Comment automatiser la conformité des données pour Apache Cassandra
Introduction
Apache Cassandra est reconnue pour ses performances élevées et ses charges de travail distribuées dans des secteurs souvent soumis à des exigences réglementaires strictes. Mais lorsqu’il s’agit d’automatiser la conformité, les capacités natives de Cassandra sont limitées. La journalisation d’audit, la capture des requêtes et les contrôles d’accès basés sur les rôles existent, mais nécessitent une configuration nœud par nœud, des modifications YAML et des scripts manuels pour centraliser les résultats.
Cet article explore ce que Cassandra peut faire nativement, mais se concentre sur comment automatiser la conformité des données pour Apache Cassandra avec DataSunrise. L’objectif : réduire les tâches manuelles répétitives et créer un environnement durable, prêt à l’audit.
Cassandra natif : automatisation limitée
Cassandra offre des fonctionnalités importantes pour la conformité, mais ses capacités d’automatisation sont très restreintes. La plupart des tâches qui paraissent automatisées sont en réalité des actions manuelles à répéter sur chaque nœud ou à maintenir via des scripts.
- Journalisation d’audit : activée nœud par nœud via
cassandra.yaml. Manque de centralisation ou d’alertes intégrées. - Journalisation complète des requêtes (FQL) : permet aux administrateurs de rejouer des requêtes pour analyse, mais nécessite une activation/désactivation manuelle et ne capture pas les tentatives échouées.
- RBAC : les permissions peuvent être scriptées, mais Cassandra n’a pas de planificateur pour des revues régulières des accès ou des droits temporaires.
- Masquage dynamique (5.0+) : au niveau du schéma et statique. Chaque mise à jour requiert des modifications DDL ; il n’y a pas d’automatisation pilotée par la politique ou contextuelle.
Exemple : automatiser l’accès avec RBAC
Même la gestion des rôles, qui semble être un candidat naturel pour l’automatisation, nécessite d’écrire des scripts CQL personnalisés.
-- Créer un rôle d’auditeur de conformité
CREATE ROLE compliance_auditor
WITH LOGIN = true
AND PASSWORD = 'StrongPass#2025'
AND SUPERUSER = false;
-- Accorder un accès en lecture seule à finance_data
GRANT SELECT ON KEYSPACE finance_data TO compliance_auditor;
-- Révoquer les permissions manuellement (pas d’expiration automatique disponible)
REVOKE SELECT ON KEYSPACE finance_data FROM compliance_auditor;
Bien que vous puissiez encapsuler ces commandes dans un script pour simuler une automatisation, Cassandra ne fournit pas :
- de dates d’expiration pour les rôles (par ex., révoquer automatiquement l’accès temporaire d’un auditeur).
- de revues d’accès planifiées pour vérifier les permissions non utilisées ou risquées.
- de détection de dérive pour alerter lorsque les rôles ne correspondent plus à la politique.
Exemple : journalisation complète des requêtes
FQL ajoute de la visibilité, mais l’automatisation est limitée :
# Activer la journalisation complète des requêtes
$ nodetool enablefullquerylog --path /var/log/cassandra/fql
# Rejouer manuellement les requêtes
$ bin/fqltool replay --target localhost:9042 /var/log/cassandra/fql
Cela capture les requêtes mais seulement celles réussies, ce qui signifie que les équipes conformité ont besoin d’outils supplémentaires pour couvrir les échecs d’authentification ou les instructions rejetées.
Automatiser la conformité des données pour Apache Cassandra avec DataSunrise
DataSunrise propose une véritable couche d’automatisation de la conformité pour Cassandra. Elle s’intercale de manière transparente entre les applications et la base de données, appliquant les politiques de manière cohérente sur tout le cluster sans nécessiter de modifications de configuration ni redémarrage.
Étape 1 : Découvrir et classifier les données sensibles
- Accédez à Conformité des données → Découverte.
- Sélectionnez votre instance Cassandra et lancez une analyse.
- DataSunrise utilise le NLP et la reconnaissance de motifs pour identifier automatiquement les informations personnelles (PII), données de santé (PHI), données PCI et motifs personnalisés.
- L’analyse produit une cartographie de conformité, qui sert de base aux politiques de masquage et de reporting.
