Sicheres Föderiertes Lernen
Da Organisationen darum wetteifern, gemeinsam intelligentere KI-Modelle zu trainieren, hat föderiertes Lernen (FL) sich zu einer der vielversprechendsten Techniken für die Zusammenarbeit entwickelt, ohne die Datensicherheit zu gefährden. Anstatt Daten in einen zentralen Server zu bündeln, trainiert jeder Teilnehmer ein lokales Modell und teilt ausschließlich dessen Aktualisierungen.
Obwohl diese Konfiguration die Angriffsfläche verringert, werden gleichzeitig neue Angriffspunkte eröffnet. Schwachstellen wie Gradienteninversionsangriffe und Datenvergiftung können dennoch private Informationen preisgeben oder Ergebnisse manipulieren. Um ein sicheres föderiertes Lernen zu gewährleisten, ist eine Kombination aus Kryptographie, Überwachung und strengen Daten-Compliance-Rahmenwerken erforderlich.
Verständnis von sicherem föderiertem Lernen
In föderierten Systemen trainieren die Teilnehmer — häufig Krankenhäuser, Banken oder Forschungseinrichtungen — gemeinsam ein geteiltes Modell. Jeder Knoten berechnet Aktualisierungen lokal und sendet lediglich Modellparameter oder Gradienten an einen Aggregator.
Dennoch können Angreifer sensible Daten aus den Gradienten rückentwickeln. Forscher von Google AI führten das Konzept erstmals ein, doch spätere Studien zeigten, dass selbst verschlüsselte Gradienten identifizierbare Informationen preisgeben können, wenn sie nicht ordnungsgemäß verwaltet werden.
Hier kommt das sichere föderierte Lernen ins Spiel — es führt ein:
-
End-to-End-Verschlüsselung
-
Aktivitätsüberwachung zur Prüfbarkeit
-
Anomalieerkennung mithilfe von Verhaltensanalytik
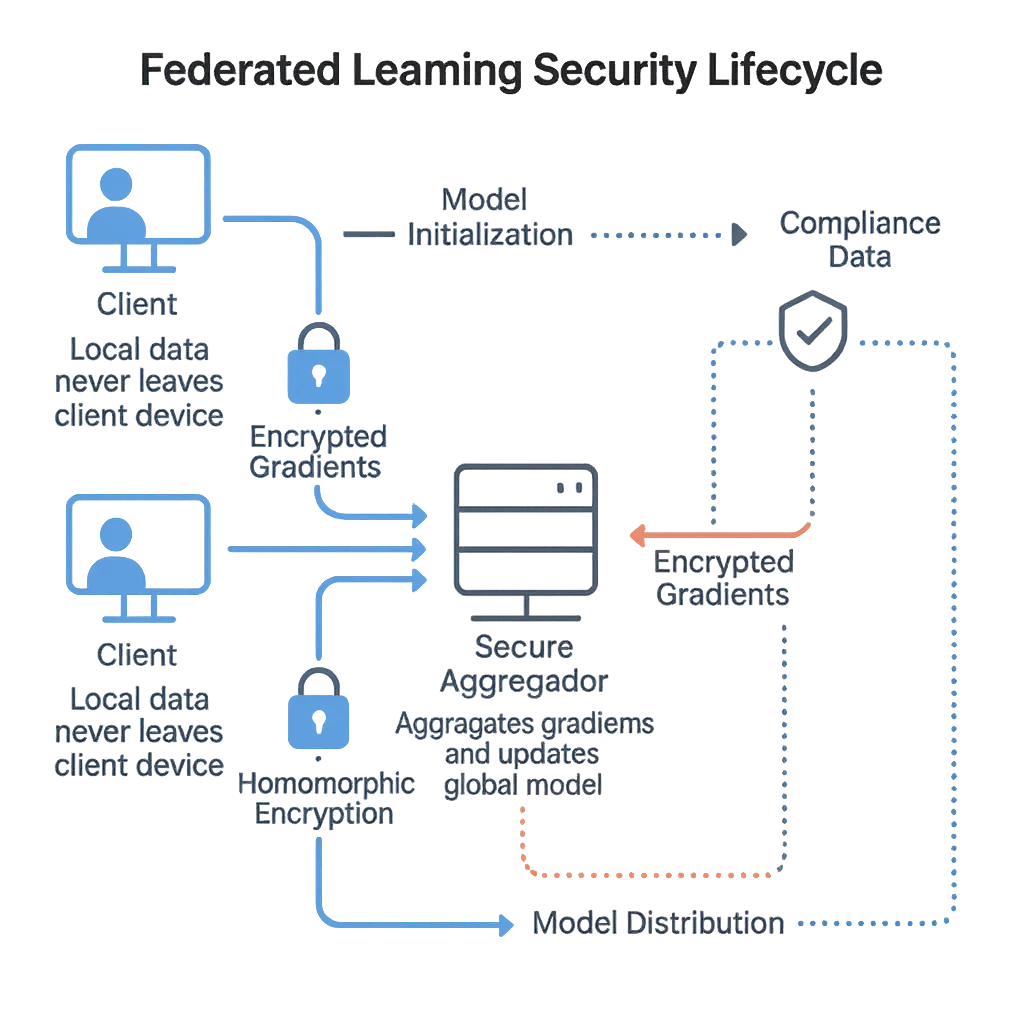
Diese Maßnahmen stellen sicher, dass Modellaktualisierungen über alle Teilnehmer hinweg verifizierbar, verschlüsselt und compliant bleiben.
