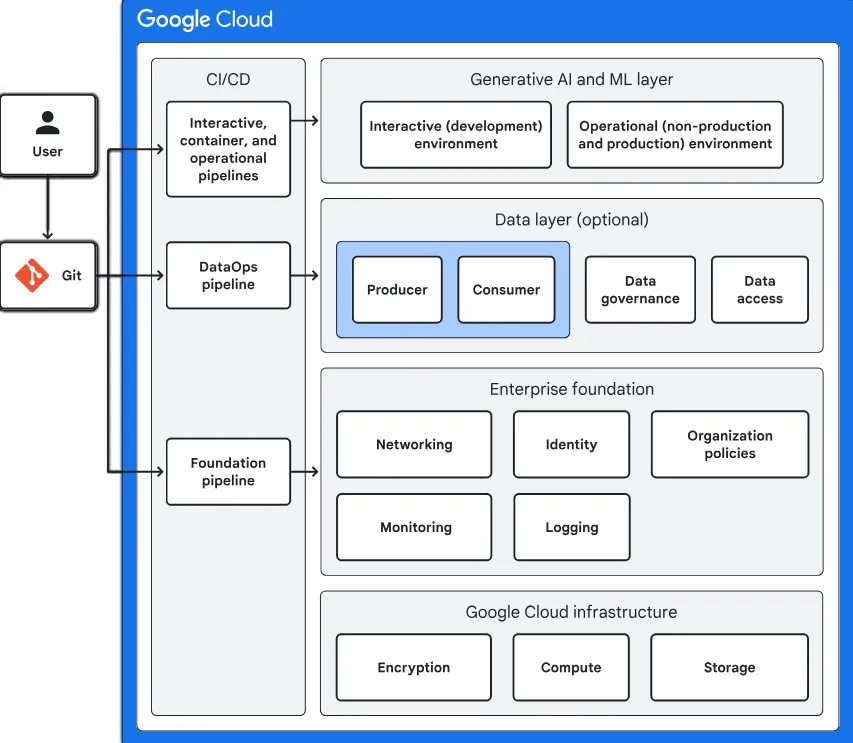
Da die KI-Governance zunehmend zum Zentrum von Risiko und Chance wird, ist die Einführung einer Echtzeit- und kontextsensitiven DLP in GenAI-Arbeitsabläufen nicht mehr optional – sie ist grundlegend.
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen