
Synthetische Datengenerierung

Synthetische Datengenerierung wird schnell zu einem grundlegenden Element moderner KI-Entwicklung, fortgeschrittener Analytik und datenschutzorientierter digitaler Transformation. Sie ermöglicht es Organisationen, realistische, statistisch genaue Datensätze zu erstellen, die reale Informationen widerspiegeln – ohne echte Kunden- oder Unternehmensdaten preiszugeben. Dieser Ansatz unterstützt sicheres Experimentieren, maschinelles Lernen und Modellvalidierung und bleibt gleichzeitig konform mit etablierten Datenschutzverordnungen wie GDPR, HIPAA und CCPA. Laut einem aktuellen Gartner-Bericht haben fast die Hälfte der weltweit tätigen Führungskräfte ihre KI-Ausgaben erhöht, was den steigenden Bedarf an verantwortungsvoller und sicherer Datennutzung unterstreicht. Zusätzliche Leitlinien des NIST KI-Risikomanagementrahmens heben die Rolle synthetischer Daten bei der Reduzierung von Verzerrungen und der Unterstützung sicherer Modellentwicklungen hervor. Funktionen wie dynamisches Datenmaskieren verbessern weiter die Fähigkeit einer Organisation, sensible Informationen während des gesamten Prozesses zu schützen.
DataSunrise positioniert synthetische Daten als natürliche Weiterentwicklung des Datenschutzes – ergänzend zu bestehenden Methoden wie Datenmaskierung, Verschlüsselung und Überwachung von Datenbankaktivitäten. Diese Funktionalität ermöglicht es Organisationen, vollständig anonymisierte Datensätze in Produktionsqualität zu erzeugen, die die Struktur, Beziehungen und statistischen Muster echter Daten beibehalten. So können Teams Tests, Analysen und Entwicklungen in sicheren, kontrollierten Umgebungen durchführen, ohne Datenschutz- oder regulatorische Vorgaben zu verletzen. Synthetische Datensätze unterstützen eine sichere Zusammenarbeit, beschleunigen Innovationen und gewährleisten Compliance in jeder Phase des KI-Lebenszyklus.
In Kombination mit Automatisierung und intelligenten Richtlinienkontrollen verbessert synthetische Datengenerierung nicht nur den Datenschutz und die Regeltreue, sondern steigert auch Skalierbarkeit, operative Agilität und Kontinuität. Sie ermöglicht Unternehmen, KI und Analytik innerhalb sicherer, ethisch gesteuerter Ökosysteme einzuführen – Innovation freizusetzen und zugleich Vertrauen sowie regulatorische Übereinstimmung zu wahren.
Was sind synthetische Daten?
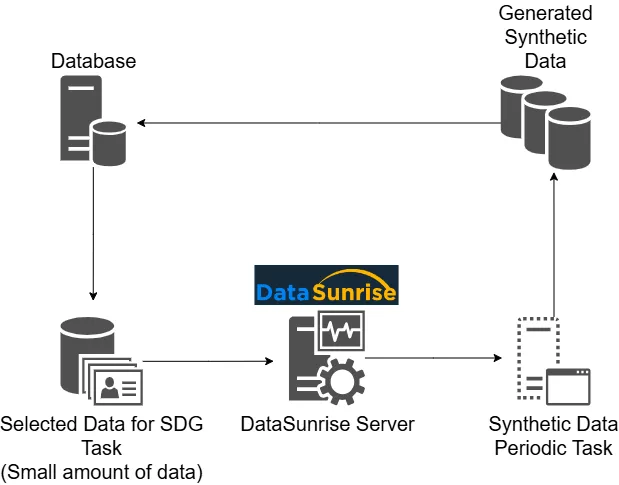
Synthetische Daten sind künstlich erzeugte Informationen, die die Struktur und das statistische Verhalten realer Datensätze widerspiegeln, ohne echte Werte zu enthalten. Sie bewahren Formate, Beziehungen und Verteilungen, wodurch Teams sicher entwickeln, testen und analysieren können. Da keine echten Datensätze verwendet werden, eliminieren synthetische Datensätze Datenschutzrisiken und sind gleichzeitig hochwirksam für KI-Modellierung, Systemvalidierung und Compliance-Maßnahmen.
Wann synthetische Daten statt Maskierung verwenden?
Statische oder dynamische Maskierung ist ideal, wenn die Struktur und Logik von Produktionsdaten beibehalten werden sollen – aber dennoch ein Bezug zu realen Werten erwünscht ist. Maskierung kann jedoch extern nicht geteilt werden, wenn das Quellschema oder Metadaten ein Rückidentifikationsrisiko darstellen.
Synthetische Daten sind besser geeignet, wenn:
- Große Datensätze simuliert werden müssen, ohne Verbindung zu realen Personen
- Compliance null Exposition gegenüber Produktionswerten erfordert
- Sie mit unstrukturierten Logs arbeiten oder große Sprachmodelle (LLMs) trainieren
Szenario: Warum synthetische Daten Maskierung übertreffen
Stellen Sie sich ein Data-Science-Team vor, das ein Anomalieerkennungsmodell trainiert. Maskierte Produktionsdaten bewahren die Struktur, aber verbleibende Korrelationen können weiterhin ein Rückidentifikationsrisiko darstellen. Synthetische Datensätze hingegen haben keine Verbindung zu realen Kunden. Das Team erhält statistisch treue Daten für KI-Pipelines, während Compliance-Beauftragte sicher sein können, dass keine identifizierbaren Daten die Produktion verlassen.
Synthetische Daten sind nicht nur ein Entwickler-Tool – sie beschleunigen Compliance. Durch die Generierung datenschutzkonformer Datensätze reduzieren Unternehmen regulatorische Risiken, fördern KI-Einführungen und ermöglichen sichere Zusammenarbeit mit Dienstleistern.
In Kombination mit Maskierung erzeugt synthetische Datengenerierung ein Hybridmodell: Beibehaltung der referenziellen Integrität für notwendige Workflows und vollständig künstliche Datensätze für Tests, Austausch oder KI-Training. Dieser gemischte Ansatz gewährleistet Compliance, ohne Innovation zu bremsen.
Synthetische Daten – Zusammenfassung, Schritte, Validierung
Zusammenfassung
- Ziel: Datenschutzkonforme Datensätze erstellen, die Schema und statistische Eigenschaften bewahren, ohne echte Datensätze preiszugeben.
- Einsatz: Externes Teilen, LLM-/ML-Training, Nicht-Prod-Bereitstellung oder Richtlinien, die keinen Bezug zu Individuen zulassen.
- Kombination: Mit Maskierung für hybride Workflows, die referenzielle Integrität in begrenzten Bereichen benötigen.
Implementierungsschritte
- Festlegung von Umfang & Zweck (QA, Analytics, LLM-Training, Vendor-Sharing).
- Katalogisierung von Schema, Einschränkungen und sensiblen Feldern (PII/PHI/PCI) zur Steuerung der Generatoren.
- Auswahl des Generierungsmodus (eingebaut/Policy-aware in Plattform oder Open-Source wie SDV/CTGAN/Mockaroo für Prototypen).
- Auswahl der Spaltenstrategien (Substitution, statistische Modelle, FPE bei notwendiger Formwahrung).
- Beibehaltung von Beziehungen (Schlüssel/Fremdschlüssel) oder Simulation mit deterministischen Regeln, wo nötig.
- Pilotierung auf Teilmenge; Parameter für Reproduzierbarkeit aufzeichnen.
- Qualitätsvalidierung (Verteilung, Korrelationen, Privatsphäre-Abstand); Generatoren anpassen.
- Planung von Aufgaben; Protokollierung und Zugangskontrolle gemäß Governance-Richtlinien.
Validierungscheckliste
| Prüfung | Was zu verifizieren ist | Hinweise |
|---|---|---|
| Verteilung | Durchschnitt/Varianz, Perzentile im Toleranzbereich | KS-Test je numerischer Spalte |
| Korrelationen | Wesentliche paarweise Korrelationen erhalten (±Δ) | Vergleich der Korrelationstabellen |
| Datenschutz | Keine synthetische Zeile zu nah an echten Proben | Abstand zum nächsten Nachbarn |
| Einschränkungen | Einzigartigkeit, Formate, Domänen eingehalten | Regex-/Bereichsprüfungen |
Schnellprüfungen
- Generatoren, Seeds und Regeln für Reproduzierbarkeit dokumentieren.
- Synthetische und echte Datensätze getrennt halten; Joins über Datentypen verbieten.
- Für UI-/Integrationstests mit strenger referenzieller Integrität einen hybriden Ansatz in Betracht ziehen (maskierte Basis + synthetische Erweiterungen).
- Für außerhalb der Organisation verwendete synthetische Datensätze dieselben Zugriffs- und Aufbewahrungsrichtlinien anwenden.
DataSunrise Einsatzfälle für synthetische Daten
| Einsatzfall | Beschreibung | Beispiel |
|---|---|---|
| Compliance-Tests | Simulierung realer Datensätze zur Validierung von Logik ohne Nutzung echter Kundendaten. | Ausführung von Betrugserkennungsalgorithmen auf generierten Banktransaktionen. |
| KI- & ML-Training | Training von Modellen mit realistischen, aber nicht identifizierbaren Datensätzen zur Vermeidung regulatorischer Verstöße. | Erstellung diagnostischer Modelle aus synthetischen medizinischen Datensätzen. |
| Staging & QA | Befüllung von Testumgebungen mit lebensechten Daten für UI-, Last- oder Integrationstests. | Füllen eines Entwicklungs-PostgreSQL-Clusters mit synthetischen Benutzerprofilen. |
| Sichere Zusammenarbeit | Weitergabe synthetischer Datensätze an Teams oder Partner ohne Freigabe sensibler Informationen. | Bereitstellung synthetischer HR-Datensätze für einen Analyse-Dienstleister. |
Was macht DataSunrise synthetische Daten anders?
Während viele Plattformen künstliche Datengenerierung bieten, integrieren nur wenige diese direkt in Unternehmenssicherheits- und Compliance-Pipelines. DataSunrise synthetische Daten-Tools sind eng mit Maskierung, Auditierung und Richtliniendurchsetzung gekoppelt – ideal für den realen Einsatz in regulierten Umgebungen.
- Integrierter Maskierungs-Fallback: Nahtloser Wechsel zwischen Maskierung und Generierung basierend auf Zugriffskontext oder Schema-Typ.
- Richtlinienbewusste Generierung: Definition von Erzeugungsregeln, die mit bestehenden Compliance-Filtern und sensiblen Datentags übereinstimmen.
- Geplante Arbeitsabläufe: Automatisierung der Erstellung synthetischer Datensätze über Umgebungen, Anwendungen und CI/CD-Pipelines hinweg.
- Audit-Protokollierung: Nachverfolgung jeder Generierungsaufgabe für volle Nachvollziehbarkeit und Audit-Bereitschaft.
Ob interne Apps getestet oder KI-Modelle trainiert werden – DataSunrise synthetische Daten geben Teams die Flexibilität, produktionsähnliche Workloads zu simulieren – ohne Risiko für produktive Daten.
Wie man synthetische Datengenerierung in DataSunrise konfiguriert
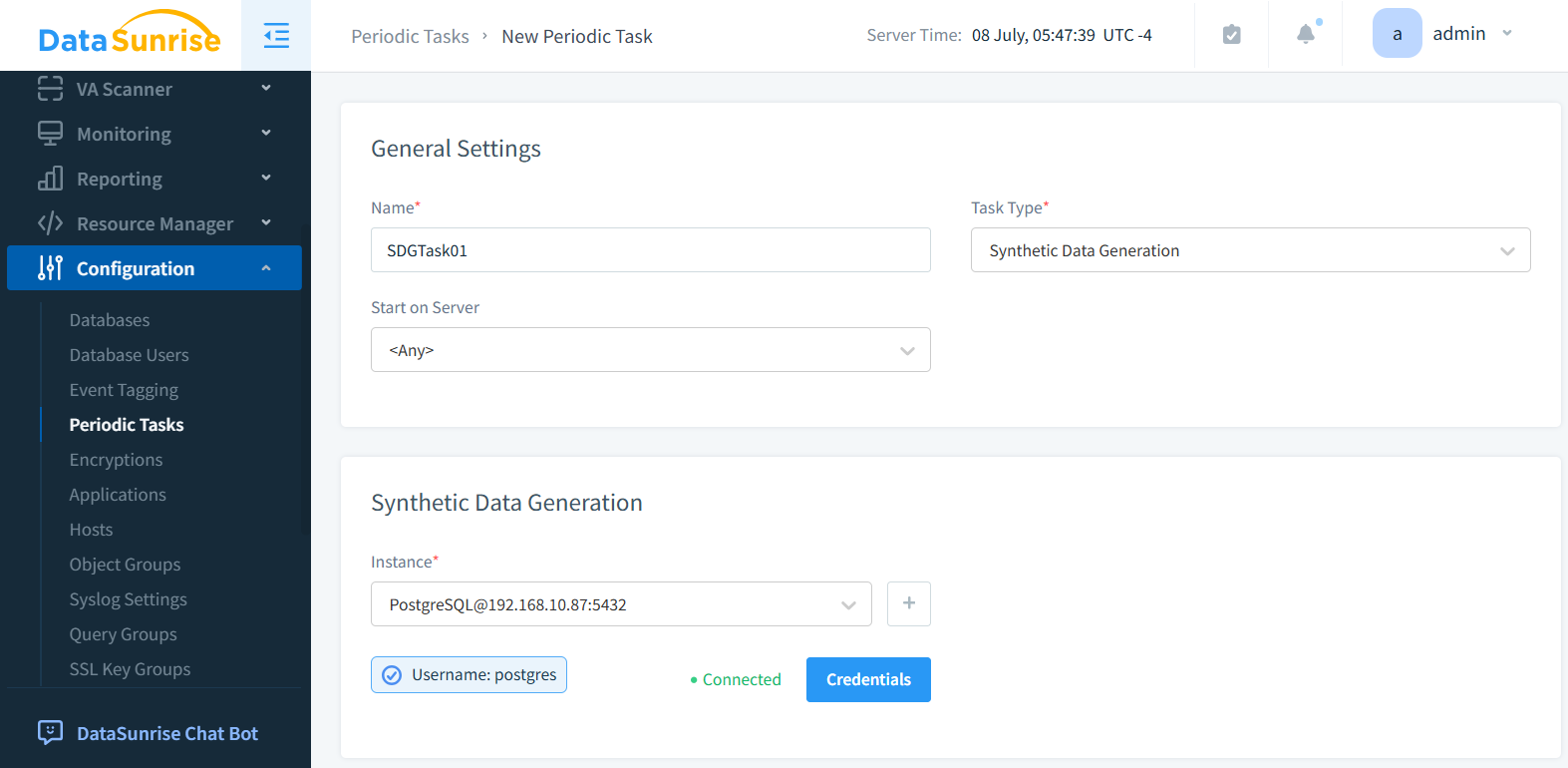
Schritt 1: Allgemeine Parameter festlegen
Wechseln Sie zu Konfiguration → Periodische Aufgaben und erstellen Sie eine neue Aufgabe. Wählen Sie „Synthetische Datengenerierung“ als Typ und benennen Sie die Aufgabe entsprechend.
Schritt 2: Datenbank-Instanz auswählen
Wählen Sie Ihre Zielinstanz. Im Beispiel wurde PostgreSQL als Datenbank-Engine ausgewählt.
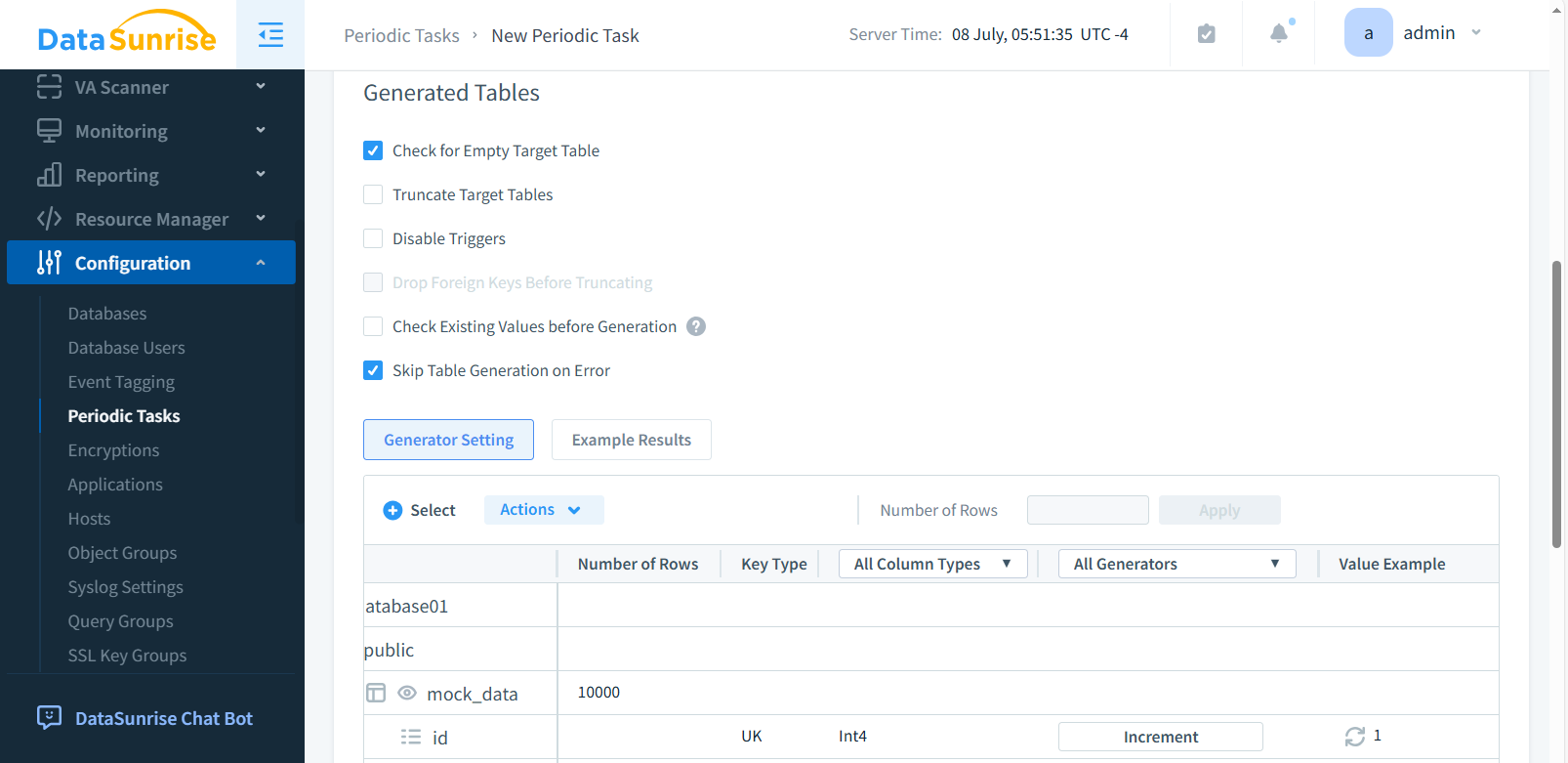
Schritt 3: Zieltabellen und Spalten definieren
Wählen Sie das Schema und die Tabellen, in die synthetische Daten eingefügt werden. Selektieren Sie spezifische Spalten, aktivieren Sie bei Bedarf „Tabelle leeren“ und konfigurieren Sie das Fehlerverhalten.
Schritt 4: Eingebaute oder benutzerdefinierte Generatoren verwenden
Wählen Sie aus eingebauten Wertgeneratoren (Namen, E-Mails, Zahlen, Daten) oder definieren Sie eigene Logiken über Konfiguration → Generatoren. Nützlich, um domänenspezifische Muster wie Patienten-IDs oder Steuercodes zu simulieren.
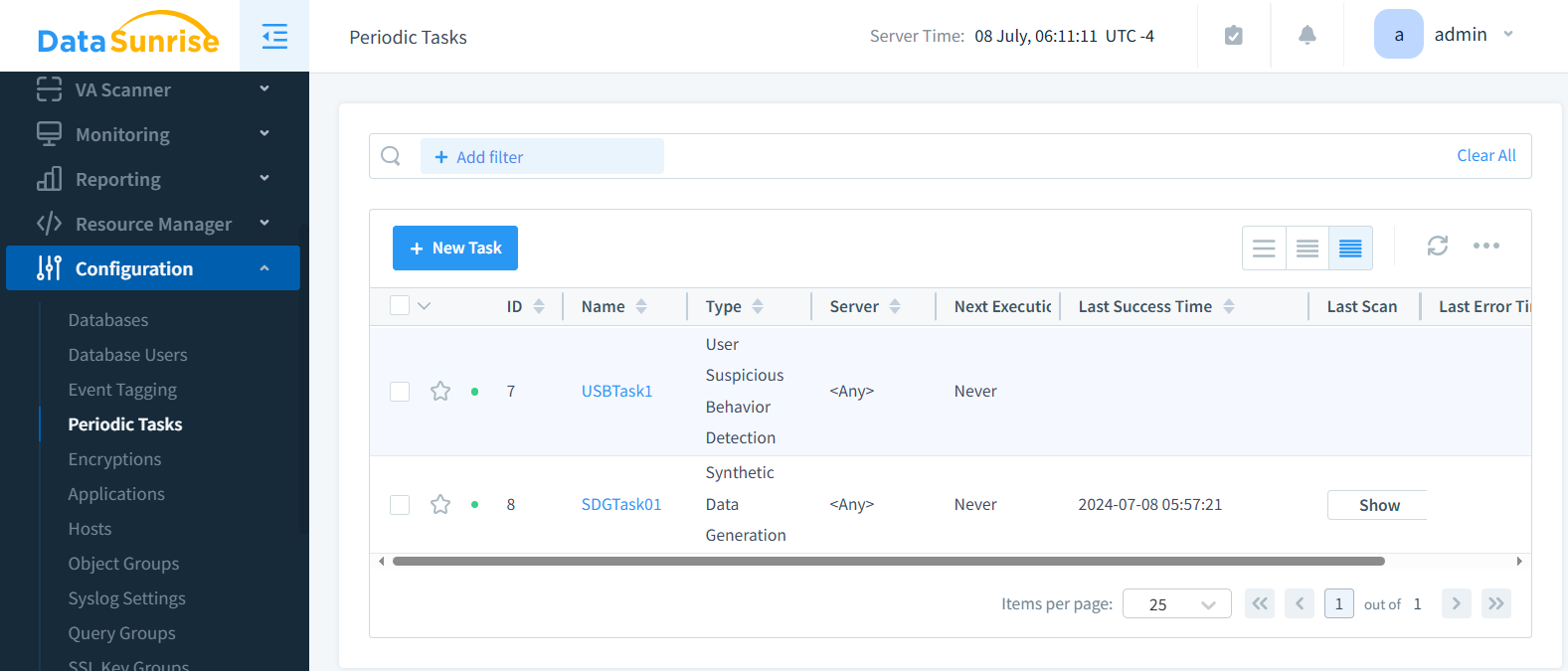
Schritt 5: Speichern, planen und ausführen
Nach dem Speichern erscheint die Aufgabe in der Jobliste. Sie kann manuell ausgeführt oder für periodische Läufe zur Datenaktualisierung geplant werden.
Kostenlose Tools und Bibliotheken für synthetische Daten
DataSunrise bietet umfassende Unterstützung für synthetische Generierung mit Maskierung, Auditierung und Compliance-Controls. Entwickler und Data Scientists profitieren aber auch von kostenlosen Alternativen beim Lernen oder Prototyping.
SDV (Synthetic Data Vault)
SDV ist ein Open-Source-Python-Framework, das statistische Modelle und GANs nutzt, um synthetische tabellarische Datensätze zu erzeugen. Unterstützt relationale und Multi-Table-Strukturen.
pip install sdv
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
real_data, metadata = download_demo(modality='single_table', dataset_name='fake_hotel_guests')
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
synthetic_data = synthesizer.sample(num_rows=500)
print(synthetic_data.head())
CTGAN
Ein GAN-basiertes Modell, das speziell für tabellarische Daten entwickelt wurde und gut mit unausgewogenen Datensätzen und gemischten Spaltentypen funktioniert. Siehe unseren früheren Artikel zur KI-Datengenerierung für Beispiel-Code.
Mockaroo
Mockaroo ist ein Webtool zur Erzeugung von Mock-Datensätzen in CSV, JSON, SQL und weiteren Formaten. Ideal für schnelle Prototypen und unterstützt benutzerdefinierte Feld-Schemata. Kostenlose Nutzung ist auf 1.000 Reihen pro Sitzung begrenzt.
Validierung der Qualität synthetischer Daten
Die Generierung synthetischer Datensätze ist nur der halbe Weg. Es gilt zu bestätigen, dass die Daten sich wie der reale Datensatz verhalten, ohne sensible Werte preiszugeben. Übliche Prüfungen sind:
- Ähnlichkeit der Verteilung: Vergleich der Spaltenverteilungen zwischen realen und synthetischen Daten.
- Erhalt von Korrelationen: Sicherstellen, dass Zusammenhänge zwischen Feldern erhalten bleiben.
- Datenschutz-Abstand: Bestätigung, dass kein synthetischer Datensatz zu nahe an einem realen Datensatz liegt.
Python-Beispiel: Kolmogorov-Smirnov-Test
from scipy.stats import ks_2samp
# Vergleich reale vs synthetische Spaltenverteilungen
ks_stat, p_value = ks_2samp(real_data["age"], synthetic_data["age"])
if p_value > 0.05:
print("Verteilung des synthetischen 'age' entspricht der realen")
else:
print("Signifikanter Unterschied festgestellt")
Prüfung der Korrelationsmatrix
import pandas as pd
real_corr = real_data.corr(numeric_only=True)
synth_corr = synthetic_data.corr(numeric_only=True)
diff = (real_corr - synth_corr).abs()
print(diff.head())
Diese Validierungsschritte stellen sicher, dass Ihre synthetischen Daten nützlich für Analysen und ML-Pipelines sind und gleichzeitig sicher für Compliance-Anforderungen bleiben.
Best Practices für generierte Daten
- Datenformate an folgende Systeme anpassen.
Stellen Sie sicher, dass synthetische Werte dieselben Muster, Datentypen, Bereiche, Formate und Einschränkungen einhalten, damit Anwendungen, Pipelines und Analysetools störungsfrei funktionieren. - Tabellenbeziehungen dort bewahren, wo nötig.
Behalten Sie Schlüsseldependenzen wie Primär-/Fremdschlüssel, Hierarchien und Lookup-Tabellen bei, um Workflows, Joins und Geschäftslogik korrekt zu erhalten. - Generierungsregeln dokumentieren.
Verfolgen Sie Logik, Seeds und Transformationsregeln zur Unterstützung konsistenter Reproduktion, Audits und Fehlerbehebung. - Auf Plausibilität prüfen.
Validieren Sie, dass Verteilungen, Bereiche und Verhaltensmuster realistisch aussehen – Unregelmäßigkeiten wie Ausreißer, leere Felder oder fehlerhafte Beziehungen früh erkennen. - Maskierung oder Ausschluss verwenden, um Überschneidungen mit echten Daten zu vermeiden.
Stellen Sie sicher, dass synthetische Werte nicht auf tatsächliche Kundendaten rückverfolgbar sind, um Re-Identifikationsrisiken zu minimieren und Compliance zu stärken.
Schnellvergleich
| Tool | Besonders geeignet für | Beschränkungen |
|---|---|---|
| SDV | Statistische Simulation tabellarischer Daten | Nur Python, Feinabstimmung erforderlich |
| CTGAN | Komplexe, unausgewogene Datensätze | Langsames Training, eventuell GPU notwendig |
| Mockaroo | Schnelle CSV/JSON/SQL-Prototypen | Zeilenlimit, Schema nicht erkennend |
Synthetische Daten in Compliance-Rahmenwerken
Synthetische Datengenerierung entspricht auf natürliche Weise modernen Vorschriften, indem sie direkte Identifikatoren entfernt und dennoch analytischen Wert bewahrt. Die Zuordnung zu gängigen Rahmenwerken lautet:
| Rahmenwerk | Anforderung | Wie synthetische Daten helfen |
|---|---|---|
| GDPR | Art. 32 – Pseudonymisierung und Minimierung personenbezogener Daten | Erzeugt künstliche Datensätze ohne Bezug zu realen Personen und erfüllt so Pseudonymisierungs- und Minimierungsanforderungen. |
| HIPAA | §164.514 – De-Identifikation von PHI-Kennungen | Erstellt nicht identifizierbare Gesundheitsdatensätze für Forschung und Tests bei gleichzeitiger PHI-Schutzfunktion. |
| PCI DSS | Req. 3.4 – Vermeidung der Speicherung von PAN in Testumgebungen | Synthetische Zahlungsdatensätze ermöglichen QA und Vendor-Sharing ohne Offenlegung echter Karteninhaberdaten. |
| SOX | §404 – Sicherstellung der Finanzdatenintegrität für Audits | Bietet revisionssichere Testdaten für die Validierung von Finanzsystemen ohne Risiko für Produktionsdaten. |
Durch die Ausrichtung synthetischer Generierung an diesen Rahmenwerken unterstützt DataSunrise Unternehmen dabei, die Einführung von KI und Analytik zu beschleunigen und gleichzeitig auditbereit und regelkonform zu bleiben.
Wenn synthetische Daten nicht ausreichen: Überlegungen und Kontrollmechanismen
Obwohl synthetisch erzeugte Daten starke Datenschutzgarantien und Flexibilität bieten, ersetzen sie nicht universell reale Daten oder unternehmensweite Maskierungsworkflows. Bestimmte Szenarien – wie Tests der referenziellen Integrität, deterministische Joins oder Langzeitanalysen – erfordern oft weiterhin kontrollierten Zugriff auf maskierte oder pseudonymisierte Datensätze.
Zur Sicherstellung, dass generierte Daten Ihre Ziele effektiv erfüllen, sollten Sie folgende Leitlinien beachten:
- Einsatzfall abgestimmt: Für Modellvalidierung vollständig synthetische Daten verwenden. Für Integrations- oder UI-Tests ggf. maskierte Produktionskopien bevorzugen.
- Governance dokumentieren: Nachverfolgen, welche Felder synthetisch erzeugt, welche erhalten und welche Tools oder Logiken verwendet wurden.
- Sampling vs. Simulation: Nicht verwechselt werden dürfen Zufalls-Stichproben echter Daten mit synthetischer Generierung. Nur letztere löst die Verbindung zu identifizierbaren Subjekten auf.
- Audit-Bereitschaft: Protokollierung aller Generierungsaufgaben, Aufbewahrungszeiten und Zugriffskontrollen vor allem bei Nutzung synthetischer Daten in gemeinsam genutzten Testpipelines mit Dienstleistern.
DataSunrise unterstützt diese Entscheidungen mit Automatisierung, Maskierungs-Fallback-Optionen und voller Sichtbarkeit über Datentypen und Umgebungen. Das Ergebnis sind sicherere, intelligentere und schnellere Daten-Workflows – ohne Abstriche bei der Compliance.
Zentrale Erkenntnisse für den Einsatz synthetischer Daten
- Wählen Sie synthetische Daten, wenn Compliance null Exposure echter Datensätze verlangt oder Daten extern geteilt werden sollen.
- Kombinieren Sie synthetische Generierung mit Maskierung für hybride Szenarien – bewahren Sie relationale Integrität, wo nötig, und ersetzen Sie risikoreiche Felder vollständig.
- Dokumentieren Sie Generierungsregeln, Aufbewahrungsrichtlinien und Zugriffssteuerungen, um Governance und Audit-Bereitschaft zu gewährleisten.
- Testen Sie synthetische Datensätze gegen reale Workflows, um Leistung, Genauigkeit und Kompatibilität sicherzustellen.
- Automatisieren Sie Generierungsaufgaben über Zeitplanung und CI/CD-Integration für konsistente, reproduzierbare Ergebnisse.
FAQ zu synthetischen Daten
Was sind synthetische Daten?
Synthetische Daten sind künstlich erzeugte Informationen, die Struktur und statistische Eigenschaften realer Datensätze widerspiegeln, aber keine echten Kundendaten enthalten. Sie ermöglichen sicheres Testen, Analysen und KI-Training ohne Datenschutzrisiko.
Worin unterscheiden sich synthetische Daten von Maskierung?
Maskierung verändert reale Werte, um Identifikatoren zu verschleiern und bewahrt dabei Schema und referenzielle Integrität. Synthetische Daten hingegen erzeugen vollständig künstliche Datensätze ohne Bezug zu realen Personen, was sie sicherer für externes Teilen und KI-Pipelines macht.
Wann sollten Organisationen synthetische Daten verwenden?
Synthetische Daten sind ideal für Anwendungsfälle, in denen Compliance keine Exposition echter Datensätze erlaubt – wie Zusammenarbeit mit Dienstleistern, Training großer Sprachmodelle oder Befüllung Nicht-Produktionsumgebungen im großen Maßstab.
Welche Compliance-Rahmenwerke unterstützen synthetische Daten?
Rahmenwerke wie GDPR, HIPAA und PCI DSS erkennen Pseudonymisierung und De-Identifikation an. Synthetische Generierung bietet einen effektiven Weg zur Einhaltung, wenn sie mit Governance-Richtlinien kombiniert wird.
Was sind die Einschränkungen synthetischer Daten?
Synthetische Daten replizieren nicht immer komplexe Joins, Langzeitverläufe oder seltene Ausreißermuster vollständig. Für solche Szenarien kombinieren viele Unternehmen Maskierung mit synthetischer Generierung in hybriden Workflows.
Wie unterstützt DataSunrise synthetische Daten?
DataSunrise integriert synthetische Datengenerierung mit Maskierung, Auditierung und Compliance-Berichterstattung. Es bietet richtlinienbewusste Generatoren, geplante Arbeitsabläufe und vollständige Audit-Trails.
Branchenanwendungen synthetischer Daten
Synthetische Daten unterstützen mehr als nur Tests – sie ermöglichen direkt Compliance und Innovation in verschiedenen Branchen:
- Finanzen: Erstellung künstlicher Transaktionslogs für Betrugsmodell-Training, erfüllt PCI DSS und SOX-Auditanforderungen ohne Offenlegung von PANs.
- Gesundheitswesen: Erzeugung de-identifizierter Patientendatensätze gemäß HIPAA, unterstützt sichere Forschung und KI-Entwicklung für Diagnosen.
- SaaS & Cloud: Bereitstellung GDPR-konformer Mandantendatensätze für Staging-Umgebungen, Validierung der Multi-Mandanten-Isolation.
- Öffentliche Verwaltung: Teilen von Bevölkerungsdatensätzen mit Auftragnehmern unter Einhaltung von GDPR und lokalen Datenschutzgesetzen.
- Einzelhandel & E-Commerce: Versorgung von Analyse-Pipelines mit synthetischen Kundendaten für Tests von Personalisierungs-Engines ohne Datenschutzrisiko.
Durch die Kontextualisierung synthetischer Daten für jede Branche beschleunigen Organisationen Innovationen und bleiben auditbereit und datenschutzkonform.
Die Zukunft der synthetischen Datengenerierung
Synthetische Daten entwickeln sich rasch von einem Testwerkzeug hin zu einem zentralelement einer Unternehmens-Datenstrategie. Während Unternehmen verantwortungsvolle Innovation anstreben, werden nächste Generationen synthetischer Datenplattformen KI-gesteuerte Generierung, Datenqualitätsvalidierung und automatisierte Compliance-Controls kombinieren, um realistische, aber vollständig anonymisierte Datensätze in großem Maßstab zu erzeugen. Diese Systeme reproduzieren nicht nur statistische Genauigkeit und strukturelle Integrität, sondern passen sich dynamisch an sich ändernde Datenmodelle, Datenschutzanforderungen und regulatorische Entwicklungen an.
Zukünftige Lösungen bieten nahtlose Integration mit komplementären Technologien wie Datenmaskierung, Überwachung von Datenbankaktivitäten und Erkennung sensibler Daten. Diese Interoperabilität ermöglicht es, je nach Kontext sicher zwischen echten, maskierten und synthetischen Datensätzen zu wechseln – für sichere Analytik, Modelltraining und externe Zusammenarbeit ohne Offenlegung regulierter Informationen. Mit der Zeit wird dieses adaptive Daten-Ökosystem Privatsphäre-schonende Innovation zur Norm statt zur Ausnahme machen. Funktionen wie Compliance-Automatisierung sorgen zusätzlich dafür, dass synthetische Datensätze konstant regulatorischen und unternehmensinternen Anforderungen genügen.
Für stark regulierte Bereiche wie Finanzen, Gesundheitswesen und öffentliche Verwaltung wird synthetische Datengenerierung das Gleichgewicht zwischen Compliance und Innovation neu definieren. Unternehmen können KI-Einführung beschleunigen, sicher mit Dritten zusammenarbeiten und nachweisbar belegen, dass keine authentischen Kundendaten jemals kontrollierte Umgebungen verlassen haben. Letztlich liegt die Zukunft synthetischer Datengenerierung in intelligenter Automatisierung und fortlaufender Regeltreue, wodurch Datenschutz zum Motor des Fortschritts wird – nicht zu seiner Bremse.
Fazit
Synthetische Daten sind zu einem Schlüsselinstrument moderner, datenschutzorientierter Datenmanagementstrategien geworden. Sie bieten eine sichere und regelkonforme Alternative zur Verwendung echter Produktionsdatensätze für Entwicklung, Tests, Analysen und maschinelles Lernen. Indem sie Struktur, statistische Eigenschaften und Zusammenhänge realer Daten abbilden – ohne personenbezogene oder geschützte Informationen zu speichern – ermöglichen sie Unternehmen sichere Innovation, Zusammenarbeit und Analyse. Dieser Privacy-by-Design-Ansatz minimiert Compliance-Risiken, reduziert Haftungsrisiken und unterstützt ethische KI-Implementierung in Branchen wie Finanzen, Gesundheitswesen, Telekommunikation und öffentlicher Sektor.
DataSunrise integriert synthetische Datengenerierung innerhalb seiner umfassenden Daten-Sicherheits- und Governance-Plattform. Durch automatisierte Richtliniendurchsetzung, fortschrittliche Maskierungslogik und detaillierte Audit-Trails stellt die Plattform sicher, dass synthetische Datensätze sowohl internen Governance-Rahmenwerken als auch externen Standards wie GDPR, HIPAA, SOX und PCI DSS entsprechen. Dadurch können Unternehmen realistische, aber vollständig anonymisierte Daten für KI-Training, Softwaretests und Drittanbieter-Kollaboration erstellen – ohne Risiko der Offenlegung sensibler oder vertraulicher Inhalte.
In Kombination mit Lösungen wie Database Activity Monitoring (DAM), Datenerkennung und dynamischer Maskierung werden synthetische Daten zum starken Enabler sicherer digitaler Transformation. Sie ermöglichen rasche Innovation bei gleichzeitiger Wahrung von Transparenz und Compliance und unterstützen verantwortungsvolles Experimentieren sowie kontinuierliche Verbesserung. Mit der Weiterentwicklung von Datenschutzvorschriften und KI-Technologie bleiben synthetische Daten ein grundlegender Baustein sicherer, ethischer und skalierbarer datengetriebener Innovation.
Nächste
