Comment appliquer la gouvernance des données pour Apache Cassandra
Introduction
Apache Cassandra est une base de données NoSQL distribuée, reconnue pour gérer des charges de travail critiques à grande échelle sur des clusters et plusieurs centres de données. Avec sa haute disponibilité et sa tolérance aux pannes, Cassandra est souvent déployé dans des environnements où des informations sensibles telles que des transactions financières, des dossiers médicaux ou des profils clients doivent être gérées de manière responsable.
Cela soulève la question suivante : comment appliquer la gouvernance des données pour Apache Cassandra afin que les organisations restent conformes, sécurisées et efficaces ? La gouvernance des données dans ce contexte signifie définir, contrôler et surveiller comment les données sont accessibles, utilisées et protégées à travers le système.
Avant de plonger dans les cadres de gouvernance, il peut être utile de revoir les concepts généraux de conformité des données et les obligations réglementaires telles que le RGPD ou la HIPAA.
Ce que Cassandra offre nativement pour la gouvernance des données
Cassandra fournit des fonctionnalités de gouvernance basiques, mais toutes sont désactivées par défaut et nécessitent une configuration manuelle importante, qui se fait principalement via la modification du fichier cassandra.yaml. Explorons ce qui est réellement disponible—et la réalité de leur mise en œuvre.
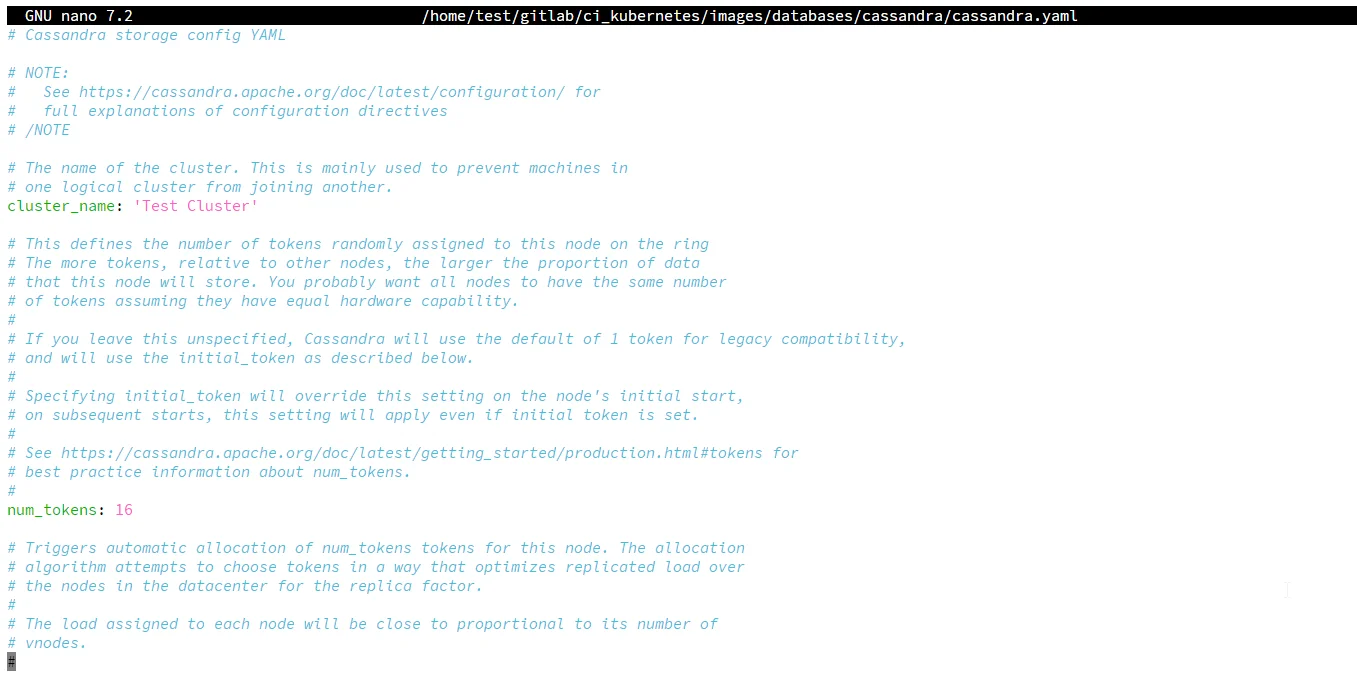
Contrôle d’accès basé sur les rôles (RBAC)
Prérequis (souvent non documentés) :
# Doit modifier cassandra.yaml sur CHAQUE nœud
authenticator: PasswordAuthenticator # Par défaut : AllowAllAuthenticator
authorizer: CassandraAuthorizer # Par défaut : AllowAllAuthorizer
role_manager: CassandraRoleManager
Après le redémarrage du cluster, vous pouvez créer des rôles :
-- D'abord, créer l'espace de clés (souvent oublié dans les docs)
CREATE KEYSPACE IF NOT EXISTS customer_data
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 3};
-- Puis créer un rôle
CREATE ROLE analyst WITH LOGIN = true AND PASSWORD = 'strongPassword';
GRANT SELECT ON KEYSPACE customer_data TO analyst;
Limitations :
- Pas de hiérarchie ou d’héritage de rôles
- Pas de contrôle d’accès basé sur le temps
- Pas de permissions conditionnelles (par ex., « accès uniquement pendant les heures ouvrables »)
- Les changements de mot de passe nécessitent des commandes CQL manuelles sur chaque nœud
Journalisation d’audit : complexe et locale à chaque nœud
Objectif visé : Suivre toute l’activité de la base de données pour la conformité.
Considérations de mise en œuvre : La journalisation d’audit nécessite une configuration minutieuse et produit des logs binaires locaux à chaque nœud qui doivent être agrégés :
audit_logging_options:
enabled: true # Par défaut : false
logger:
- class_name: BinAuditLogger # Structure correcte (pas seulement "BinAuditLogger")
audit_logs_dir: /var/log/cassandra/audit # OBLIGATOIRE mais souvent absent dans les exemples
included_categories: DML, DDL, AUTH # Doit spécifier ce qui doit être audité
excluded_keyspaces: system, system_schema # Éviter la journalisation des opérations système
roll_cycle: HOURLY
block: true # Critique : garantit aucune perte d’audit
max_log_size: 17179869184 # Limite de 16 Gio par fichier
Principales limitations :
- Les journaux sont dispersés sur chaque nœud sous format binaire
- Pas d’agrégation ou centralisation des journaux intégrée
- Ne capture pas les tentatives d’authentification échouées
- Nécessite des outils personnalisés pour le traitement et l’analyse
- Pas de fonctionnalités d’alerte en temps réel
Masquage des données : limité à la version et dépendant du schéma
Disponible uniquement dans Cassandra 5.0+, et désactivé par défaut :
# Doit être activé dans cassandra.yaml au préalable
dynamic_data_masking_enabled: true # Par défaut : false
Après redémarrage, vous pouvez créer des tables masquées :
-- Nécessite d’abord l’espace de clés
CREATE KEYSPACE IF NOT EXISTS healthcare
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
USE healthcare;
-- Puis créer la table masquée
CREATE TABLE patients (
id UUID PRIMARY KEY,
name TEXT MASKED WITH mask_inner(1, null),
birth DATE MASKED WITH mask_default()
);
Limitations critiques :
- Non disponible dans Cassandra 3.x ou 4.x (majorité des déploiements en production)
- Impossible de masquer des tables existantes sans les supprimer et recréer
- Les règles de masquage sont codées en dur dans le schéma (non dynamiques)
- Pas de masquage contextuel (même masque pour tous les utilisateurs)
- Impact sur les performances peu documenté
Défis et considérations de mise en œuvre
| Complexité de configuration | Limitations opérationnelles | Considérations de conformité |
|---|---|---|
| Fonctionnalités désactivées par défaut | Pas de tableau de bord de gouvernance unifié | Gestion manuelle des politiques et de la rétention |
| Édition YAML manuelle sur chaque nœud | Journaux d’audit nécessitant des parseurs personnalisés/aggrégation | Dépendance à des outils spécifiques à Cassandra |
| Redémarrages du cluster après chaque changement | Gestion des rôles uniquement via commandes CQL | Génération manuelle de rapports |
| Aucune validation avant l’exécution | Intégration limitée aux systèmes d’identités d’entreprise | Classification et découverte manuelles des données |
Pour les organisations gérant plusieurs bases de données (MySQL, PostgreSQL, MongoDB en parallèle de Cassandra), maintenir des systèmes de gouvernance séparés pour chacune devient rapidement insoutenable.
Comment mettre en œuvre une gouvernance complète avec DataSunrise
Contrairement à l’approche fragmentée native de Cassandra, DataSunrise propose une plateforme de gouvernance unifiée. Voici comment obtenir une gouvernance complète en seulement quelques étapes :
Étape 1 : Déployer DataSunrise (Installation en 15 minutes)
Sans modification YAML, sans redémarrages, sans interruption :
- Installer DataSunrise entre vos applications et Cassandra
- Configurer la connexion à votre cluster Cassandra via l’interface web
- DataSunrise découvre automatiquement tous les espaces de clés, tables et colonnes
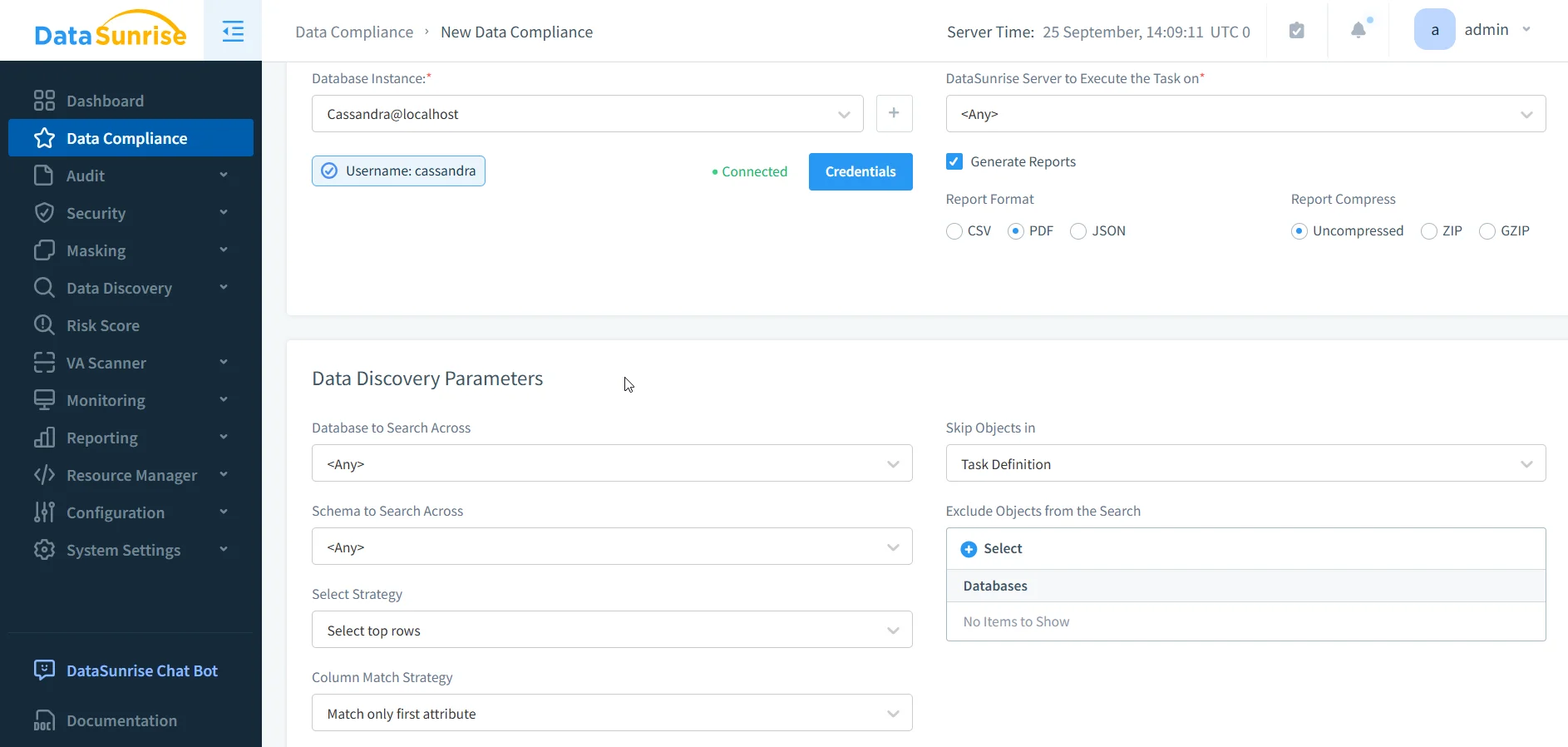
Étape 2 : Configurer la conformité des données automatique dans DataSunrise (Configuration en 5 minutes)
Il suffit de naviguer vers « Conformité des données » dans le menu à gauche, de sélectionner la base de données cible et les réglementations applicables (RGPD, HIPAA, PCI DSS, SOX), puis de lancer la découverte des données.
DataSunrise va automatiquement :
- Détecter les données sensibles (Données personnelles, données de santé, PCI, et motifs personnalisés).
- Activer l’audit à l’échelle du cluster avec stockage centralisé et recherche en temps réel.
- Appliquer des politiques de masquage dynamiques par rôle et contexte.
- Configurer des contrôles de sécurité/pare-feu contre les requêtes à haut risque.
- Générer des rapports de conformité automatisés, vous tenant prêt pour tout contrôle.
