
Génération de Données Synthétiques

La génération de données synthétiques devient rapidement un élément fondamental du développement moderne de l’IA, de l’analytique avancée et de la transformation numérique axée sur la confidentialité. Elle permet aux organisations de créer des ensembles de données réalistes et statistiquement précis qui reflètent les informations du monde réel—sans exposer les données réelles des clients ou de l’entreprise. Cette approche soutient l’expérimentation sécurisée, la formation des modèles d’apprentissage automatique et la validation tout en restant conforme aux réglementations en vigueur telles que le RGPD, HIPAA et CCPA. Selon un rapport récent de Gartner, près de la moitié des dirigeants mondiaux ont augmenté leurs dépenses en IA, soulignant le besoin croissant d’une utilisation responsable et sécurisée des données. Des orientations complémentaires du Cadre de gestion des risques liés à l’IA du NIST mettent en avant le rôle des données synthétiques dans la réduction des biais et le soutien au développement de modèles plus sûrs. Des fonctionnalités telles que le masquage dynamique des données renforcent encore la capacité des organisations à protéger les informations sensibles tout au long du processus.
DataSunrise considère les données synthétiques comme une évolution naturelle de la protection des données—complétant les méthodes existantes telles que le masquage, le chiffrement et la surveillance des activités des bases de données. Cette fonctionnalité permet aux organisations de générer des ensembles de données entièrement anonymisés et de qualité production qui conservent la structure, les relations et les motifs statistiques des données réelles. Ainsi, les équipes peuvent effectuer des tests, des analyses et du développement dans des environnements sûrs et contrôlés sans violer la confidentialité ni les exigences réglementaires. Les jeux de données synthétiques facilitent la collaboration sécurisée, accélèrent l’innovation et garantissent la conformité à chaque étape du cycle de vie de l’IA.
Associées à l’automatisation et à des contrôles politiques intelligents, les données synthétiques améliorent non seulement la protection des données et la conformité réglementaire, mais augmentent aussi la scalabilité, l’agilité opérationnelle et la continuité. Elles permettent aux entreprises d’adopter l’IA et l’analytique dans des écosystèmes sécurisés et gouvernés éthiquement—déverrouillant l’innovation tout en maintenant la confiance et l’alignement réglementaire.
Qu’est-ce que les Données Synthétiques ?
Les données synthétiques désignent des informations créées artificiellement qui reflètent la structure et le comportement statistique des ensembles de données réels sans conserver les valeurs exactes. Elles maintiennent les formats, les relations et les distributions, permettant aux équipes de développer, tester et analyser en toute sécurité. Étant donné qu’aucun enregistrement authentique n’est utilisé, les jeux de données synthétiques éliminent les risques liés à la confidentialité tout en étant très efficaces pour la modélisation IA, la validation système et les efforts de conformité.
Quand utiliser les Données Synthétiques plutôt que le Masquage
Le masquage statique ou dynamique est idéal lorsque vous devez conserver la structure et la logique des données de production—tout en gardant une référence aux valeurs réelles. Cependant, le masquage ne peut pas être partagé en externe si le schéma source ou les métadonnées créent un risque de ré-identification.
Les données synthétiques sont préférables lorsque :
- Vous devez simuler de grands ensembles de données sans aucun lien avec des individus réels
- La conformité exige une exposition nulle aux valeurs de production
- Vous travaillez avec des journaux non structurés ou entraînez des grands modèles linguistiques (LLM)
Scénario : Pourquoi le Synthétique l’emporte sur le Masquage
Imaginez une équipe de data science entraînant un modèle de détection d’anomalies. Les données masquées conservent la structure, mais des corrélations résiduelles peuvent encore risquer une ré-identification. Les jeux de données synthétiques, en revanche, ne sont reliés à aucun client réel. L’équipe obtient des données statistiquement fidèles pour les flux de l’IA, tandis que les responsables de conformité ont la garantie qu’aucune information identifiable ne quitte jamais la production.
Les données synthétiques ne sont pas qu’un outil de développement—c’est un accélérateur de conformité. En générant des enregistrements sûrs pour la confidentialité, les entreprises réduisent les risques réglementaires, accélèrent l’adoption de l’IA et permettent une collaboration sécurisée avec les fournisseurs.
Associée au masquage, la génération synthétique crée un modèle hybride : conserver l’intégrité référentielle pour les flux qui en ont besoin, et produire des enregistrements entièrement artificiels pour les tests, le partage ou la formation IA. Cette approche mixte assure la conformité sans freiner l’innovation.
Données Synthétiques — Résumé, Étapes, Validation
Résumé
- Objectif : créer des ensembles de données sûrs pour la confidentialité qui conservent le schéma et les propriétés statistiques sans exposer d’enregistrements réels.
- Utilisation : partage externe, formation LLM/ML, provisionnement non production, ou politiques exigeant une liaison nulle avec les individus.
- Couplage : combiner avec le masquage pour des flux hybrides nécessitant l’intégrité référentielle dans certains domaines.
Étapes de mise en œuvre
- Définir le périmètre et l’objectif (QA, analytique, formation LLM, partage fournisseur).
- Recenser le schéma, contraintes et champs sensibles (PII/PHI/PCI) afin de guider les générateurs.
- Choisir le mode de génération (intégré/politique-aware dans la plateforme, ou open source comme SDV/CTGAN/Mockaroo pour prototypes).
- Choisir les stratégies par colonne (substitution, modèles statistiques, FPE lorsque la forme importe).
- Préserver les relations (clés/étrangères) ou simuler avec règles déterministes quand nécessaire.
- Réaliser un pilote sur un sous-ensemble ; enregistrer les paramètres pour la reproductibilité.
- Valider la qualité (distribution, corrélations, distance de confidentialité) ; ajuster les générateurs.
- Planifier les tâches ; consigner les opérations et contrôler l’accès selon la politique de gouvernance.
Liste de contrôle de validation
| Vérification | À vérifier | Notes |
|---|---|---|
| Distribution | Moyenne/variance, percentiles dans la tolérance | Test KS pour chaque colonne numérique |
| Corrélations | Corrélations clés préservées (±Δ) | Comparer les matrices de corrélations |
| Confidentialité | Aucune ligne synthétique trop proche d’échantillons réels | Distance du plus proche voisin |
| Contraintes | Unicité, formats, domaines respectés | Vérifications regex/intervalle |
Vérifications rapides
- Documenter générateurs, graines et règles pour la reproductibilité.
- Garder les jeux de données synthétiques et réels isolés ; interdire toute jointure entre eux.
- Pour des tests UI/intégration nécessitant une stricte intégrité référentielle, envisager une approche hybride (base masquée + expansions synthétiques).
- Appliquer les mêmes contrôles d’accès et politiques de conservation aux jeux synthétiques utilisés en externe.
Cas d’Utilisation des Données Synthétiques DataSunrise
| Cas d’Utilisation | Description | Exemple |
|---|---|---|
| Tests de conformité | Simuler des ensembles de données réelles pour valider la logique sans utiliser les données client authentiques. | Exécuter des algorithmes de détection de fraude sur des transactions bancaires générées. |
| Formation IA & ML | Former des modèles sur des ensembles de données réalistes mais non identifiables afin d’éviter les infractions réglementaires. | Construire des modèles diagnostiques à partir de dossiers médicaux synthétiques. |
| Mise en scène & QA | Remplir des environnements de test avec des données réalistes pour des tests d’interface, de charge ou d’intégration. | Alimenter un cluster PostgreSQL de développement avec des profils utilisateurs synthétiques. |
| Collaboration sécurisée | Partager des ensembles de données synthétiques entre équipes ou avec des partenaires sans exposer d’informations sensibles. | Fournir des dossiers RH synthétiques à un fournisseur externe d’analytique. |
Qu’est-ce qui différencie les Données Synthétiques DataSunrise ?
Alors que de nombreuses plateformes proposent la génération de données artificielles, peu l’intègrent directement dans des pipelines de sécurité et de conformité de niveau entreprise. Les outils de données synthétiques DataSunrise sont étroitement liés aux fonctions de masquage, audit et application de politiques—les rendant idéaux pour un usage réel dans des environnements réglementés.
- Basculement transparent vers le masquage : Passez facilement du masquage à la génération selon le contexte d’accès ou le type de schéma.
- Génération conforme aux politiques : Définissez des règles de génération alignées avec les filtres de conformité et les balises des données sensibles existantes.
- Flux de travail planifiés : Automatisez la création des jeux synthétiques dans plusieurs environnements, applications et pipelines CI/CD.
- Journalisation des audits : Suivez chaque tâche de génération pour une traçabilité complète et une bonne préparation aux audits.
Que vous testiez des applications internes ou formiez des modèles IA, DataSunrise Synthetic Data offre aux équipes la flexibilité de simuler des charges de production—sans risquer les données réelles.
Comment Configurer la Génération de Données Synthétiques dans DataSunrise
Étape 1 : Définir les Paramètres Généraux
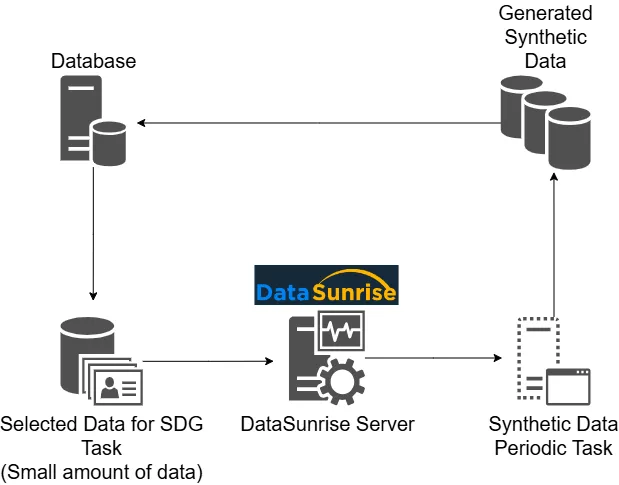
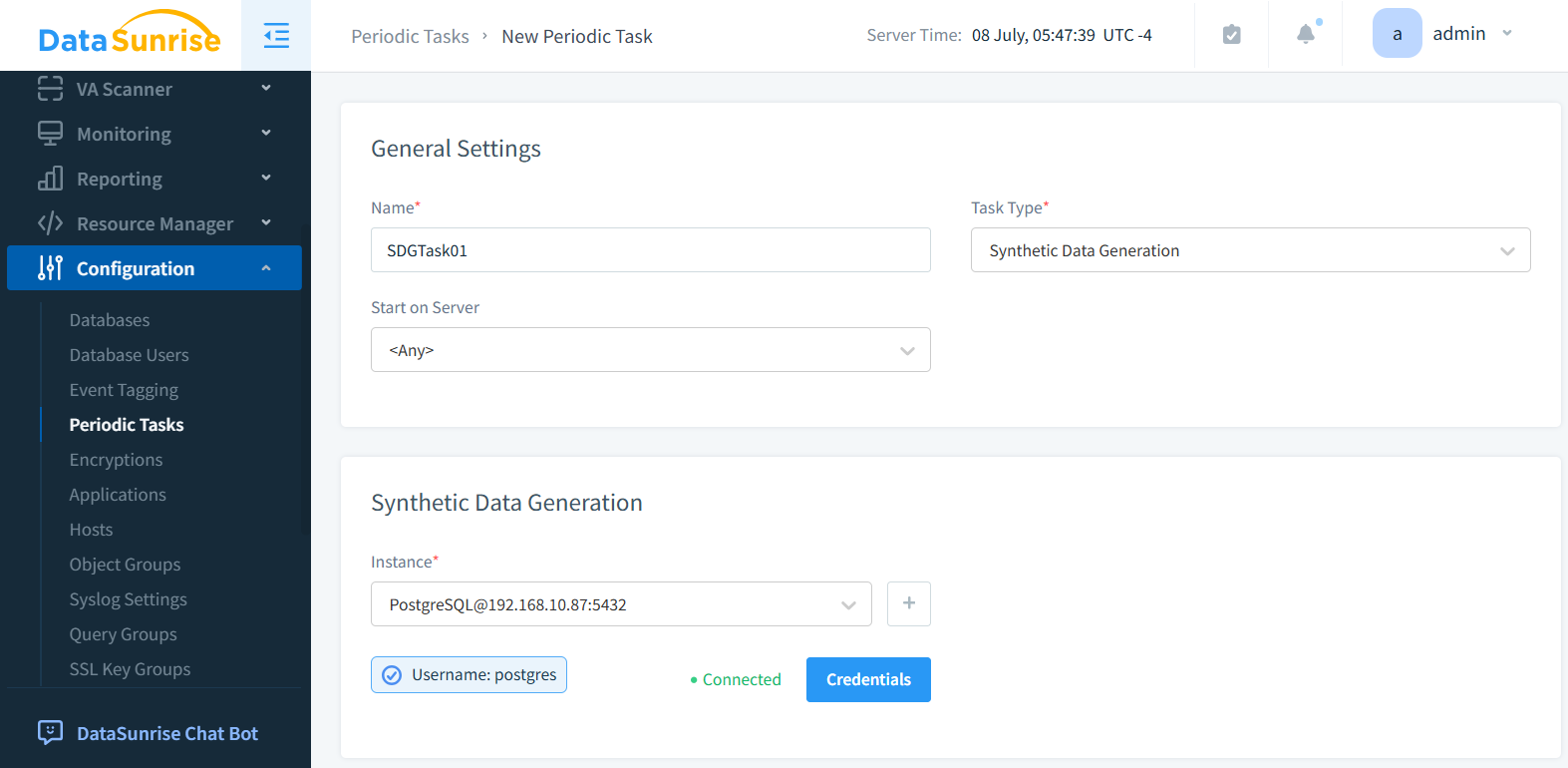
Accédez à Configuration → Tâches Périodiques et créez une nouvelle tâche. Sélectionnez « Génération de Données Synthétiques » comme type, et nommez la tâche en conséquence.
Étape 2 : Sélectionner l’Instance de Base de Données
Choisissez votre instance cible. Ci-dessous, PostgreSQL est sélectionné comme moteur de base de données.
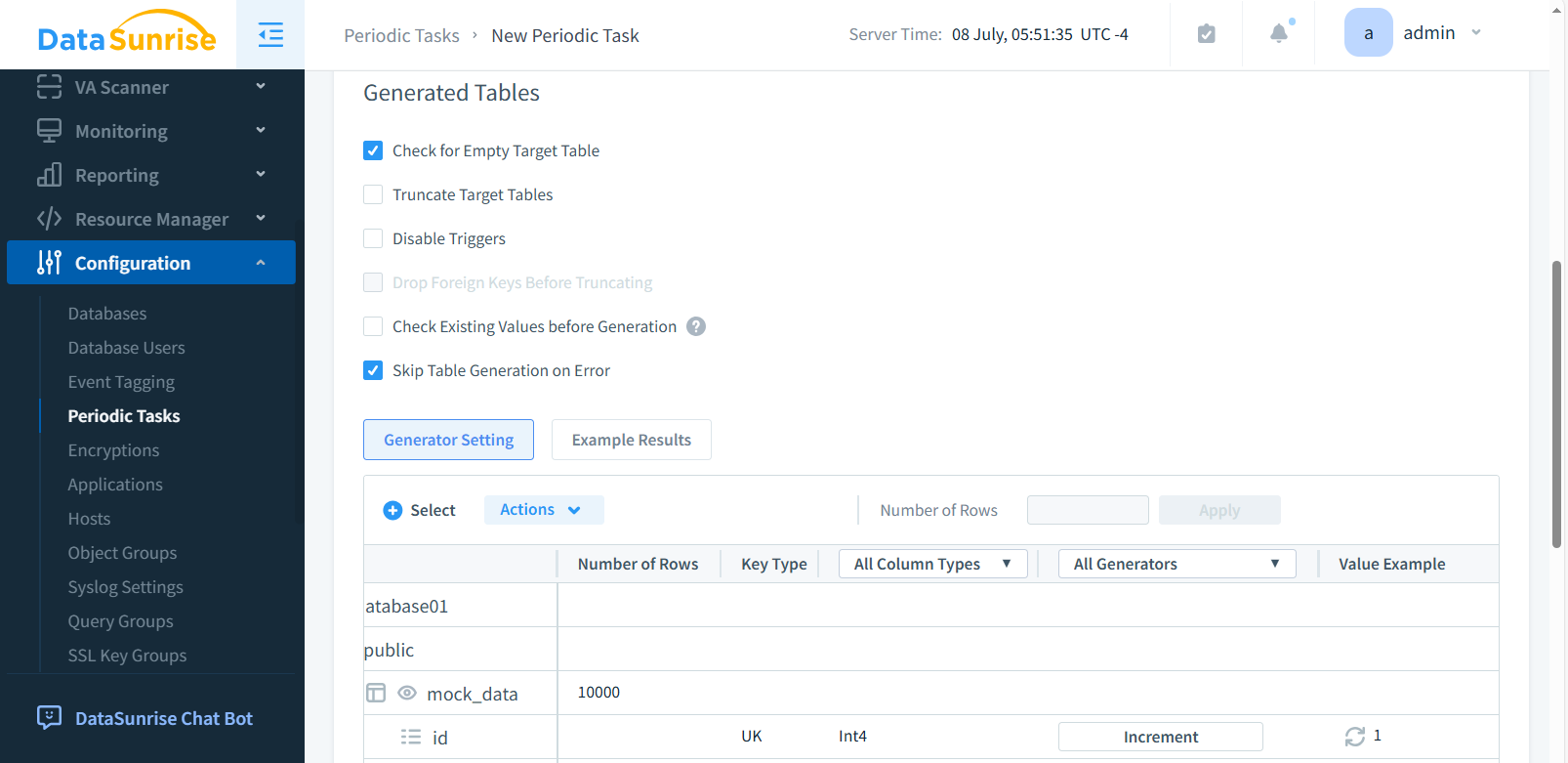
Étape 3 : Définir les Tables et Colonnes Cibles
Sélectionnez le schéma et les tables dans lesquelles les données synthétiques seront injectées. Choisissez des colonnes spécifiques, activez « Table vide » si nécessaire, et configurez le comportement en cas d’erreur.
Étape 4 : Utiliser des Générateurs Intégrés ou Personnalisés
Choisissez parmi les générateurs de valeurs intégrés (noms, emails, nombres, dates) ou définissez une logique personnalisée via Configuration → Générateurs. Ceci est utile pour correspondre à des motifs spécifiques au domaine, comme simuler des identifiants patients ou des codes fiscaux.
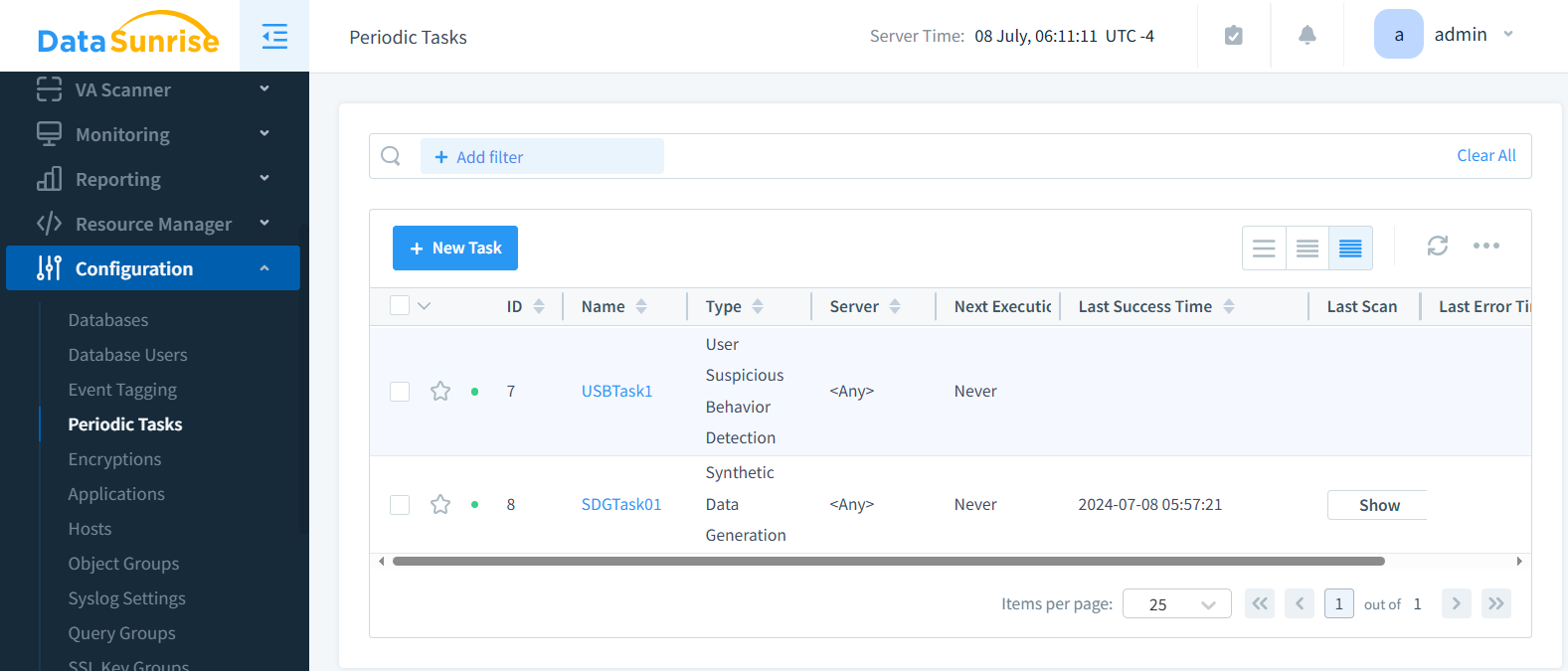
Étape 5 : Enregistrer, Planifier et Exécuter
Une fois sauvegardée, la tâche apparaît dans votre liste de travaux. Vous pouvez l’exécuter à la demande ou programmer des exécutions périodiques pour un rafraîchissement continu des données.
Outils et Bibliothèques Gratuits pour les Données Synthétiques
DataSunrise offre un soutien complet pour la génération synthétique avec masquage, audit et contrôles de conformité. Mais les développeurs et data scientists bénéficient aussi d’alternatives gratuites pour apprendre ou prototyper.
SDV (Synthetic Data Vault)
SDV est un framework Python open source qui utilise des modèles statistiques et des GAN pour générer des ensembles de données tabulaires synthétiques. Il supporte les structures relationnelles et multi-tables.
pip install sdv
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
real_data, metadata = download_demo(modality='single_table', dataset_name='fake_hotel_guests')
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
synthetic_data = synthesizer.sample(num_rows=500)
print(synthetic_data.head())
CTGAN
Modèle basé sur GAN adapté aux données tabulaires, CTGAN fonctionne bien avec des ensembles déséquilibrés et des colonnes aux types mixtes. Voir notre article précédent sur la génération de données IA pour un code exemple.
Mockaroo
Mockaroo est un outil web pour générer des ensembles de données simulées en CSV, JSON, SQL et autres formats. Idéal pour des prototypes rapides, il supporte les schémas de champs personnalisés. L’utilisation gratuite est limitée à 1 000 lignes par session.
Validation de la Qualité des Données Synthétiques
La génération des enregistrements synthétiques n’est que la moitié de la tâche. Il faut s’assurer que les données se comportent comme le jeu réel sans exposer de valeurs sensibles. Les contrôles courants comprennent :
- Similarité de distribution : Comparer les distributions colonne par colonne entre réel et synthétique.
- Préservation des corrélations : Vérifier que les relations entre champs restent intactes.
- Distance de confidentialité : Confirmer qu’aucune ligne synthétique n’est trop proche d’un enregistrement réel.
Exemple Python : Test de Kolmogorov–Smirnov
from scipy.stats import ks_2samp
# Comparer les distributions réelles et synthétiques d’une colonne
ks_stat, p_value = ks_2samp(real_data["age"], synthetic_data["age"])
if p_value > 0.05:
print("La distribution synthétique de 'âge' correspond aux données réelles")
else:
print("Différence significative détectée")
Contrôle de la matrice de corrélation
import pandas as pd
real_corr = real_data.corr(numeric_only=True)
synth_corr = synthetic_data.corr(numeric_only=True)
diff = (real_corr - synth_corr).abs()
print(diff.head())
Ces étapes de validation garantissent que vos données synthétiques sont utiles pour l’analytique et les pipelines ML, tout en restant sécurisées pour la conformité.
Bonnes Pratiques pour les Données Générées
- Respecter les formats attendus en aval.
Assurez-vous que les valeurs synthétiques suivent les mêmes modèles—types de données, plages, formats et contraintes—afin que les applications, pipelines et outils analytiques fonctionnent sans modification. - Préserver les relations de table si nécessaire.
Maintenez les dépendances clés telles que clés primaires/étrangères, hiérarchies et tables de référence pour que les flux, jointures et logiques métiers restent corrects. - Documenter les règles de génération pour la reproductibilité.
Suivez la logique, les valeurs de graine et les règles de transformation utilisées pour créer le jeu, afin d’assurer une régénération cohérente, l’audit et la résolution de problèmes. - Effectuer des contrôles de cohérence pour valider la logique.
Vérifiez que distributions, plages et comportements semblent réalistes—détectant tôt les anomalies telles que valeurs hors intervalle, champs vides ou relations brisées. - Utiliser le masquage ou exclusions pour éviter tout chevauchement avec les données réelles.
Assurez-vous que les valeurs synthétiques ne puissent pas être retracées jusqu’aux informations réelles des clients, réduisant le risque de ré-identification et renforçant la conformité.
Comparaison rapide
| Outil | Usage conseillé | Limites |
|---|---|---|
| SDV | Simulation statistique de données tabulaires | Python uniquement, nécessite ajustements |
| CTGAN | Jeux de données complexes et déséquilibrés | Entraînement plus lent, GPU recommandé |
| Mockaroo | Prototypes rapides CSV/JSON/SQL | Limitation du nombre de lignes, pas sensible au schéma |
Données Synthétiques dans les Cadres de Conformité
La génération de données synthétiques s’aligne naturellement avec les réglementations modernes en supprimant les identifiants directs tout en conservant la valeur analytique. Voici comment elle s’articule avec des cadres courants :
| Cadre | Exigence | Contribution des données synthétiques |
|---|---|---|
| RGPD | Art. 32 — pseudonymisation et minimisation des données personnelles | Génère des enregistrements artificiels sans lien avec des individus réels, répondant aux standards de pseudonymisation et minimisation. |
| HIPAA | §164.514 — dé-identification des identifiants PHI | Produit des dossiers santé non identifiables pour la recherche et les tests tout en protégeant les PHI. |
| PCI DSS | Req. 3.4 — éviter le stockage du PAN dans les environnements de test | Les données de paiement synthétiques permettent la QA et le partage avec fournisseurs sans exposer les données réelles des titulaires de carte. |
| SOX | §404 — garantir l’intégrité des données financières pour l’audit | Fournit des données de test sûres pour valider les systèmes financiers sans risquer les fichiers de production. |
En alignant la génération synthétique sur ces cadres, DataSunrise aide les organisations à accélérer l’adoption de l’IA et de l’analytique tout en restant prêtes pour l’audit et conformes.