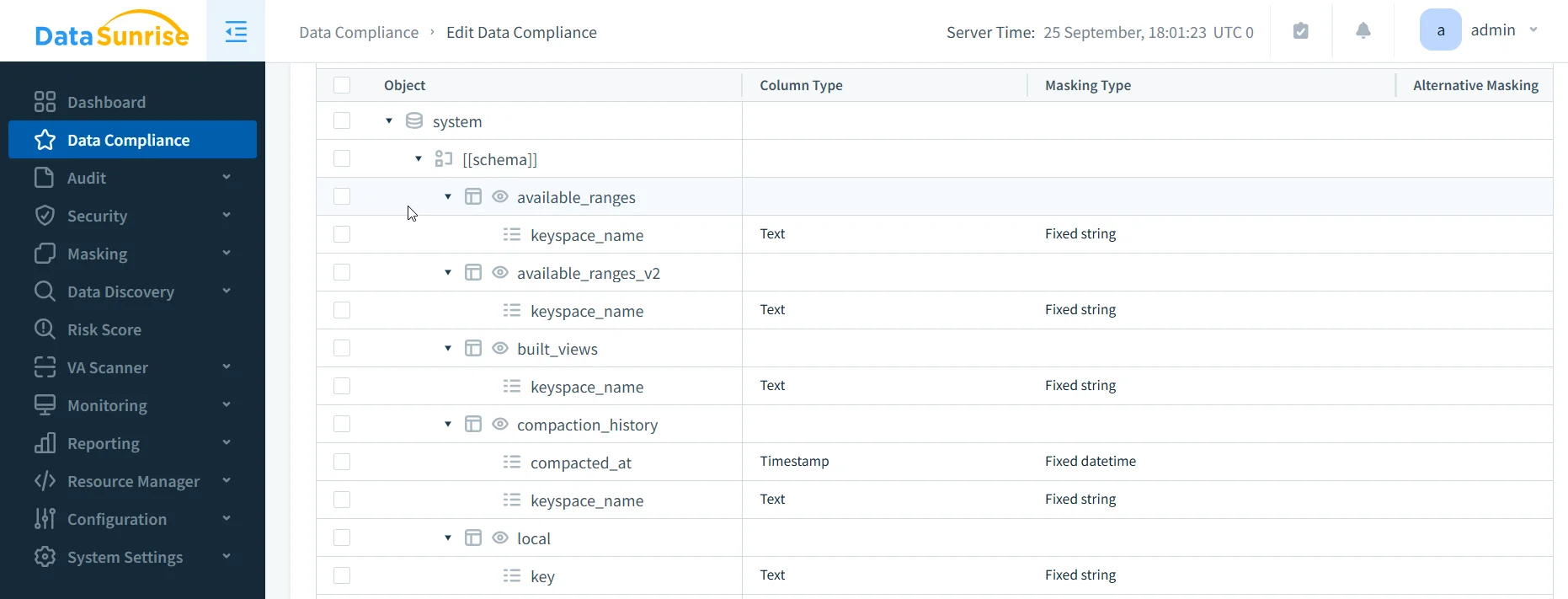
Étape 2 : Appliquer le masquage et activer la surveillance centralisée
- Dans le menu Masquage, appliquez un masquage dynamique pour une protection en temps réel ou un masquage statique pour des jeux de données sécurisés à des fins de test.
- Les règles de masquage s’adaptent selon le contexte et le rôle utilisateur (par ex., les médecins voient toutes les données, les infirmières une partie).
- Activez les pistes d’audit centralisées de sorte que toute activité — y compris les connexions échouées — soit consignée dans un répertoire unique.
- Utilisez la surveillance de l’activité de la base de données pour détecter les anomalies et déclencher des alertes en temps réel.
Étape 3 : Automatiser le reporting et l’application continue
- Accédez à Reporting → Génération de rapports.
- Choisissez des modèles pour GDPR, HIPAA, PCI DSS ou SOX. Les rapports peuvent être programmés ou générés à la demande.
- Les preuves de conformité sont prêtes pour l’auditeur aux formats PDF/HTML.
- En coulisses, le Policy Autopilot de DataSunrise ajuste automatiquement les règles à mesure que les schémas ou rôles évoluent, réduisant la dérive de conformité.
Principales différences en termes d’effort :
- Journalisation d’audit → Cassandra : logs locaux par nœud nécessitant des scripts personnalisés. DataSunrise : logs centralisés sur le cluster, consultables en temps réel.
- Capture des requêtes → Cassandra : FQL manuel avec couverture partielle. DataSunrise : pistes continues incluant les tentatives échouées, corrélées entre les nœuds.
- RBAC & contrôle d’accès → Cassandra : rôles créés manuellement, sans revues automatisées. DataSunrise : politiques centralisées, détection de dérive, droits temporels.
- Masquage des données → Cassandra : lié au schéma, uniquement dans la version 5.0+. DataSunrise : masquage contextuel en temps réel sans modification du schéma.
- Découverte des données → Cassandra : requêtes SQL manuelles. DataSunrise : classification automatisée par NLP/OCR à travers les keyspaces.
- Reporting de conformité → Cassandra : aucun, rapport assemblé manuellement. DataSunrise : rapports préconstruits, planifiés, prêts pour l’audit.
Dans l’ensemble, ce contraste montre pourquoi la conformité avec Cassandra seule signifie souvent « automatisation par scripts », tandis qu’avec DataSunrise elle devient une automatisation par conception. Pour les organisations qui gèrent de grands clusters, cette différence sépare la gestion constante des crises d’un programme de conformité qui fonctionne harmonieusement en arrière-plan.
Conclusion
Les outils natifs de Cassandra aident à faire respecter la conformité, mais ils offrent peu d’automatisation réelle — la plupart des tâches nécessitent des scripts manuels et une supervision constante.
DataSunrise transforme la conformité en un processus continu et automatisé : les données sensibles sont découvertes, masquées, surveillées et rapportées sans effort nœud par nœud.
Pour les organisations souhaitant automatiser la conformité des données dans Apache Cassandra, DataSunrise fournit une solution pratique et évolutive pour garantir la sécurité, la conformité et la préparation à l’audit des clusters.
Protégez vos données avec DataSunrise
Sécurisez vos données à chaque niveau avec DataSunrise. Détectez les menaces en temps réel grâce à la surveillance des activités, au masquage des données et au pare-feu de base de données. Appliquez la conformité des données, découvrez les données sensibles et protégez les charges de travail via plus de 50 intégrations supportées pour le cloud, sur site et les systèmes de données basés sur l'IA.
Commencez à protéger vos données critiques dès aujourd’hui
Demander une démo Télécharger maintenant