NLP-, LLM- und ML-Daten-Compliance-Tools für Amazon OpenSearch
NLP-, LLM- & ML-Daten-Compliance-Tools für Amazon OpenSearch sind wichtig, weil OpenSearch längst nicht mehr nur „Suche“ oder „Logs“ bedeutet. In modernen Stacks treibt es Observability, Sicherheitsanalysen und sogar KI-Assistenten an, die Vorfälle zusammenfassen oder Fragen zu indexierter Telemetrie beantworten. Sobald OpenSearch-Daten als Quelle für RAG, Prompt-Erweiterungen oder ML-Feature-Extraktion dienen, steigt das Compliance-Risiko: Unstrukturierte Payloads können Kennungen, Geheimnisse und regulierte Kontexte enthalten, die nun in Maschinengeschwindigkeit abfragbar sind.
AWS stellt die verwaltete Plattform für den Amazon OpenSearch Service bereit, doch die Verantwortung, sensible Daten zu identifizieren, die Exposition zu steuern und Auditnachweise zu erstellen, liegt weiterhin bei Ihrer Organisation. Dieser Leitfaden zeigt auf, wo NLP/LLM/ML unterstützen, wo sie schaden können und wie DataSunrise automatisierte Erkennung, Governance, Auditing, Maskierung und Berichterstellung für KI-getriebene OpenSearch-Umgebungen ermöglicht.
Warum KI-Arbeitslasten den Compliance-Druck in OpenSearch erhöhen
Klassische OpenSearch-Compliance-Herausforderungen bestehen bereits: semi-strukturierte Daten, sich schnell entwickelnde Indizes und breit gewährter Zugang aus Bequemlichkeit. KI-Arbeitslasten verstärken diese Probleme, da sie sowohl die Datenreichweite als auch die Dateninterpretation erhöhen. NLP-Pipelines extrahieren Entitäten aus Freitexten, LLMs fassen Inhalte zusammen (einschließlich sensibler Ausschnitte) und ML-Modelle erkennen Muster, die indirekt persönliche Informationen kodieren können. Dies ist keine Theorie – ein LLM, das auf „Was ist letzte Nacht passiert?“ antwortet, kann unbeabsichtigt Benutzerkennungen offenlegen, die in Logs eingebettet sind.
Deshalb muss KI-bewusste Compliance mit Daten-Compliance-Vorschriften und gängigen Rahmenwerken wie DSGVO, HIPAA-technische Schutzmaßnahmen und PCI DSS in Einklang stehen. In der Praxis ist es Regulatoren egal, ob Daten in einer Datenbank, einem Log-Index oder einem Suchcluster gespeichert sind – enthalten sie regulierte Inhalte, müssen sie geregelt werden.
Wie „KI-bereite Compliance“ für OpenSearch aussieht
Wenn OpenSearch NLP/LLM/ML-Systeme speist, muss Compliance kontinuierlich und messbar sein. Ein praktisches KI-bereites Programm konzentriert sich auf fünf Ergebnisse:
- Wissen, welche Daten existieren: kontinuierliche Identifizierung von personenbezogenen Daten (PII) und anderen sensiblen Mustern über Indizes und Dokumente hinweg.
- Begrenzen, worauf KI zugreifen kann: Zugriffsgrenzen und Geltungsbereich durchsetzen, um „Prompt = Admin“ zu verhindern.
- Reduzieren, was KI offenlegen kann: sensible Werte maskieren oder tokenisieren, bevor sie in Prompts oder Modell-Kontextfenster gelangen.
- Beweissicherung: nachvollziehbare Logs und Trails pflegen, die erklären, wer was warum zugegriffen hat.
- Automatisierte Berichterstattung: wiederholbare Nachweispakete für Audits und interne Kontrollen erzeugen.
Wie NLP, LLM und ML Compliance-Kontrollen unterstützen
NLP zur Erkennung unstrukturierter sensibler Daten
Nur mit Regex-Ansätzen scheitert man bei OpenSearch, weil die gefährlichsten Daten oft in Freitext-Logs und verschachtelten JSON-Feldern verborgen sind. NLP erhöht die Abdeckung durch die Erkennung von Entitäten und Kontext in unstrukturierten Inhalten. DataSunrise unterstützt skalierbare Klassifikation durch Data Discovery und hilft Teams, sensible Felder frühzeitig zu lokalisieren – bevor diese Daten in Embeddings, Prompts oder Trainingsdatensätze aufgenommen werden.
LLMs für Kontext und Erklärbarkeit
LLMs können Analysten-Workflows verbessern, bringen aber auch neue Compliance-Fragen mit sich: Welche Daten hat das Modell gesehen, was wurde zusammengefasst, und was wurde ausgegeben? LLM-fähige Governance benötigt Richtlinien-Durchsetzung und Auditierbarkeit der Zugriffswege – nicht blindes Vertrauen in die Anwendungsschicht. Hier wird die zentrale Richtlinien-Orchestrierung entscheidend.
ML für Verhaltensanalysen und Anomalieerkennung
ML eignet sich gut zur Erkennung von anormalem Abfrageverhalten: Sprünge hoher Kardinalität bei Suchanfragen, wiederholter Zugriff auf sensible Indizes oder ungewöhnliche Abrufmuster, die auf Scraping hinweisen. DataSunrise verstärkt dies mit Analyse des Benutzerverhaltens, die Teams ermöglicht, verdächtige Nutzung zu identifizieren, die traditionelle Zulassen/Ablehnen-Kontrollen übersehen könnten.
Referenzarchitektur: KI-bewusste Compliance-Schicht für OpenSearch
Das sicherste Muster ist, Compliance nahe an der OpenSearch-Zugriffsschicht durchzusetzen, sodass Erkennung, Richtlinien und Auditnachweise über Tools hinweg konsistent sind – Dashboards, APIs und KI-Agenten. DataSunrise bietet eine zentrale Compliance-Schicht für Governance und Beweissammlung, ohne dass Indizes neu gestaltet werden müssen.
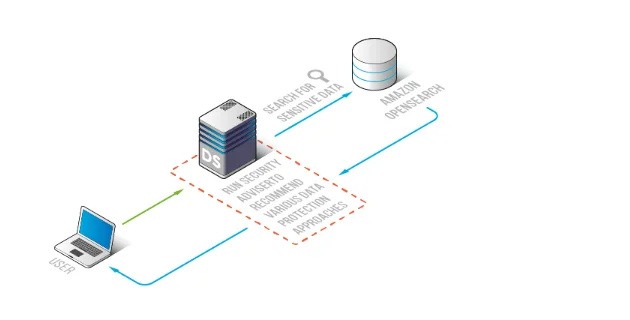
Kontrollabbildung: Wo Compliance-Tools in einer NLP/LLM/ML-Pipeline passen
| KI-Stufe | OpenSearch-Risiko | Compliance-Kontrolle | Ergebnis |
|---|---|---|---|
| Datenaufnahme | Sensible Felder werden in durchsuchbare Dokumente indexiert | Erkennung + Geltungsbereichsdefinition | Bekannter Bestand und geregelte Objekte |
| Abfrage (RAG) | Prompts ziehen rohe Kennungen in den Kontext | Maskierung + Prinzip der geringsten Privilegien | Geringere Exposition im LLM-Kontext |
| Analyse | Breiter Zugriff auf Dashboards und Ermittlungen | Zentrale Zugriffskontrollen + Audit-Logging | Nachvollziehbarkeit und Verantwortlichkeit |
| Modelltraining | Trainingsdatensätze enthalten regulierte Daten | Statische Maskierung oder synthetische Daten | Sichere Datensätze für ML/LLM-Tuning |
| Betrieb | Drift: neue Indizes/Pipelines erscheinen unbemerkt | Kontinuierliche Überwachung + Berichterstattung | Kontrollen bleiben über Zeit aktuell |
DataSunrise-Tools zur Automatisierung der OpenSearch-Compliance
1) Richtliniengesteuertes Compliance-Management
Um Governance zu skalieren, müssen Richtlinien zentral definiert und konsistent angewandt werden. DataSunrise bietet Richtlinien-Workflows über den Compliance Manager und ermöglicht Teams, Regeln über Umgebungen zu standardisieren. Kombinieren Sie Richtlinien mit RBAC und zentralisierten Zugriffskontrollen, sodass KI-Tools und Nutzer nur den Zugriff erhalten, der ihrer Rolle entspricht.