Quand les Données Synthétiques Ne Suffisent Pas : Considérations et Contrôles
Bien que les données synthétiques offrent de fortes garanties de confidentialité et de flexibilité, elles ne remplacent pas universellement les données réelles ni les workflows de masquage en entreprise. Certains scénarios—tels que les tests d’intégrité référentielle, les jointures déterministes ou l’analyse longitudinale—requièrent encore un accès contrôlé à des ensembles masqués ou pseudonymisés.
Pour assurer que les données générées servent efficacement vos objectifs, considérez ces garde-fous :
- Alignement sur le cas d’usage : Pour la validation de modèle, utilisez des données pleinement synthétiques. Pour les tests d’intégration ou d’interface utilisateur, des clones masqués de production peuvent être plus précis.
- Documentation de la gouvernance : Suivez les champs générés synthétiquement, ceux préservés, ainsi que les outils ou logiques employés.
- Échantillonnage vs simulation : Ne confondez pas l’échantillonnage aléatoire de données réelles avec la génération synthétique, qui seule casse le lien avec les sujets identifiables.
- Préparation à l’audit : Maintenez des journaux des tâches de génération, calendrier de rétention et contrôles d’accès—surtout si les données synthétiques entrent dans des pipelines de test partagés avec des fournisseurs ou contractants.
DataSunrise aide à naviguer ces décisions grâce à l’automatisation, des options de basculement vers le masquage et une visibilité complète sur les types et environnements de données. Le résultat : des flux de données plus sûrs, intelligents et rapides—sans compromis sur la conformité.
Points Clés pour Utiliser les Données Synthétiques Efficacement
- Choisissez les données synthétiques lorsque la conformité exige une exposition nulle aux enregistrements réels, ou lors du partage externe des jeux de données.
- Combinez la génération synthétique avec le masquage pour des scénarios hybrides—préservant l’intégrité relationnelle où besoin tout en remplaçant totalement les champs à haut risque.
- Documentez les règles de génération, politiques de conservation et contrôles d’accès pour soutenir la gouvernance et la préparation à l’audit.
- Testez les jeux synthétiques dans les flux réels pour confirmer qu’ils répondent aux exigences de performance, précision et compatibilité.
- Automatisez les tâches de génération via la planification et l’intégration aux pipelines CI/CD pour des résultats cohérents et reproductibles.
FAQ sur les Données Synthétiques
Qu’est-ce que les données synthétiques ?
Les données synthétiques sont des informations générées artificiellement qui reflètent la structure et les propriétés statistiques des ensembles de données réels, mais ne contiennent aucun enregistrement client réel. Elles permettent des tests, analyses et formations IA sécurisés sans risques pour la confidentialité.
En quoi les données synthétiques diffèrent-elles du masquage ?
Le masquage altère les valeurs réelles pour masquer les identifiants, tout en conservant le schéma et l’intégrité référentielle. Les données synthétiques, en revanche, créent des enregistrements entièrement artificiels sans lien avec des individus réels, ce qui est plus sûr pour le partage externe et les pipelines IA.
Quand les organisations doivent-elles utiliser les données synthétiques ?
Les données synthétiques sont idéales lorsque la conformité exige une exposition nulle aux données réelles—comme dans la collaboration avec des fournisseurs externes, l’entraînement de grands modèles linguistiques, ou le peuplement d’environnements non production à grande échelle.
Quels cadres de conformité soutiennent les données synthétiques ?
Des cadres tels que le RGPD, la HIPAA et le PCI DSS reconnaissent les techniques de pseudonymisation et dé-identification. La génération synthétique offre une voie efficace vers la conformité lorsqu’elle est combinée à des politiques de gouvernance.
Quelles sont les limites des données synthétiques ?
Elles ne reproduisent pas toujours parfaitement les jointures complexes, les historiques longitudinaux ou les motifs rares. Pour ces scénarios, les organisations combinent souvent masquage et génération synthétique dans des workflows hybrides.
Comment DataSunrise prend-il en charge les données synthétiques ?
DataSunrise intègre la génération de données synthétiques avec le masquage, l’audit et les rapports de conformité. Il fournit des générateurs informés par les politiques, des workflows planifiés et des pistes d’audit complètes.
Applications Industrielles des Données Synthétiques
Les données synthétiques soutiennent plus que les tests—they permettent directement la conformité et l’innovation dans divers secteurs :
- Finance : Générer des journaux de transactions artificiels pour entraîner des modèles de fraude, répondant aux exigences d’audit PCI DSS et SOX sans exposer les numéros PAN.
- Santé : Créer des ensembles de données patients dé-identifiés conformes à la HIPAA, permettant la recherche et le développement d’IA diagnostique sûrs.
- SaaS & Cloud : Fournir des jeux conformes RGPD pour les environnements de mise en scène, validant l’isolation multi-tenant.
- Administrations : Partager des données populationnelles avec des contractants tout en appliquant le RGPD et autres lois locales sur la confidentialité.
- Retail & eCommerce : Alimenter des pipelines analytiques avec des parcours clients synthétiques pour tester les moteurs de personnalisation sans risque de confidentialité.
En contextualisant les données synthétiques pour chaque industrie, les organisations accélèrent l’innovation tout en restant prêtes pour l’audit et sûres du point de vue de la confidentialité.
L’Avenir de la Génération de Données Synthétiques
Les données synthétiques évoluent rapidement d’un simple outil de test vers un élément central de la stratégie data d’entreprise. Alors que les organisations cherchent à innover de manière responsable, les plateformes de données synthétiques de nouvelle génération combineront génération pilotée par IA, validation de qualité des données et contrôles automatisés de conformité pour créer à grande échelle des jeux de données réalistes mais pleinement anonymisés. Ces systèmes reproduiront non seulement la précision statistique et l’intégrité structurelle, mais s’adapteront aussi dynamiquement aux modèles de données changeants, aux exigences de confidentialité et aux évolutions réglementaires.
Les futures solutions offriront une intégration fluide avec des technologies complémentaires telles que le masquage des données, la surveillance des activités en base de données, et la découverte des données sensibles. Cette interopérabilité permettra aux organisations de passer sans friction entre données réelles, masquées et synthétiques selon le contexte—permettant des analyses sécurisées, la formation des modèles et la collaboration externe sans exposer d’informations réglementées. Au fil du temps, cet écosystème de données adaptatif fera de l’innovation préservant la confidentialité la norme, non l’exception. Des capacités telles que l’automatisation de la conformité garantiront en outre que les ensembles synthétiques restent constamment alignés sur les exigences réglementaires et organisationnelles.
Pour les secteurs très régulés comme la finance, la santé et l’administration publique, les données synthétiques redéfiniront l’équilibre entre conformité et innovation. Les entreprises pourront accélérer l’adoption de l’IA, collaborer en toute sécurité avec des tiers, et conserver des preuves vérifiables qu’aucune donnée client authentique n’a quitté les environnements contrôlés. En définitive, l’avenir de la génération de données synthétiques réside dans l’automatisation intelligente et la conformité continue, faisant de la confidentialité un moteur de progrès plutôt qu’une contrainte.
Conclusion
Les données synthétiques sont devenues un composant clé des stratégies modernes de gestion des données axées sur la confidentialité, offrant une alternative sécurisée et conforme à l’utilisation des jeux de données de production réels pour le développement, les tests, l’analytique et l’apprentissage automatique. En reflétant la structure, les caractéristiques statistiques et les relations des données du monde réel—sans conserver aucune information personnellement identifiable ou propriétaire—elles permettent aux organisations d’innover, collaborer et analyser en toute sécurité. Cette approche « privacy-by-design » minimise les risques de conformité, réduit les responsabilités juridiques et soutient le déploiement éthique de l’IA dans des secteurs tels que la finance, la santé, les télécommunications et le secteur public.
DataSunrise intègre la génération de données synthétiques dans sa plateforme complète de sécurité et de gouvernance des données. Grâce à l’automatisation de l’application des politiques, à une logique avancée de masquage et à des pistes d’audit détaillées, la plateforme garantit que les ensembles synthétiques respectent à la fois les cadres internes de gouvernance et les normes externes telles que le RGPD, HIPAA, SOX et PCI DSS. Cela permet aux entreprises de produire des données réalistes mais totalement anonymisées adaptées à la formation IA, aux tests logiciels et à la collaboration avec des tiers—sans risquer d’exposer des contenus sensibles ou confidentiels.
Intégrées à des solutions telles que la Surveillance des activités des bases de données (DAM), la découverte des données et le masquage dynamique, les données synthétiques deviennent un puissant levier de transformation numérique sécurisée. Elles permettent aux organisations d’accélérer l’innovation tout en maintenant transparence et conformité, soutenant l’expérimentation responsable et l’amélioration continue. À mesure que la réglementation sur la confidentialité évolue et que les technologies IA progressent, les données synthétiques resteront un pilier fondamental de l’innovation fondée sur les données, éthique et évolutive.
Suivant
