
Évaluer la posture de sécurité dans les contextes de l’IA et des LLM

L’IA générative (GenAI) et les grands modèles de langage (LLMs) ont ouvert de nouvelles voies pour les organisations afin d’automatiser, d’analyser et d’accélérer la prise de décision. Toutefois, leur conception inhérente – qui consiste à traiter des données dynamiques, souvent non structurées et sensibles – soulève de sérieux problèmes de sécurité. L’évaluation de la posture de sécurité dans les contextes de l’IA et des LLM nécessite de nouvelles stratégies adaptées à la manière dont ces modèles traitent et exposent les données.
Des modèles de sécurité traditionnels aux modèles adaptatifs
Dans les systèmes traditionnels, la sécurité des données était souvent fondée sur le périmètre. Avec la GenAI, la sécurité doit devenir contextuelle. Ces modèles ingèrent de vastes ensembles de données, retiennent des motifs, et peuvent régénérer des informations sensibles si leur configuration n’est pas adéquate. Une requête pourrait involontairement extraire des identifiants, des secrets commerciaux ou des informations personnelles identifiables (PII).
C’est pourquoi la sécurisation des pipelines IA ne se limite pas aux pare-feu et aux rôles. Elle requiert une sécurité des données adaptative, une journalisation respectueuse de la vie privée et des contrôles en temps réel intégrés dans le cycle de vie de l’IA. Comme le soulignent les pratiques sécurisées de l’IA de Google, les contrôles spécifiques à l’IA doivent s’aligner à la fois sur l’infrastructure et sur le comportement du modèle.
Audit en temps réel et suivi du comportement
Les charges de travail en IA nécessitent des mécanismes d’audit en temps réel pour capturer chaque interaction entre les utilisateurs et les modèles. Puisque les systèmes GenAI peuvent générer des sorties inédites à chaque requête, la journalisation doit couvrir l’entrée, la sortie, l’identité de la session et les requêtes en aval.
Considérez ce scénario : un analyste de données interagit avec un système GenAI interne via le langage naturel.
Invite : "Listez tous les clients d'Allemagne ayant réalisé des achats de plus de 10 000 $ au cours du dernier trimestre."
Le LLM génère la requête SQL :
SELECT customer_id, name, email, country, total_purchase
FROM sales.customers
WHERE country = 'Allemagne' AND total_purchase > 10000 AND purchase_date BETWEEN '2024-10-01' AND '2024-12-31';
Cette requête touche aux identifiants de clients, aux informations de contact et aux données financières. Une piste d’audit bien conçue capturera à la fois l’invite et la requête SQL générée, en les liant à la session de l’utilisateur et au contexte temporel. Des outils tels que la mise en apprentissage comportementale par audit aident à identifier si un tel accès est habituel ou potentiellement abusif. Cette approche est conforme au Cadre de gestion des risques de l’IA du NIST, qui met l’accent sur une surveillance continue.
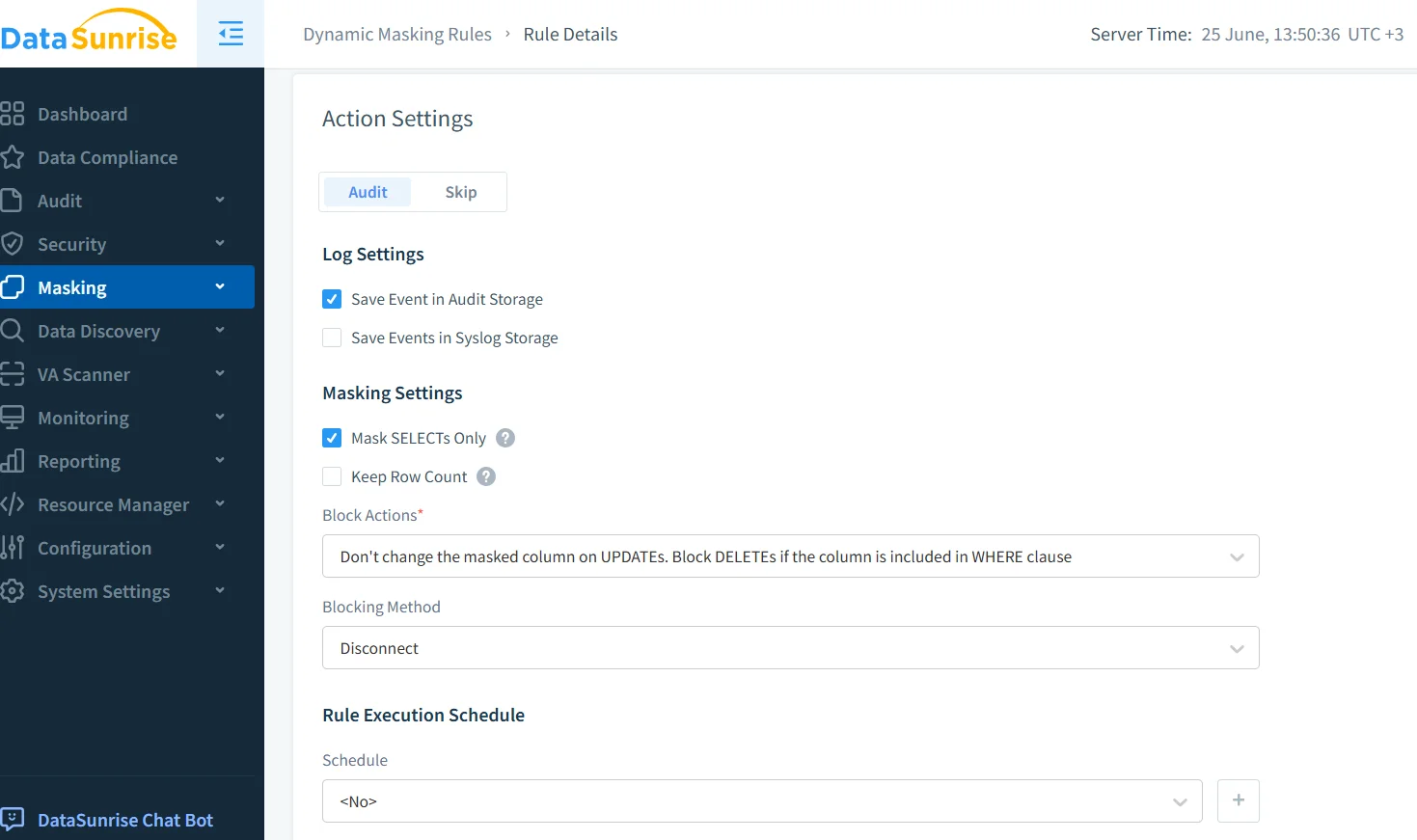
Masquage dynamique pour les réponses du modèle
Puisque les sorties de la GenAI sont générées de manière dynamique, le masquage dynamique des données garantit que les informations sensibles sont occultées avant affichage. Cette approche équilibre l’utilisabilité et la conformité.
Supposons qu’un bot de support soit connecté à une base de données de service client. Lorsqu’on lui demande :
"Montrez-moi le profil client pour John Doe."
Le backend peut produire :
{
"name": "John Doe",
"email": "[email protected]",
"ssn": "123-45-6789",
"credit_card": "4111 1111 1111 1111"
}
Avec le masquage activé pour les champs sensibles :
{
"name": "John Doe",
"email": "j*****[email protected]",
"ssn": "***-**-6789",
"credit_card": "**** **** **** 1111"
}
Le masquage est sensible au contexte et dépend du rôle de l’utilisateur, de la source et des règles de classification. Microsoft recommande également de protéger les sorties de données dans les systèmes IA au moyen de techniques d’application par couches.
Découverte des données avant l’exposition à l’IA
Avant d’alimenter les LLM en données, les organisations doivent utiliser des outils de découverte de données pour rechercher des informations personnelles identifiables (PII), des identifiants financiers et des valeurs sensibles sur le plan commercial. Cela permet aux équipes de sécurité de qualifier les actifs à haut risque et de les exclure des ensembles d’entraînement ou de l’accès en temps réel.
Plutôt que de se fier uniquement à une configuration manuelle, la découverte automatisée peut classifier les champs sensibles et s’intégrer aux règles de masquage, de chiffrement ou d’accès. Le guide de gouvernance des données d’IBM offre des pratiques précieuses pour mettre en place ces flux de travail de manière efficace. L’intégration avec des moteurs de politique automatisés garantit une application cohérente dans les environnements IA.
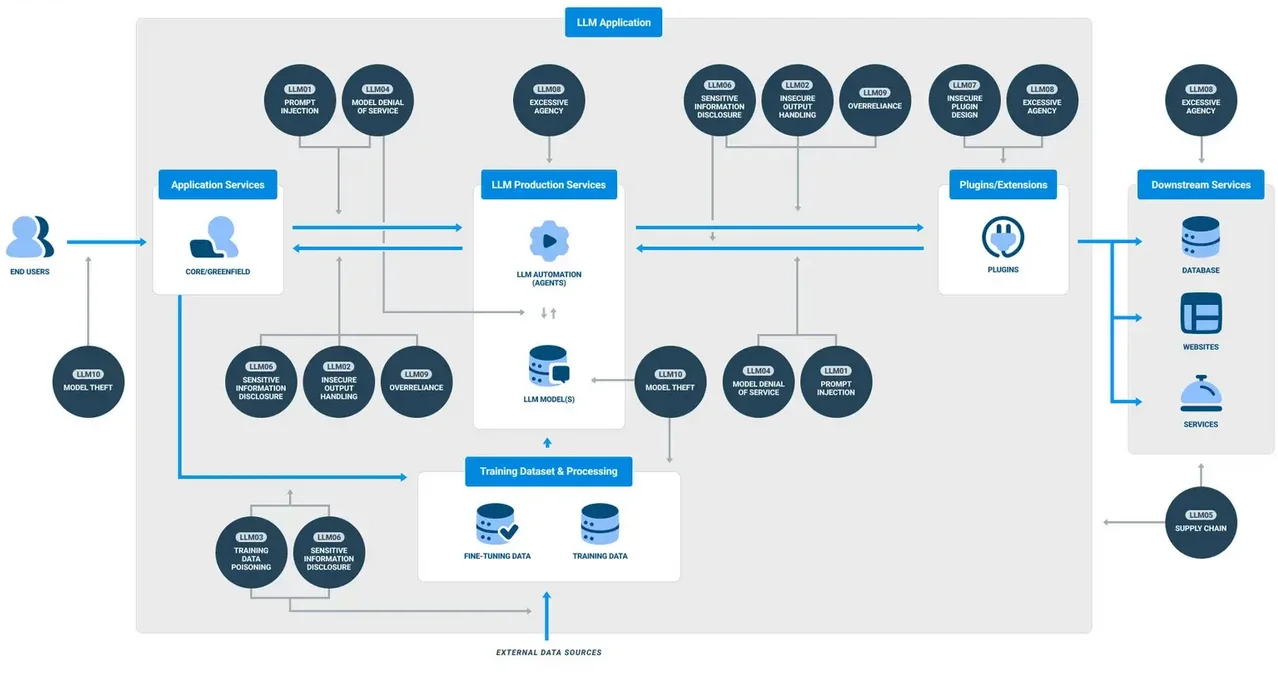
Politiques de sécurité adaptées à l’IA
Les règles statiques d’autorisation/refus sont insuffisantes dans le contexte de la GenAI. Les politiques doivent s’adapter en fonction du comportement de l’utilisateur, de l’intention de la requête et de la sensibilité de la sortie. Par exemple, l’analyse de motifs peut détecter des tentatives malveillantes d’injection de requêtes, tandis que des limites temporelles peuvent restreindre l’accès à certaines données en dehors des heures d’activité.
Des systèmes comme la protection contre les injections SQL doivent évoluer pour analyser non seulement le SQL, mais aussi les requêtes en langage naturel qui génèrent une activité sur la base de données. Des recherches menées par Stanford soulignent comment de subtiles variations dans les requêtes peuvent contourner les filtres traditionnels et extraire des données privilégiées.
Aligner la GenAI avec les normes de conformité des données
Les systèmes basés sur les LLM doivent toujours se conformer au RGPD, à la HIPAA et au PCI DSS. Cela inclut de garantir l’auditabilité, de respecter les droits des utilisateurs à la suppression de leurs données et d’empêcher l’exposition non autorisée de données à l’international.
La conformité dans les environnements GenAI signifie mettre en œuvre des politiques de rétention des données limitant le stockage de l’historique des requêtes, appliquer des restrictions d’accès par le biais d’un contrôle basé sur les rôles et appliquer un masquage aux journaux d’audit. Les gestionnaires de conformité simplifient la supervision en générant des rapports automatisés et en appliquant des politiques standardisées. Pour référence, les recommandations de la CNIL concernant l’IA et le RGPD fournissent des cadres utiles adaptés à l’utilisation de l’IA.
Conclusion : Un cadre de sécurité vivant
L’évaluation de la posture de sécurité dans les contextes de l’IA et des LLM n’est pas une simple liste de vérification ponctuelle. C’est un cycle continu de surveillance, de masquage, d’audit et d’alignement avec la conformité. Les outils doivent être interopérables, en temps réel et sensibles à l’IA. La sécurité doit aller au-delà de l’infrastructure et pénétrer dans les requêtes, les sorties du modèle ainsi que dans le comportement des utilisateurs.
Les organisations adoptant la GenAI doivent construire un cadre de sécurité vivant — un cadre qui s’adapte à mesure que le modèle évolue, apprend et interagit avec un environnement de plus en plus dynamique.