Zentrale Sicherheitsherausforderungen
-
Gradienteninversionsangriffe – Angreifer rekonstruieren private Beispiele aus geteilten Gradienten, wodurch PII offengelegt wird.
-
Modellvergiftung – Böswillige Mitwirkende können voreingenommene Daten oder Hintertüren einspeisen und somit Firewall-Abwehrmechanismen umgehen.
-
Unzuverlässige Aggregatoren – Ohne strenge rollenbasierte Zugriffskontrolle werden zentrale Knoten zu Single Points of Failure.
-
Compliance-Abweichung – Datenflüsse über mehrere Rechtsgebiete hinweg erschweren es, die fortlaufende Übereinstimmung mit GDPR und HIPAA sicherzustellen.
Aktuelle akademische Übersichten, wie Zhu et al. (2023), betonen, dass föderierte Modelle nicht nur Verschlüsselung, sondern auch Verhaltensgovernance erfordern — beispielsweise die Validierung von Beiträgen, Zugriffskontrolle und Protokollierung über den gesamten Modelllebenszyklus.
Implementierung sicherer Aggregation
Der folgende Python-Codeausschnitt demonstriert einen vereinfachten Mechanismus zur sicheren Aggregation, der Vertrauen validiert und bösartige Aktualisierungen vor der Integration filtert:
from typing import Dict, List
import hashlib
class FederatedSecurityAggregator:
def __init__(self, threshold: float = 0.7):
self.threshold = threshold
self.trust_registry: Dict[str, float] = {}
def hash_gradient(self, gradient: List[float]) -> str:
"""Erzeuge einen Hash zur Integritätsüberprüfung."""
return hashlib.sha256(str(gradient).encode()).hexdigest()
def validate_node(self, node_id: str, gradient: List[float]) -> Dict:
"""Bewerte die Zuverlässigkeit des Knotens und erkenne Anomalien."""
gradient_hash = self.hash_gradient(gradient)
trust_score = self.trust_registry.get(node_id, 0.8)
malicious = trust_score < self.threshold
return {
"node": node_id,
"hash": gradient_hash,
"trust_score": trust_score,
"malicious": malicious,
"recommendation": "Ausschließen" if malicious else "Akzeptieren"
}
def aggregate(self, updates: Dict[str, List[float]]):
"""Aggregiere nur geprüfte Aktualisierungen."""
return {
node: self.validate_node(node, grad)
for node, grad in updates.items()
}
Diese Logik kann in Audit-Logs und in die Datenaktivitätschronik integriert werden, um Rückverfolgbarkeit und Compliance-Validierung zu gewährleisten.
Beste Umsetzungspraktiken
Für Organisationen
-
Privacy-by-Design – Wenden Sie dynamische und statische Datenmaskierung vor dem Training an.
-
Vereinheitlichte Audit-Strategie – Führen Sie kontinuierliche Audit-Trails über alle Knoten hinweg unter Einsatz von Data-Discovery-Tools.
-
Regulatorische Compliance – Überprüfen Sie die Einhaltung regionaler Rahmenwerke (GDPR, HIPAA, PCI DSS).
-
Verschlüsselte Zusammenarbeit – Verwenden Sie Datenbankverschlüsselung für Kanäle zwischen Organisationen.
Für technische Teams
-
Vertrauensbewertung – Pflegen Sie Zuverlässigkeitsmetriken der Knoten mittels Verhaltensanalytik.
-
Reverse-Proxy-Sicherheit – Leiten Sie den gesamten Verkehr über einen Reverse Proxy um, um kontrollierte Datenflüsse zu gewährleisten.
-
Zentralisierte Überwachung – Kombinieren Sie Datenbank-Aktivitätsüberwachung mit adaptiven Sicherheitsrichtlinien.
