So wenden Sie statisches Maskieren im Percona Server an
Statisches Maskieren im Percona Server für MySQL ist ein praxisorientierter Ansatz zum Schutz sensibler Informationen, bevor Daten Produktionsumgebungen verlassen. Der Percona Server wird häufig für transaktionale Workloads, Analyse-Pipelines und kundenorientierte Anwendungen verwendet, die oft regulierte Daten wie persönliche Identifikatoren, Kontaktdaten und finanzielle Attribute speichern. In diesem Zusammenhang fungiert das statische Maskieren als grundlegende Kontrollmaßnahme innerhalb umfassenderer Datensicherheitsstrategien.
Sobald Produktionsdatensätze in Entwicklungs-, Test-, Analyse- oder Supportumgebungen kopiert werden, verlieren herkömmliche Zugriffskontrollen ihre Wirksamkeit. An diesem Punkt wird eine dauerhafte Datenumwandlung zur zuverlässigsten Methode, um eine Offenlegung zu verhindern und gleichzeitig die Schema-Integrität und relationale Konsistenz zu erhalten. Dieser Ansatz unterstützt direkt moderne Datenbanksicherheitspraktiken, bei denen der Schutz auch außerhalb der Produktionsgrenzen bestehen bleiben muss. Der Percona Server für MySQL selbst wird in diesen Szenarien aufgrund seiner Leistung und Enterprise-Features häufig gewählt, wie in der offiziellen Percona Server Dokumentation beschrieben.
Dieser Artikel erläutert, wie statisches Maskieren im Percona Server für MySQL mit nativen SQL-Techniken angewendet werden kann und wie zentrale Plattformen wie DataSunrise diese Fähigkeiten mit richtliniengesteuerten, wiederholbaren Maskierungs-Workflows erweitern, die sich an modernen Daten-Compliance-Anforderungen orientieren.
Wann statisches Maskieren im Percona Server für MySQL erforderlich ist
Percona-Umgebungen erfüllen oft mehrere operative Zwecke gleichzeitig. Eine einzelne Datenbankinstanz kann Debugging von Anwendungen, Qualitätssicherung und Regressionstests, Business Analytics, Data-Science-Experimente und routinemäßige Support-Untersuchungen unterstützen. Obwohl diese Aktivitäten auf realistischen Schemata und Datenbeziehungen basieren, erfordern sie keinen Zugriff auf echte persönliche oder finanzielle Werte. In der Praxis wird statisches Maskieren zu einer zentralen Kontrollmaßnahme innerhalb umfassenderer Datensicherheitsstrategien, die darauf abzielen, unnötige Offenlegungen zu reduzieren.
Sobald Produktionsdaten außerhalb ihrer ursprünglichen Umgebung wiederverwendet werden, birgt die Beibehaltung der Originalwerte erhebliche Risiken. Selbst wenn rollenbasierte Berechtigungen durchgesetzt werden, greifen oft eine größere Benutzergruppe auf kopierte Datensätze zu, die in weniger kontrollierten Systemen gespeichert sind. In diesem Stadium reichen traditionelle Zugriffskontrollen allein nicht mehr aus, weshalb statisches Maskieren häufig als Teil umfassender Datenbanksicherheitspraktiken angewandt wird.
Statisches Maskieren wird zwingend erforderlich, wenn Produktionsdaten in Nicht-Produktionsumgebungen repliziert, mit Drittanbietern oder Auftragnehmern geteilt oder für Test- und Analyse-Workloads verwendet werden, ohne dass ein klarer geschäftlicher Zweck für echte Werte besteht. Zudem verlangen regulatorische Rahmenwerke wie DSGVO, HIPAA und PCI DSS ausdrücklich, die Verwendung echter sensibler Daten außerhalb von Produktionssystemen zu minimieren, wodurch das statische Maskieren mit etablierten Daten-Compliance-Prinzipien in Einklang steht.
Im Gegensatz zum dynamischen Maskieren ersetzt das statische Maskieren sensible Werte im Datensatz dauerhaft. Diese irreversible Transformation stellt sicher, dass selbst bei einem Versagen von Zugriffskontrollen oder einer erneuten Datenkopie die Originalinformationen nicht wiederhergestellt werden können. Somit ergänzt statisches Maskieren andere Schutzmechanismen, einschließlich dynamisches Datenmaskieren, indem es Offenlegungsrisiken direkt auf der Datenebene eliminiert.
Native Techniken des statischen Maskierens im Percona Server für MySQL
Der Percona Server für MySQL enthält keine integrierte Engine für statisches Maskieren. Daher wird statisches Maskieren üblicherweise durch explizite SQL-Transformationen umgesetzt, die auf kopierte Datensätze in Nicht-Produktionsumgebungen angewendet werden. Diese Operationen verändern die Daten dauerhaft und werden typischerweise unmittelbar nach der Replikation oder dem Export durchgeführt.
Spaltenbasiertes statisches Maskieren mit UPDATE-Anweisungen
Die gebräuchlichste Technik des statischen Maskierens besteht darin, sensible Spalten mit deterministischen oder teilweise verfremdeten Werten zu überschreiben. Dieser Ansatz bewahrt die Struktur des Schemas und die Datentypen, entfernt jedoch den echten Inhalt.
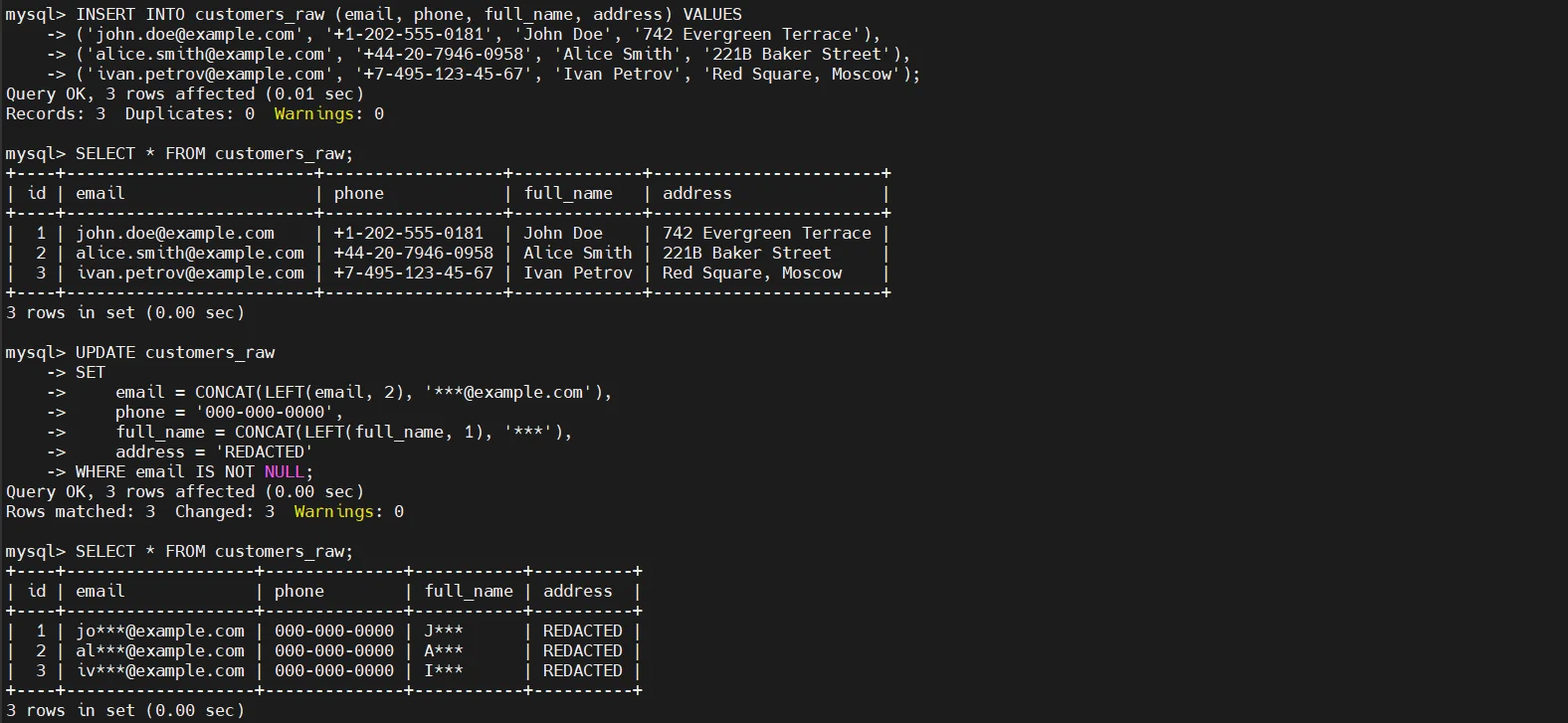
Diese Methode ist einfach und effektiv, verändert jedoch den Datensatz dauerhaft. Nach der Ausführung können Originalwerte nicht wiederhergestellt werden, weshalb sich dieser Ansatz nur für Nicht-Produktionskopien eignet.
Hash-basiertes Maskieren für Identifikatoren
Wenn Einzigartigkeit und referenzielle Integrität erhalten bleiben müssen, bietet Hashing eine verlässliche statische Maskiertechnik. Gehashte Werte bleiben tabellenübergreifend konsistent, sodass Joins und Vergleiche weiterhin funktionieren.
UPDATE users
SET
national_id = SHA2(national_id, 256),
passport_number = SHA2(passport_number, 256)
WHERE national_id IS NOT NULL;
Da Hashing eine Einwegfunktion ist, können ursprüngliche Identifikatoren nicht rekonstruiert werden, während die relationale Logik über abhängige Tabellen hinweg erhalten bleibt.
Zufallsgeneriertes Maskieren für numerische und Datumsfelder
Bei finanziellen Beträgen, Metriken oder Zeitstempeln hilft eine Randomisierung innerhalb kontrollierter Bereiche, realistische Datenverteilungen beizubehalten, ohne echte Werte preiszugeben.
UPDATE payments
SET
amount = FLOOR(RAND() * 1000) + 10,
tax_amount = FLOOR(RAND() * 200),
payment_date = DATE_SUB(
CURDATE(),
INTERVAL FLOOR(RAND() * 365) DAY
),
settlement_date = DATE_ADD(
payment_date,
INTERVAL FLOOR(RAND() * 5) DAY
);
Dieser Ansatz wird häufig in Test- und Analyseumgebungen verwendet, in denen Trends und Verteilungen wichtig sind, echte Transaktionsdaten jedoch nicht erforderlich sind.
Praktische Überlegungen
Obwohl das statische Maskieren auf nativen SQL-Techniken Flexibilität bietet, erfordert es sorgfältige Koordination. Abhängigkeiten zwischen Tabellen müssen manuell berücksichtigt werden, die Maskierungslogik muss konsistent über Umgebungen hinweg gepflegt werden, und Ausführungsfehler können leicht zu unvollständigen oder beschädigten Datensätzen führen. Mit wachsendem Maskierungsumfang werden diese Skripte immer schwieriger zu warten und zu steuern.
Zentrales statisches Maskieren für Percona Server für MySQL mit DataSunrise
DataSunrise bringt eine externe, richtliniengesteuerte Sicherheitsebene ein, die statisches Maskieren automatisiert, ohne Transformationslogik in SQL-Skripte oder Datenbankobjekte einzubetten. Statt manuell gepflegter UPDATE-Anweisungen oder gespeicherter Prozeduren werden Maskierungsregeln zentral definiert und konsistent über Umgebungen hinweg ausgeführt. Dies stellt sicher, dass die gleiche Transformationslogik jedes Mal angewandt wird, wenn Produktionsdaten für die Nicht-Produktionsnutzung vorbereitet werden.
Durch die Auslagerung der Maskierungslogik passt dieser Ansatz statisches Maskieren in umfassendere Datensicherheits- und Datenbanksicherheitsstrategien ein, bei denen der Schutz unabhängig vom Anwendungscode und der Datenbankschemadesign durchgesetzt wird.
Erkennung und Klassifizierung sensibler Daten
Bevor eine Maskierungsoperation beginnt, scannt DataSunrise automatisch Percona Server für MySQL-Schemata, um sensible Daten zu identifizieren. Der Erkennungsprozess erkennt persönlich identifizierbare Informationen, finanzielle Attribute, Zugangsdaten und andere regulierte Datenelemente anhand tatsächlicher Inhaltsmuster, nicht allein aufgrund von Spaltennamen oder Metadaten. Diese Fähigkeit baut auf modernen Datenentdeckungstechniken auf, die sich auf echte Dateninhalte und nicht nur auf Schemaannahmen stützen.
Da die Erkennung auf Inhaltsanalyse basiert, bleibt sie auch in schlecht dokumentierten oder inkonsistent benannten Schemata effektiv. Dadurch werden sensible Felder zuverlässig identifiziert, bevor Maskierungsregeln angewandt werden, was das Risiko eines versehentlichen Datenlecks verringert und die allgemeinen Datensicherheitskontrollen stärkt.
- Automatische Identifikation von PII, Finanzdaten und Zugangsdaten basierend auf Dateninhalt, abgestimmt auf PII-Schutz-Praktiken
- Unabhängigkeit von Spaltenbenennungskonventionen oder Schema-Dokumentationsqualität
- Kontinuierliche Entdeckung während der Schemaentwicklung
- Verringerung des Risikos des Übersehens sensibler Felder vor der Maskierung
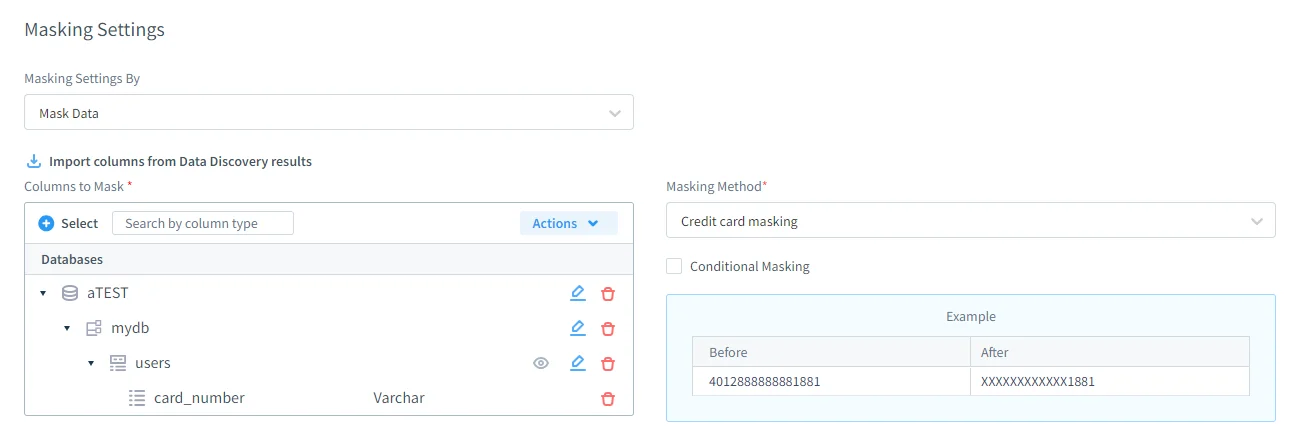
Definition statischer Maskierungsregeln
Statische Maskierungsregeln in DataSunrise bieten eine feingranulare Steuerung darüber, wie Daten transformiert werden. Administratoren können präzise festlegen, welche Datenbanken, Schemata, Tabellen und Spalten maskiert werden sollen sowie welche Maskierungsmethode auf jedes Feld angewendet wird. Unterstützte Techniken umfassen Substitution, Hashing, Randomisierung und Nullsetzung, gemäß etablierten Prinzipien des statischen Datenmaskierens.
Wichtig ist, dass Maskierungsregeln die referenzielle Integrität über verwandte Tabellen hinweg bewahren können, sodass Fremdschlüsselbeziehungen auch nach der Transformation gültig bleiben. Regeln sind wiederverwendbar und versioniert, was den Bedarf an einmaligen SQL-Skripten eliminiert und zur Konsistenz über mehrere Umgebungen hinweg beiträgt, während zentrale Datenbanksicherheitsrichtlinien unterstützt werden.
- Zentrale Regeldefinition über Datenbanken und Schemata hinweg
- Unterstützung mehrerer Maskierungstechniken pro Datentyp
- Erhaltung der referenziellen Integrität über verwandte Tabellen hinweg
- Versionierte Regeln, wiederverwendbar in verschiedenen Umgebungen
Ausführung statischer Maskierungsaufträge
Nach der Konfiguration der Maskierungsregeln wird die Ausführung zu einem gesteuerten operativen Prozess statt einer manuellen Aufgabe. Statische Maskierungsaufträge können bedarfsgesteuert ausgeführt, automatisch geplant oder in CI/CD- und Datenbereitstellungs-Pipelines integriert werden. Dieses Betriebsmodell entspricht umfassenderen Testdatenmanagement-Praktiken, die in modernen DevOps-Workflows genutzt werden.
Dadurch erhalten Nicht-Produktionsumgebungen konsistent maskierte Datensätze, ohne auf manuelle SQL-Ausführung oder Ad-hoc-Skripte angewiesen zu sein, was das operationelle Risiko und menschliche Fehler verringert und gleichzeitig die Datenverwaltung effizienter macht.
- Bedarfsgesteuerte Ausführung zur Ad-hoc-Vorbereitung von Datensätzen
- Geplante Maskierung für wiederkehrende Aktualisierungszyklen
- Integration mit CI/CD- und Datenbereitstellungs-Workflows
- Eliminierung manueller SQL-basierter Maskierungsschritte
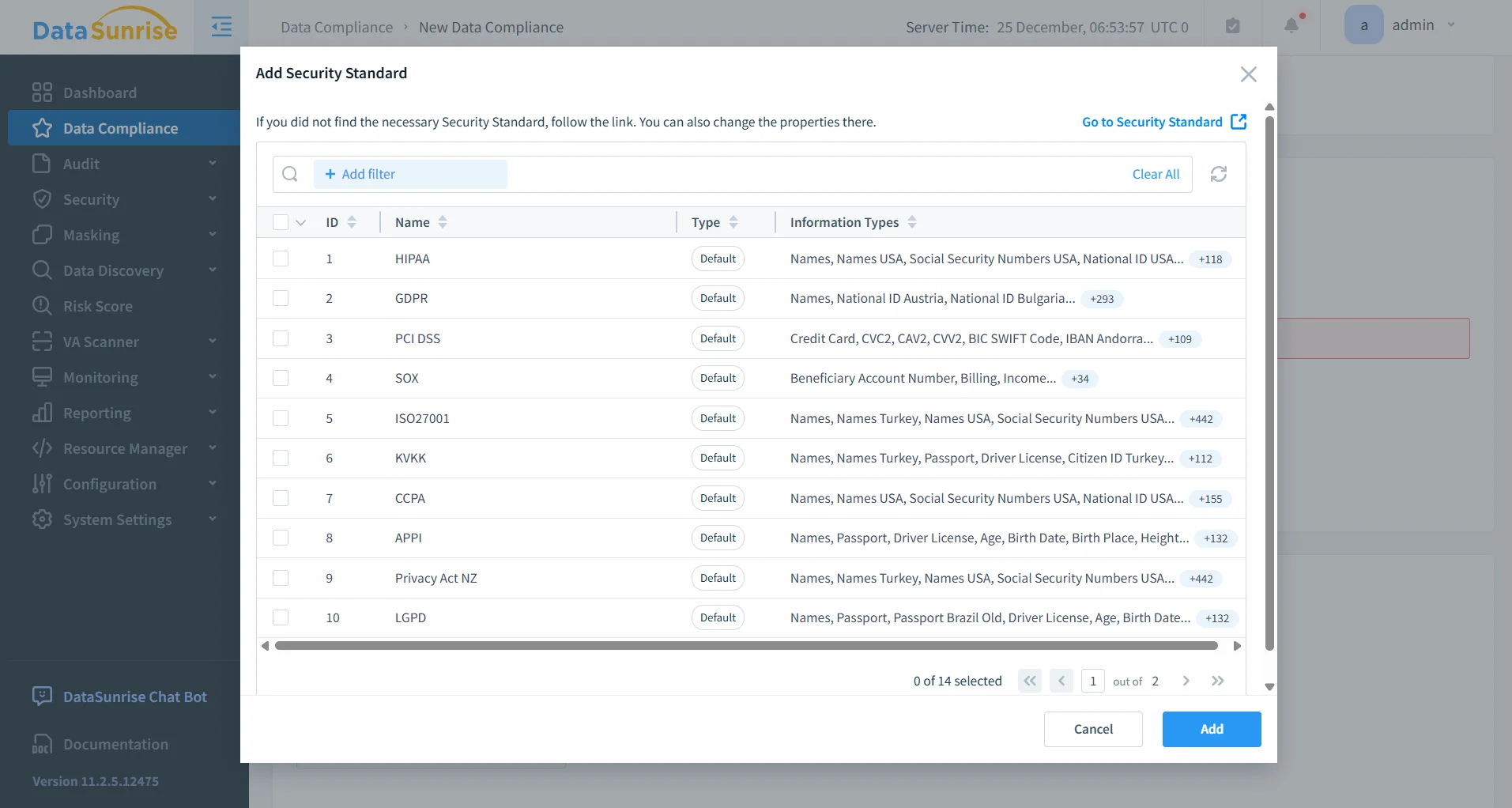
Auditfähigkeit und Compliance-Konformität
Jede statische Maskierungsoperation, die von DataSunrise durchgeführt wird, wird protokolliert und nachvollziehbar gemacht. Diese Aufzeichnungen schaffen eine klare Historie darüber, wann Maskierung ausgeführt wurde, welche Regeln verwendet wurden und welche Datenbestände betroffen waren. Dieses Maß an Transparenz unterstützt strukturierte Daten-Compliance-Programme direkt.
Indem statisches Maskieren zu einem dokumentierten, wiederholbaren Prozess wird, bewegen sich Organisationen weg von Ad-hoc-Datenhandhabung hin zu einem gesteuerten Compliance-Workflow, der internen Prüfungen und externen Audits standhält und zentrale Compliance-Management-Initiativen ergänzt.
- Volle Nachvollziehbarkeit von Maskierungsoperationen und Regelanwendungen
- Abstimmung auf Anforderungen von DSGVO, HIPAA, PCI DSS und SOX
- Nachweisfähige Aufzeichnungen für Audits und Compliance-Prüfungen
- Übergang von Ad-hoc-Maskierung zu gesteuerten Compliance-Prozessen
Geschäftliche Auswirkungen des statischen Maskierens im Percona Server für MySQL
| Geschäftsbereich | Operative Auswirkung |
|---|---|
| Datenexpositionsrisiko | Verminderte Wahrscheinlichkeit der Offenlegung sensibler Daten außerhalb von Produktionsumgebungen |
| Testdatenbereitstellung | Schnellere Erstellung konformer Datensätze für Entwicklung, Qualitätssicherung und Analysen |
| Audit-Vorbereitung | Weniger Aufwand zur Bereitstellung von Nachweisen für Sicherheits- und Compliance-Audits |
| Operative Konsistenz | Einheitlich angewandte Maskierungsregeln über Teams und Umgebungen hinweg |
| Datenfreigabesicherheit | Sicherere Zusammenarbeit mit internen Teams und externen Partnern |
Statisches Maskieren verlagert den Fokus von der Zugriffsbegrenzung hin zum ermöglichten sicheren und kontrollierten Datenwiederverwendung und macht Nicht-Produktions-Workflows sowohl sicherer als auch effizienter.
Fazit
Der Percona Server für MySQL bietet die Flexibilität, statisches Maskieren mittels nativer SQL-Techniken zu implementieren. Diese Ansätze eignen sich für kleine, kontrollierte Szenarien, in denen manuelle Durchsetzung akzeptabel ist und grundlegende Anforderungen an statisches Datenmaskieren mit individuellen Skripten erfüllt werden können.
Organisationen, die jedoch skalierbare Governance, Konsistenz über Umgebungen hinweg und auditfähige Maskierungs-Workflows benötigen, profitieren von zentralen Plattformen wie DataSunrise. Indem statisches Maskieren zu strukturierten Richtlinien anstelle fragiler Skripte formell gemacht wird, wird der Schutz sensibler Daten planbar, wiederholbar und konform von Grund auf, wodurch das gesamte Datensicherheitsprofil gestärkt wird.
Statisches Maskieren wird somit kein Workaround mehr – sondern eine operative Kontrollmaßnahme.
