
Exploiter le schéma d’information de Redshift pour une meilleure performance de la base de données

Introduction
Cet article se penche sur le schéma de la base de données Redshift, en se concentrant spécifiquement sur son implémentation du schéma d’information. Nous explorerons comment il se compare à des outils similaires dans d’autres systèmes de bases de données, tels que Microsoft SQL Server et PostgreSQL. À la fin de ce guide, vous aurez une compréhension solide de la manière d’exploiter les tables système de Redshift pour optimiser vos stratégies de gestion des données.
Qu’est-ce qu’un schéma d’information dans MS SQL Server ?
Avant de plonger dans les spécificités de Redshift, commençons par un point de référence familier : le schéma d’information de Microsoft SQL Server.
Comprendre les bases
Dans MS SQL Server, le Schéma d’Information est un ensemble de vues qui fournissent des métadonnées sur les objets d’une base de données. C’est une méthode standardisée pour accéder aux informations concernant les tables, les colonnes, les vues et autres objets de la base de données.
Par exemple, pour afficher toutes les tables d’une base de données en utilisant le schéma d’information de MS SQL Server, vous pourriez utiliser une requête comme celle-ci :
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE';
Cette requête renverrait une liste de toutes les tables de base dans la base de données en cours.
Schéma de base de données Redshift : Outils d’information
Maintenant, portons notre attention sur Redshift, un entrepôt de données à l’échelle pétaoctet proposé par Amazon Web Services. Bien que Redshift soit basé sur PostgreSQL, il dispose de ses propres ensembles de tables système et de vues qui remplissent une fonction similaire au schéma d’information dans d’autres systèmes de bases de données.
Tables système dans Redshift
Redshift fournit un ensemble de tables système qui stockent des métadonnées sur les données dans le cloud, ses tables et autres objets. Ces tables système sont préfixées par “PG_” ainsi que “STL_”, “STV_” ou “SVV_”.
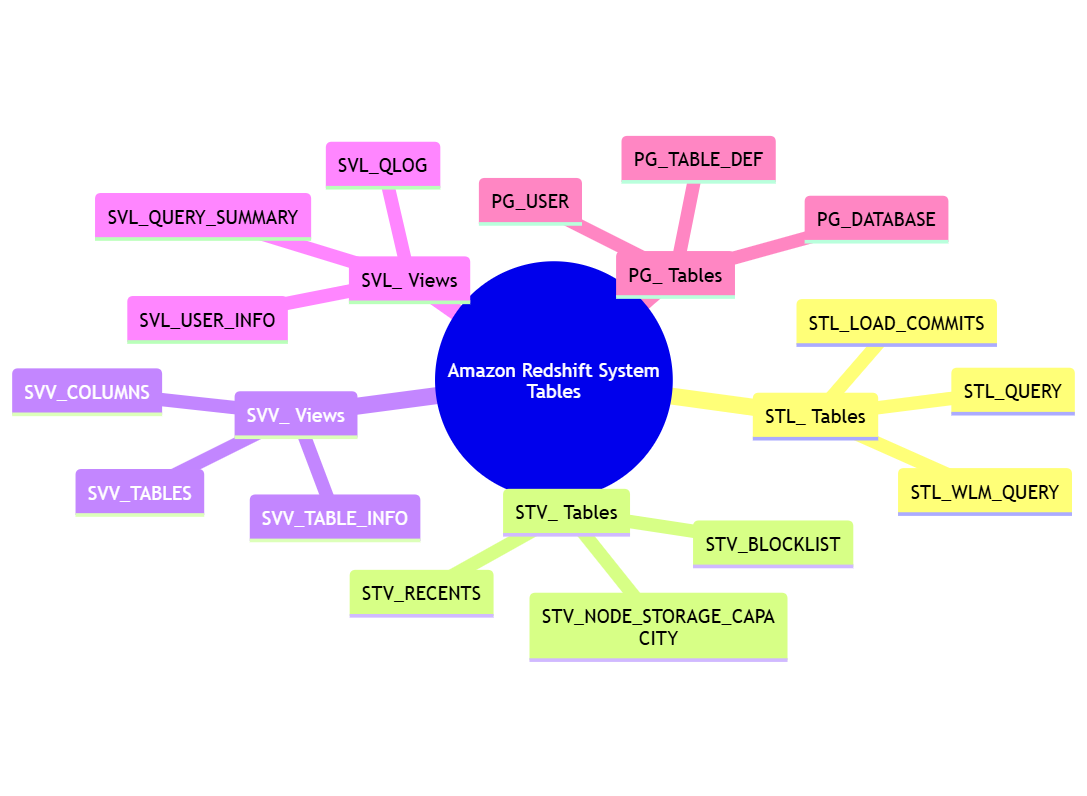
Voici quelques tables système clés dans Redshift :
- PG_TABLE_DEF : Contient des informations sur la définition des tables.
- SVV_COLUMNS : Fournit une vue de toutes les colonnes de la base de données.
- SVV_TABLES : Offre une vue de toutes les tables de la base de données.
Examinons un exemple d’utilisation de ces tables :
SELECT tablename, "column", type, encoding FROM pg_table_def WHERE schemaname = 'public';
Cette requête retournera des informations sur toutes les colonnes des tables du schéma ‘public’, incluant leurs noms, types de données et encodage.
Requêtes sur le schéma de base de données Redshift
Pour obtenir une vue complète du schéma de votre base de données Redshift, vous pouvez utiliser des requêtes qui combinent les informations de plusieurs tables système. Voici un exemple :
SELECT
n.nspname AS schema_name,
c.relname AS table_name,
a.attname AS column_name,
t.typname AS data_type
FROM
pg_catalog.pg_class c
JOIN
pg_catalog.pg_namespace n ON n.oid = c.relnamespace
JOIN
pg_catalog.pg_attribute a ON a.attrelid = c.oid
JOIN
pg_catalog.pg_type t ON t.oid = a.atttypid
WHERE
c.relkind = 'r' -- Seules les tables régulières
AND n.nspname NOT IN ('pg_catalog', 'information_schema')
AND a.attnum > 0 -- Exclure les colonnes système
ORDER BY
schema_name, table_name, a.attnum;
Cette requête fournit une vue détaillée du schéma de votre base de données Redshift, incluant les noms de schéma, les noms de tables, les noms de colonnes et les types de données.
Comparaison entre Redshift et les outils d’information de PostgreSQL
Étant donné que Redshift est basé sur PostgreSQL, il est naturel de se demander quelles sont les similarités et les différences entre leurs outils de schéma d’information.
Schéma d’information de PostgreSQL
PostgreSQL, tout comme MS SQL Server, dispose d’un INFORMATION_SCHEMA conforme à la norme SQL. Il fournit des vues qui offrent des informations sur tous les objets de la base de données.
Par exemple, pour lister toutes les tables dans PostgreSQL, vous pourriez utiliser :
SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';
Redshift vs PostgreSQL
Bien que Redshift soit basé sur PostgreSQL, il n’inclut pas l’INFORMATION_SCHEMA standard. À la place, il offre ses propres tables et vues système. Cela s’explique par la nature spécialisée de Redshift en tant qu’entrepôt de données orienté colonnes, nécessitant des outils d’optimisation et de gestion différents.
Cependant, de nombreux concepts sont similaires. Par exemple, là où PostgreSQL possède information_schema.tables, Redshift dispose de SVV_TABLES. Les deux fournissent des métadonnées sur les tables de la base de données, mais les spécificités des informations disponibles et la manière d’y accéder peuvent différer.
Exploiter les tables système de Redshift pour l’optimisation des performances
Comprendre les tables système de Redshift peut vous aider à optimiser les performances de votre base de données. Examinons quelques applications pratiques.
Identifier la répartition inégale des données
La répartition inégale des données se produit lorsque les données sont distribuées de manière inégale sur les slices dans Redshift. Cela peut entraîner des problèmes de performance. Vous pouvez utiliser les tables système pour identifier cette répartition :
SELECT
trim(name) AS table,
slice,
count(*) AS num_values,
cast(100 * ratio_to_report(count(*)) over () AS decimal(5,2)) AS pct_of_total
FROM svv_diskusage
WHERE name IN ('your_table_name')
GROUP BY name, slice
ORDER BY name, slice;
Cette requête montre la distribution des données sur les slices pour une table spécifique, vous aidant ainsi à identifier des problèmes potentiels de répartition inégale.
Surveiller les performances des requêtes
Les tables STL_QUERY et SVL_QUERY_SUMMARY de Redshift peuvent vous aider à surveiller les performances des requêtes :
SELECT q.query, q.starttime, q.endtime, q.elapsed/1000000 AS elapsed_seconds, s.segment, s.step, s.maxtime/1000000 AS step_seconds, s.rows, s.bytes FROM stl_query q JOIN svl_query_summary s ON q.query = s.query WHERE q.starttime >= DATEADD(hour, -1, GETDATE()) ORDER BY q.query, s.segment, s.step;
Cette requête fournit des informations détaillées sur les requêtes exécutées durant la dernière heure, y compris leur temps d’exécution et leur utilisation des ressources.
Bonnes pratiques pour utiliser le schéma d’information de Redshift
Pour tirer le meilleur parti des tables et vues système de Redshift, considérez les bonnes pratiques suivantes :
- Surveillez régulièrement les statistiques des tables en utilisant SVV_TABLE_INFO pour vous assurer que vos tables sont optimisées.
- Utilisez STL_ALERT_EVENT_LOG pour identifier et résoudre de manière proactive les problèmes de performance.
- Exploitez SVV_VACUUM_PROGRESS pour surveiller et gérer les opérations VACUUM.
- Utilisez SVV_DATASHARE_OBJECTS pour gérer le partage de données entre les clusters Redshift.
Rappelez-vous, bien que ces tables système offrent des informations précieuses, les interroger fréquemment peut impacter les performances. Utilisez-les judicieusement et envisagez de mettre en cache les résultats lorsque cela est approprié.
Conclusion
Comprendre et utiliser efficacement les outils du schéma d’information de Redshift est crucial pour la gestion et l’optimisation de votre entrepôt de données. Bien qu’il diffère de l’INFORMATION_SCHEMA standard présent dans SQL Server et PostgreSQL, les tables et vues système de Redshift offrent des capacités puissantes pour surveiller, diagnostiquer et optimiser votre base de données.
En exploitant ces outils, vous pourrez obtenir des informations approfondies sur le schéma de votre base de données Redshift, surveiller les performances et prendre des décisions éclairées concernant la gestion des données et l’optimisation des requêtes. Comme pour tout outil puissant, utilisez ces capacités de façon judicieuse afin de trouver le juste équilibre entre la collecte d’informations et la performance globale du système.
Pour ceux qui recherchent des outils avancés de sécurité et de conformité de bases de données, envisagez d’explorer DataSunrise. Nos solutions conviviales et flexibles offrent une protection complète de votre base de données. Visitez notre site web pour une démo en ligne et découvrez comment vous pouvez améliorer la sécurité de votre base de données dès aujourd’hui.