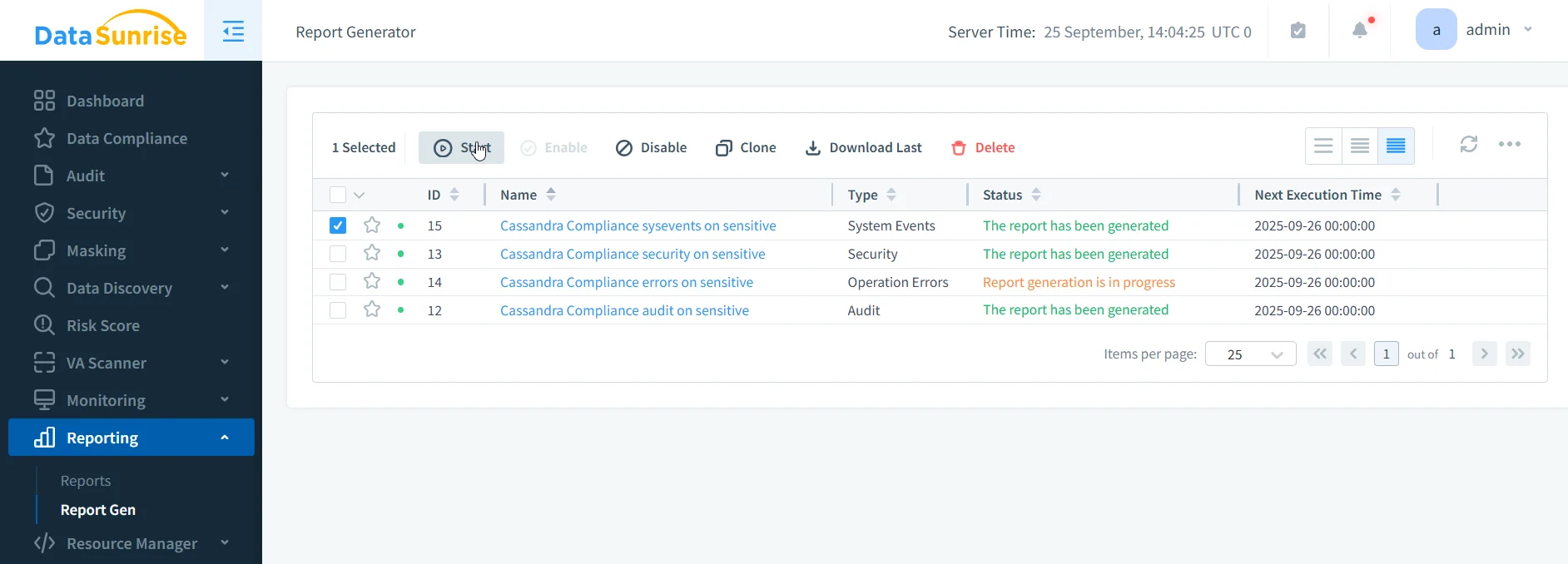
Étape 3 : Générer des rapports de conformité (en 1 clic)
Accédez à Reporting → Génération de rapports :
- RGPD : Activités de traitement, politiques de conservation, journaux d’accès
- HIPAA : Audit d’accès aux données de santé, état du chiffrement, activité utilisateur
- PCI DSS : Accès aux données des titulaires de carte, vérification des contrôles de sécurité
- SOX : Accès aux données financières, gestion des changements, séparation des fonctions
Les rapports sont prêts pour l’audit et incluent toute la documentation requise.
Impact commercial de l’application de la gouvernance des données
Appliquer une gouvernance structurée des données avec Cassandra et DataSunrise apporte des bénéfices mesurables :
| Objectif de gouvernance | Cassandra natif | Avec DataSunrise |
|---|---|---|
| Contrôle d’accès basé sur les rôles | ✅ RBAC basique | ✅ RBAC avancé, politiques centralisées |
| Piste d’audit | ⚠ Détails limités | ✅ Détails complets, exportables, intégration SIEM |
| Masquage des données | ⚠ Partiel (5.0+) | ✅ Dynamique, statique, cohérent |
| Automatisation de la conformité | ❌ Manuelle uniquement | ✅ Modèles et rapports préconstruits |
| Détection des menaces | ❌ Non disponible | ✅ Analyse comportementale, alertes |
Ces améliorations réduisent non seulement les risques de non-conformité, mais streamline également les opérations internes et améliorent la confiance avec les clients et les auditeurs.
Conclusion
Lors de la planification de l’application de la gouvernance des données pour Apache Cassandra, les organisations doivent considérer à la fois les fonctionnalités natives et les plateformes de gouvernance externes. Alors que Cassandra offre des contrôles de base tels que RBAC, journalisation d’audit et masquage, les exigences avancées nécessitent une solution intégrée.
DataSunrise fournit un cadre de gouvernance unifié avec une conformité automatisée, une audit détaillé et une protection en temps réel. Cette combinaison aide les entreprises à répondre aux exigences réglementaires tout en maintenant des environnements Cassandra efficaces, sécurisés et résilients.
Si vous êtes prêt à améliorer la gouvernance sur votre déploiement Cassandra, planifiez une démonstration pour découvrir les capacités de DataSunrise en action.
Protégez vos données avec DataSunrise
Sécurisez vos données à chaque niveau avec DataSunrise. Détectez les menaces en temps réel grâce à la surveillance des activités, au masquage des données et au pare-feu de base de données. Appliquez la conformité des données, découvrez les données sensibles et protégez les charges de travail via plus de 50 intégrations supportées pour le cloud, sur site et les systèmes de données basés sur l'IA.
Commencez à protéger vos données critiques dès aujourd’hui
Demander une démo Télécharger maintenantSuivant