-
Kontinuierliche Validierung – Bewerten Sie Modellaktualisierungen regelmäßig neu und wenden Sie das Prinzip der minimalen Rechte an.
FAQ: Sicheres Föderiertes Lernen
F1. Was ist föderiertes Lernen in einem Satz?
Föderiertes Lernen ermöglicht es mehreren Parteien, ein gemeinsames Modell zu trainieren, indem Rohdaten lokal gehalten und nur Modellaktualisierungen geteilt werden.
F2. Macht FL die Datenteilung von Haus aus compliant?
Nein — FL verringert die Exposition, jedoch sind weiterhin Richtlinien, Protokollierung und Kontrollen erforderlich, um Rahmenwerke wie GDPR und HIPAA zu erfüllen; setzen Sie kontinuierliche Daten-Compliance-Prüfungen ein.
F3. Wie verhindere ich Gradienteninversionslecks?
Kombinieren Sie sichere Aggregation (z. B. Multi-Party-Computing oder homomorphe Verschlüsselung) mit Differential-Privacy-Rauschen bei Aktualisierungen, ergänzt durch strikte Zugriffskontrolle und Audit-Trails.
F4. TLS vs. Sichere Aggregation — was ist der Unterschied?
TLS schützt Aktualisierungen während der Übertragung; die sichere Aggregation stellt sicher, dass der Server einzelne Aktualisierungen nicht einsehen kann, selbst wenn der Transport sicher ist. Verwenden Sie beides.
F5. Wie werden vergiftete oder mit Hintertüren versehene Aktualisierungen erkannt?
Verwenden Sie Vertrauensbewertung und Anomalieerkennung (z. B. Kosinusähnlichkeits-Ausreißer, verlustbasierte Filter), isolieren Sie verdächtige Knoten und erzwingen Sie rollenbasierte Zugriffskontrolle.
F6. Was macht ein Aggregator eigentlich?
Er überprüft, aggregiert verschlüsselte Aktualisierungen, erzeugt ein globales Modell und verteilt dieses neu; er sollte keinen Zugriff auf Rohdaten oder unmaskierte Kundenaktualisierungen haben.
F7. Wo passt Compliance in den Kreislauf?
Als Überwachungsebene: Sie überwacht Protokolle, Konfigurationen und Nachweise (DP-Einstellungen, Schlüssellebenszyklen, Richtlinienübereinstimmungen), anstatt Gradienten zu empfangen. Siehe Datenbank-Aktivitätsüberwachung und Audit-Logs.
F8. Benötige ich in jeder Runde Differential Privacy?
Vorzugsweise ja, insbesondere bei sensiblen Daten; rundenweises Rauschen in Verbindung mit Privacy-Accounting begrenzt den kumulativen Informationsverlust, während die Nützlichkeit erhalten bleibt.
F9. Kann ich sensible Felder vor dem Training maskieren?
Ja — setzen Sie dynamische oder statische Datenmaskierung an der Peripherie ein, sodass sensible Felder niemals in die Merkmals-Pipeline gelangen.
F10. Wie protokolliere ich, ohne Daten zu leaken?
Protokollieren Sie Metadaten (Regelübereinstimmungen, DP-Budgets, Knoten-IDs, Hashes) und speichern Sie diese in manipulationssicherem Audit-Speicher; vermeiden Sie rohe Nutzlasten.
F11. Wie sieht der Modelllebenszyklus im sicheren FL aus?
Initialisierung → Verteilung an Clients → lokales Training → verschlüsselte Aktualisierung → sichere Aggregation → Validierung → globale Modellaktualisierung → erneute Verteilung; Wiederholung mit Versionsverwaltung und Rollback.
F12. Wie unterstützt DataSunrise?
Es bietet proxy-basierte Überwachung, Verschlüsselung, Verhaltensanalytik, Richtliniendurchsetzung und Compliance-Nachweise über die gesamte föderierte Pipeline.
Vertrauensbildung in kollaborativer KI
Föderiertes Lernen zeigt, dass Zusammenarbeit und Datenschutz koexistieren können — jedoch nur mit transparenter Auditierung, Verschlüsselung und Governance. Ohne diese besteht das Risiko, dass es zu einer blinden Stelle für Ausnutzung wird.
Durch die Kombination von sicherer Aggregation, Verhaltensanalytik und regulatorischer Ausrichtung bietet DataSunrise eine Grundlage für vertrauenswürdige kollaborative KI. Seine Module für Datenschutz und Audit stellen sicher, dass jeder Modellbeitrag verifizierbar, rückverfolgbar und compliant bleibt.
Empfohlene Lektüre:
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen