Anonymisation des données dans Percona Server pour MySQL
L’anonymisation des données dans Percona Server pour MySQL n’est pas une fonctionnalité de sécurité cosmétique. C’est un contrôle structurel utilisé lorsque des données de production réelles doivent être partagées en dehors de leur périmètre de confiance initial sans exposer les identités, les identifiants ou les attributs réglementés. En pratique, l’anonymisation réduit les risques d’exposition à long terme et soutient directement les stratégies plus larges de sécurité des données.
Contrairement à l’audit ou au suivi d’activité, l’anonymisation modifie les données elles-mêmes. L’objectif est de supprimer de manière permanente la capacité d’identifier les individus tout en conservant suffisamment de structure pour les tests, analyses et flux de travail de développement. Cette approche est particulièrement importante lors du traitement des informations personnelles identifiables (IPI) et d’autres catégories de données réglementées.
Cet article explique comment fonctionne l’anonymisation dans Percona Server pour MySQL en utilisant des techniques SQL natives, où ces approches montrent leurs limites, et comment les plateformes centralisées étendent l’anonymisation en un processus gouverné et répétable conforme aux réglementations de conformité des données et aux exigences de sécurité.
Que signifie l’anonymisation des données dans le contexte MySQL
L’anonymisation des données est la transformation irréversible des valeurs sensibles afin que les personnes concernées ne puissent être ré-identifiées, même par les administrateurs. Une fois appliquées, les données anonymisées sortent généralement du champ des réglementations de conformité des données et réduisent significativement les risques à long terme liés à la sécurité des données.
Dans les systèmes basés sur MySQL, l’anonymisation est utilisée lorsque les données de production sont réutilisées pour des tests, des analyses ou stockées en dehors d’environnements contrôlés. Elle est couramment appliquée aux identifiants personnels, aux attributs financiers ainsi qu’aux données comportementales ou de localisation, en particulier dans les flux non productifs et les scénarios de gestion des données de test.
Contrairement à la surveillance de l’activité des bases de données ou les contrôles d’accès basés sur le principe du moindre privilège, l’anonymisation protège les données au repos en remplaçant entièrement les valeurs sensibles. Une fois anonymisées, les données peuvent être exportées, répliquées ou archivées sans contrôles d’exécution supplémentaires.
Techniques natives d’anonymisation des données dans Percona Server pour MySQL
Percona Server pour MySQL ne fournit pas de moteur d’anonymisation natif, de modèle de politique ou de contrôles de cycle de vie pour les données anonymisées. Il n’existe aucun mécanisme intégré pour identifier les colonnes sensibles, appliquer le périmètre d’anonymisation ou valider les résultats. En conséquence, l’anonymisation est mise en œuvre en combinant des primitives SQL standards telles que UPDATE, des fonctions, des jointures et des tables auxiliaires.
Ces approches peuvent réaliser des transformations irréversibles, mais dépendent entièrement d’une logique manuelle et d’une discipline opérationnelle.
Remplacement déterministe avec des instructions UPDATE
La technique d’anonymisation la plus directe consiste à écraser les colonnes sensibles avec des valeurs générées ou synthétiques. Cette méthode est couramment utilisée lors de la préparation de copies de bases de données de production pour les tests ou le développement.
UPDATE customers
SET
email = CONCAT('user_', id, '@example.com'),
phone = NULL,
full_name = CONCAT('Customer_', id),
address = 'REDACTED',
birth_date = NULL;
Cette approche préserve les clés primaires et le nombre de lignes, ce qui aide à maintenir une stabilité référentielle basique. Les systèmes en aval dépendant des identifiants tels que id continuent de fonctionner pendant que les données personnelles réelles sont supprimées.
Cependant, cette méthode ne s’adapte pas bien à grande échelle. Chaque table nécessite sa propre logique d’anonymisation, et chaque colonne sensible doit être gérée explicitement. Si une nouvelle colonne est ajoutée ultérieurement, elle restera non anonymisée à moins que le script ne soit mis à jour. La cohérence référentielle entre les tables liées doit être maintenue manuellement, et l’ordre d’exécution devient critique dans les schémas avec des identifiants partagés. Il n’existe aucun mécanisme intégré pour valider que l’anonymisation est complète, et une fois exécutée, il est impossible d’annuler sans restauration à partir d’une sauvegarde. Les données originales sont détruites de manière permanente.
Anonymisation basée sur le hachage
Le hachage remplace les valeurs sensibles par des condensats de longueur fixe, supprimant ainsi leur lisibilité tout en préservant leur unicité. Cette technique est parfois utilisée lorsqu’une corrélation ou une déduplication est requise sans exposer les valeurs originales.
UPDATE users
SET
national_id = SHA2(CONCAT(national_id, 'static_salt_123'), 256),
email = SHA2(CONCAT(email, 'static_salt_123'), 256);
L’anonymisation par hachage est irréversible, mais elle introduit des risques subtils. Des sels prévisibles ou réutilisés affaiblissent la protection et rendent les hachages vulnérables à l’inférence. Comme des entrées identiques produisent toujours des hachages identiques, les relations entre tables et ensembles de données restent visibles.
UPDATE payments
SET
payer_id = SHA2(CONCAT(payer_id, 'static_salt_123'), 256);
La cohérence des relations entre tables dépend désormais de l’utilisation exacte de la même logique de hachage et de salage partout. Toute déviation rompt les jointures et corrélations. De plus, les valeurs hachées peuvent encore être considérées comme des données personnelles selon certaines réglementations, en fonction du contexte et du risque de ré-identification. À mesure que les jeux de données grandissent, la gestion des sels et le respect d’un hachage cohérent à travers les environnements deviennent fragiles et sujettes aux erreurs.
Tables de substitution par jetons
Une technique plus contrôlée utilise des tables de correspondance qui relient les valeurs originales à des jetons synthétiques. Cela permet aux données anonymisées de rester réalistes tout en empêchant l’identification directe.
CREATE TABLE token_emails (
original_email VARCHAR(255),
token_email VARCHAR(255)
);
INSERT INTO token_emails VALUES
('[email protected]', '[email protected]'),
('[email protected]', '[email protected]');
L’anonymisation est ensuite appliquée par remplacement via jointure :
UPDATE orders o
JOIN token_emails t
ON o.email = t.original_email
SET
o.email = t.token_email;
Cette approche améliore la qualité des données pour les tests et analyses, mais augmente considérablement la charge opérationnelle. La génération des jetons doit éviter les collisions, les jetons doivent rester cohérents entre toutes les tables liées, et leur réutilisation doit être soigneusement contrôlée pour prévenir toute possibilité d’inférence. Avec le temps, les tables de jetons elles-mêmes deviennent des actifs sensibles nécessitant protection, rotation et contrôle d’accès. Sans gouvernance centralisée, la gestion du cycle de vie des jetons devient rapidement difficile à maintenir et à auditer.
Anonymisation centralisée des données avec DataSunrise
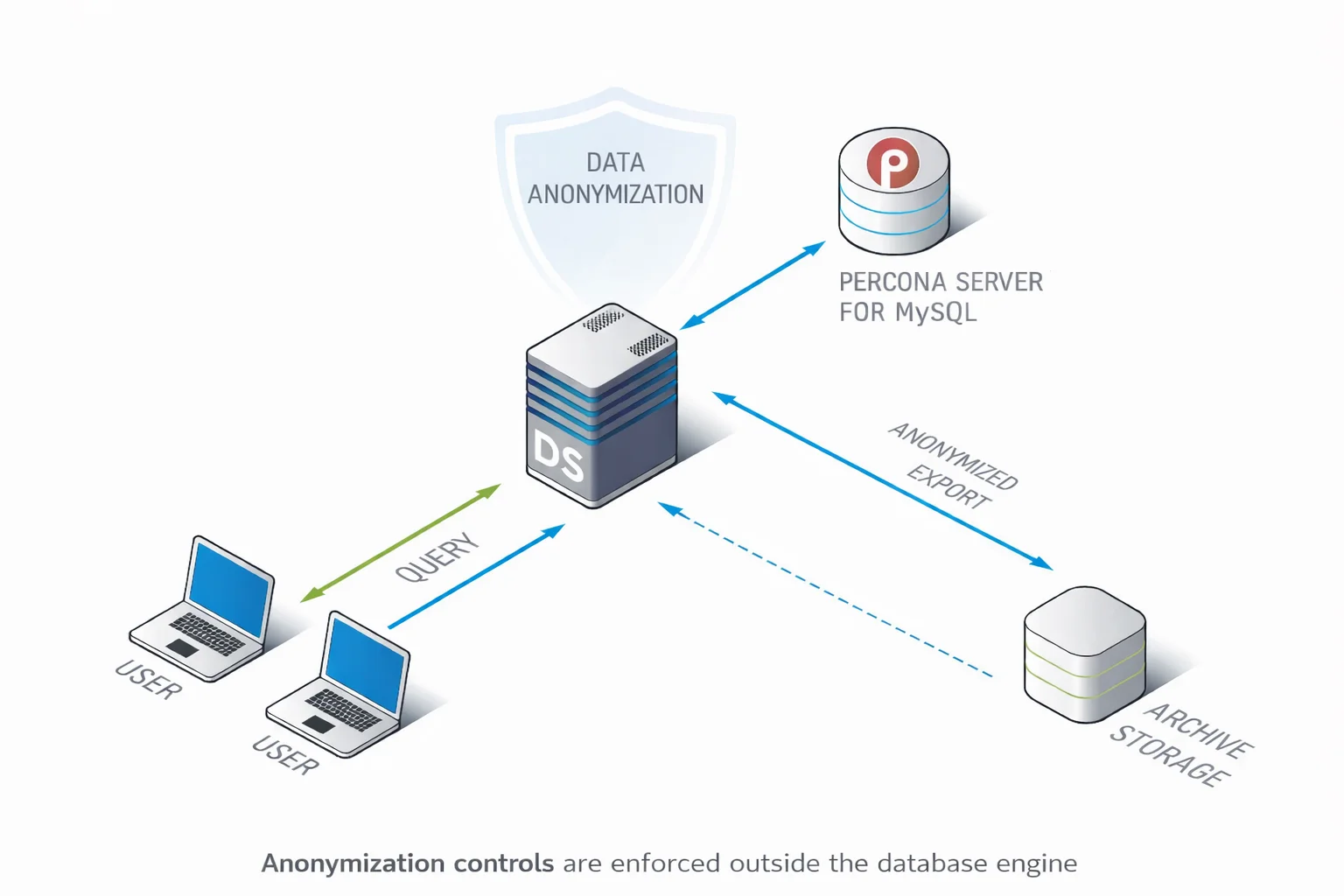
DataSunrise considère l’anonymisation des données comme un processus de sécurité gouverné plutôt qu’une opération SQL destructive et ponctuelle. Plutôt que d’intégrer une logique irréversible dans les schémas de base de données ou de maintenir des scripts d’anonymisation fragiles, les règles d’anonymisation sont définies de manière centralisée et appliquées de façon cohérente dans les environnements Percona Server pour MySQL.
Cette approche dissocie la logique d’anonymisation de la structure de base de données. Les bases restent intactes, tandis que l’anonymisation est appliquée comme une couche de transformation contrôlée. Ainsi, les mêmes politiques peuvent être réutilisées sur les répliques de production, les environnements de test, les exportations et les archives, sans réécriture SQL ni risque de résultats incohérents.
L’anonymisation centralisée apporte également une visibilité et un contrôle absents des approches natives. Les administrateurs peuvent savoir quelles données ont été anonymisées, comment elles ont été transformées et où ces transformations ont été appliquées.
Découverte des données sensibles
Le processus commence par la découverte automatisée des données sensibles. Plutôt que de s’appuyer sur des revues manuelles des schémas, DataSunrise analyse les bases de données pour identifier les données personnelles, les attributs financiers, les identifiants et autres champs réglementés. La découverte opère au niveau des colonnes et prend en compte à la fois les motifs de dénomination et le contenu des données, réduisant ainsi le risque d’oubli d’identifiants cachés.
Cette étape établit un périmètre vérifié pour l’anonymisation, garantissant que la protection s’applique à toutes les données concernées plutôt qu’à un sous-ensemble approximatif.
Définition des politiques
Une fois les données sensibles identifiées, les politiques d’anonymisation sont définies de manière centralisée. Ces politiques spécifient comment les différentes catégories de données doivent être transformées, par exemple par remplacement par des valeurs synthétiques, tokenisation ou anonymisation irréversible.
Les politiques sont réutilisables et versionnées. La même logique d’anonymisation peut être appliquée de manière cohérente sur plusieurs bases de données et environnements, éliminant la divergence causée par des scripts SQL copiés-collés. Toute modification des politiques se propage automatiquement sans changer les schémas de bases ou le code applicatif.
Sélection du mode d’exécution
L’anonymisation est ensuite appliquée en fonction du contexte d’exécution plutôt que par SQL codé en dur. Cela permet aux organisations de contrôler où et quand l’anonymisation s’opère sans dupliquer la logique.
Les cibles d’exécution typiques incluent les environnements de test et développement, les exportations de données partagées avec des tiers, les répliques de base utilisées pour l’analyse, et les jeux de données archivés conservés à long terme. Chaque contexte peut réutiliser les mêmes politiques tout en restant isolé opérationnellement.
Ce modèle garantit que les systèmes de production restent intacts alors que les consommateurs de données en aval reçoivent des jeux de données anonymisés et sécurisés.
Vérification et rapports
Après exécution, DataSunrise fournit des capacités de vérification et de reporting absentes des approches natives. Les administrateurs peuvent confirmer quels ensembles de données ont été anonymisés, quelles politiques ont été appliquées et si la couverture était complète.
Ces rapports servent de preuves pour les revues de sécurité internes et les audits de conformité externes. Plutôt que de se fier à la confiance dans des scripts, les organisations disposent d’une preuve documentée que l’anonymisation a été appliquée de manière cohérente et correcte.
En transformant l’anonymisation en un flux de travail géré plutôt qu’en une tâche destructrice effectuée en SQL, l’anonymisation centralisée élimine l’incertitude, réduit les risques opérationnels et se déploie à l’échelle dans plusieurs environnements sans complexification.
Impact métier d’une anonymisation correcte des données
| Domaine d’activité | Impact |
|---|---|
| Risque de sécurité | Réduction de l’impact des violations en supprimant les données sensibles exploitables des systèmes non productifs et des jeux de données partagés |
| Efficacité opérationnelle | Provisionnement plus rapide des environnements de test, assurance qualité et analyse sans attendre un nettoyage manuel des données |
| Conformité | Réduction du champ d’audit de conformité en excluant les jeux de données anonymisés du contrôle réglementaire |
| Fiabilité de l’ingénierie | Élimination des erreurs humaines liées aux scripts d’anonymisation SQL manuels |
| Gouvernance des données | Séparation claire et applicable entre données de production et données non productives |
Une anonymisation correcte décale la sécurité vers la phase amont. Les données sensibles sont supprimées avant de se propager dans des environnements où les contrôles d’accès, la surveillance et la discipline opérationnelle sont plus faibles. Plutôt que d’essayer de protéger les données partout, les organisations préviennent l’exposition à la source.
Conclusion
Percona Server pour MySQL offre suffisamment de flexibilité pour implémenter une anonymisation de données basique à l’aide de techniques SQL natives. Pour des petits jeux de données et des opérations ponctuelles, cette approche peut être suffisante, surtout lorsque l’anonymisation est bien ciblée et contrôlée manuellement. Cependant, même dans ces cas, l’anonymisation doit être considérée comme une partie intégrante des pratiques plus larges de sécurité des données plutôt que comme une tâche de maintenance isolée.
À mesure que les environnements se développent et que les réglementations de conformité des données se renforcent, l’anonymisation manuelle devient rapidement fragile, opaque et difficile à valider. Les scripts dérivent, les colonnes sensibles sont oubliées, et il n’existe aucun moyen fiable de prouver que l’anonymisation a été appliquée de manière cohérente sur les jeux de données de test, d’analyse et d’archivage. Cela pose un problème particulier dans les workflows à grande échelle de gestion des données de test où les données sont souvent copiées et réutilisées.
Les plateformes centralisées telles que DataSunrise transforment l’anonymisation en un processus contrôlé, auditable et répétable. En combinant une découverte automatisée des données sensibles, des transformations pilotées par des politiques, et un reporting prêt pour la conformité, l’anonymisation devient une composante de l’architecture de sécurité plutôt qu’un ajout destructeur de dernière minute. Ce modèle centralisé s’aligne aussi naturellement avec d’autres mécanismes de protection, y compris le masquage dynamique des données, sans dupliquer la logique ni augmenter la charge opérationnelle.
Lorsqu’elle est réalisée correctement, l’anonymisation ne consiste pas seulement à cacher les données. Elle consiste à supprimer le risque à la source, avant que les informations sensibles ne se propagent dans des environnements où elles n’ont plus leur place.