2) Geltungsbereichsauswahl für sensible OpenSearch-Objekte
Compliance-Tools müssen präzise sein: Regeln sollten nur für sensible Indizes gelten, ohne risikoarme Analysen zu beeinträchtigen. DataSunrise unterstützt objektbasierte Eingrenzung, sodass Richtlinien nur dort angewandt werden, wo es erforderlich ist – besonders wichtig, wenn derselbe OpenSearch-Cluster sowohl operative Dashboards als auch KI-Workflows bedient.
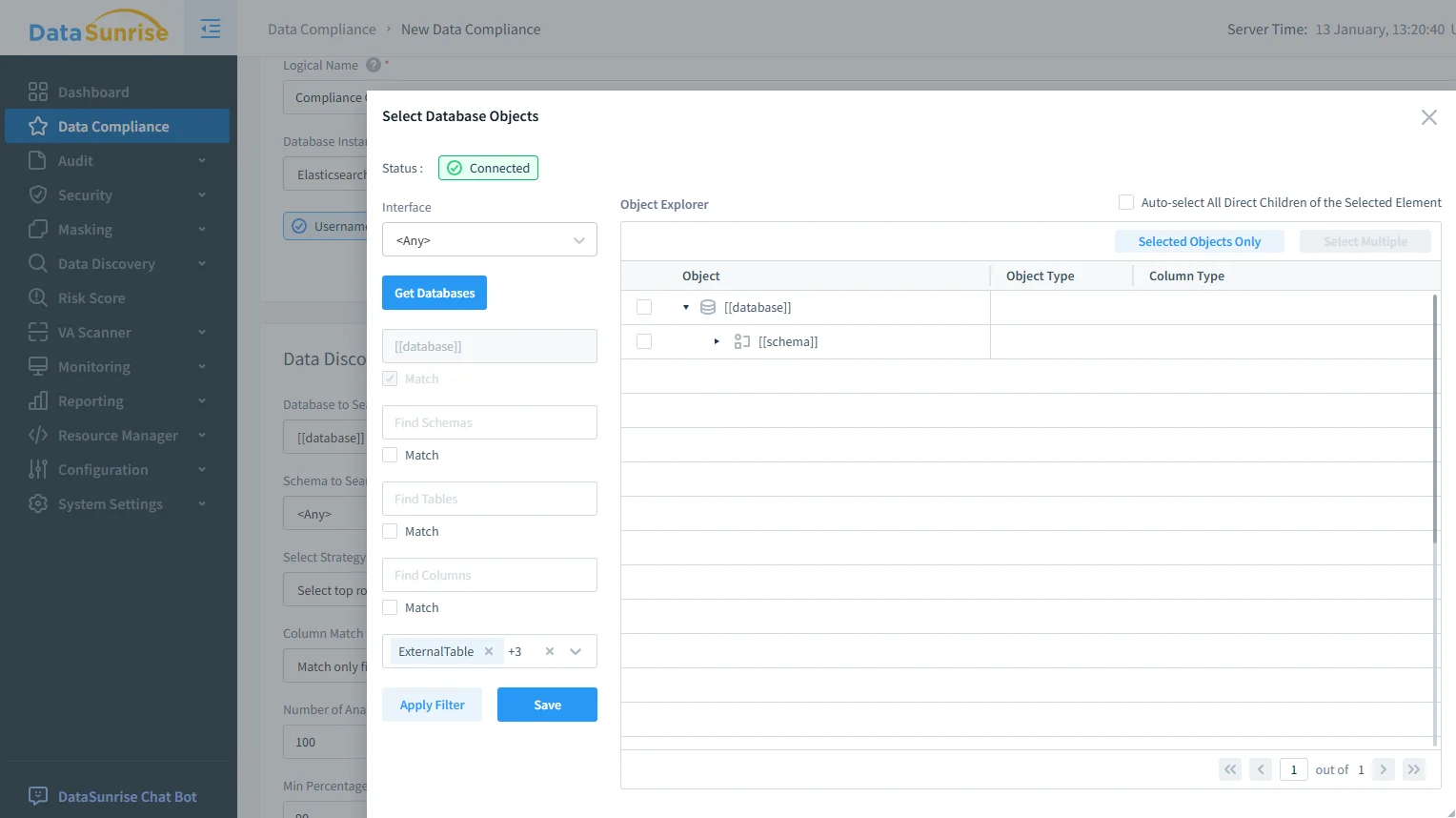
Geltungsbereichsauswahl für OpenSearch-Compliance: Wählen Sie geregelte Objekte, sodass KI-Workflows nur auf genehmigte Indizes und Felder zugreifen.
3) Auditing und Nachweise für KI-getriebenen Zugriff
KI erhöht die Anzahl der Zugriffswege (Dashboards, APIs, Agenten), daher müssen Auditnachweise zentralisiert werden. DataSunrise unterstützt detaillierte Audit-Logs über Data Audit und gewährleistet eine untersuchungsreiche Nachvollziehbarkeit mit Audit Trails. Für die Echtzeit-Überwachung hilft Database Activity Monitoring, riskantes Abfrageverhalten frühzeitig zu erkennen.
Für grundlegende Service-Logging-Anleitungen dokumentiert AWS OpenSearch-Audit-Logging hier: Amazon OpenSearch Audit-Logs. In KI-intensiven Umgebungen sind zentrale Nachweise meist einfacher zu verteidigen als verstreute Logs auf mehreren Ebenen.
4) Maskierung und Datensatzsicherheit für ML/LLM-Pipelines
Die meisten KI-Arbeitslasten benötigen keine rohen Kennungen. DataSunrise reduziert die Exposition durch dynamische Datenmaskierung zum Schutz zur Abfragezeit und statische Datenmaskierung für sicherere Exporte und Nicht-Produktiv-Pipelines. Wenn Trainings- oder Testdaten realistische Strukturen ohne echte Identitäten brauchen, hilft synthetische Datengenerierung, KI-Experimente compliant zu halten.
5) Präventive Sicherheitskontrollen und Validierung der Sicherheitslage
KI-Agenten können unbeabsichtigt Missbrauch verstärken (beispielsweise „Suche alles nach X“). Präventive Kontrollen helfen, die Schadensausbreitung einzuschränken. Verwenden Sie Datenbank-Firewall-Regeln, um missbräuchliche Muster zu blockieren, und Schwachstellenbewertungen, um Drift und Fehlkonfigurationen zu erkennen, die Compliance unterlaufen können.
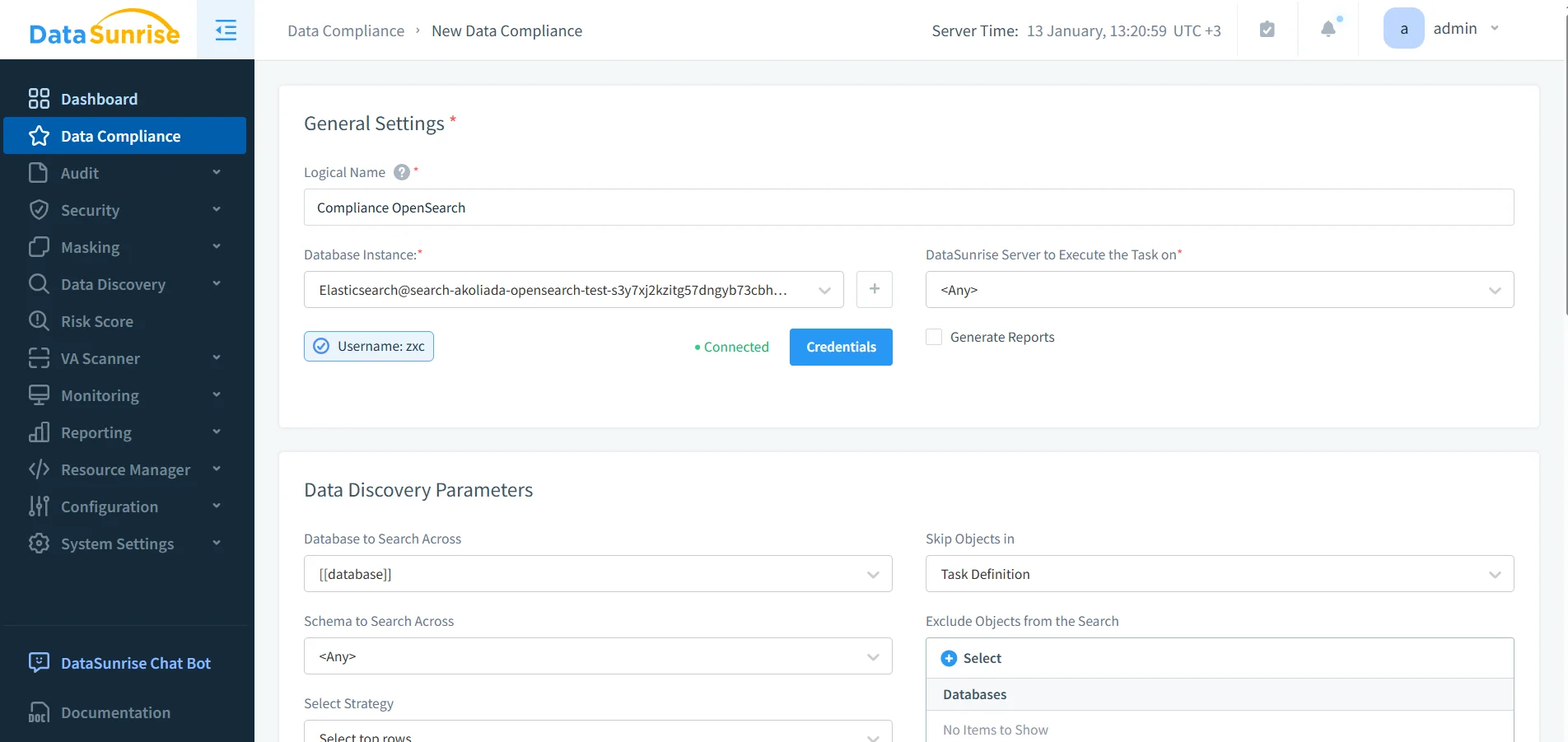
Konfiguration von Compliance-Regeln: Automatisieren Sie Governance-Aktionen (Audit, Maskierung, Berichterstattung) für KI-unterstützte OpenSearch-Workflows.
Automatisierte Berichterstattung für NLP-, LLM- und ML-Compliance
Prüfer wollen keine Screenshots, sondern reproduzierbare Nachweise. DataSunrise unterstützt automatisierte Berichterstellung mit Reportgenerierung und automatischer Compliance-Berichterstellung. In KI-intensiven Umgebungen unterscheidet Automatisierung zwischen „wir glauben, wir sind compliant“ und „hier ist das Nachweispaket“.
Um Compliance trotz Indexänderungen und Pipeline-Updates dauerhaft zu machen, stimmen Sie Kontrollen mit kontinuierlichem Datenschutz ab, sodass Erkennung, Richtlinien und Nachweise aktuell bleiben.
Fazit
NLP-, LLM- & ML-Daten-Compliance-Tools für Amazon OpenSearch funktionieren am besten, wenn sie keine „Aufsätze“ sind, sondern Teil einer Steuerungsebene: sensible Daten kontinuierlich erkennen, Zugriffe präzise einschränken, Exposition durch Maskierung reduzieren, Anomalien überwachen und auditfähige Nachweise automatisch erzeugen. DataSunrise bietet ein integriertes Regelwerk, um KI-gesteuerte OpenSearch-Arbeitslasten im großen Maßstab zu steuern.
Für die Planung der Bereitstellung sehen Sie sich die DataSunrise-Übersicht und verfügbaren Bereitstellungsmodi an und starten Sie dann mit Download oder fordern Sie eine geführte Demo an.
