Comment masquer les données sensibles dans Vertica
Comment masquer les données sensibles dans Vertica est une question cruciale pour les organisations qui s’appuient sur Vertica en tant que plateforme analytique haute performance tout en traitant des informations réglementées ou confidentielles. Vertica est largement utilisé pour le reporting BI, l’analyse client, les pipelines de machine learning et le traitement de données à grande échelle. En conséquence, ces cas d’usage nécessitent souvent un accès étendu aux données, ce qui augmente le risque que des informations personnellement identifiables (IPI), des données de paiement ou des coordonnées puissent être exposées via des requêtes, des exportations ou des systèmes en aval.
Dans des environnements axés sur l’analytique, les techniques traditionnelles de protection des données deviennent rapidement insuffisantes. Par exemple, les permissions statiques, les tables copiées ou les vues créées manuellement peinent à suivre l’évolution des schémas, des projections changeantes et du nombre croissant d’utilisateurs. Par conséquent, les organisations ont besoin d’une approche de masquage qui fonctionne de manière dynamique et cohérente sur tous les workloads Vertica, sans ralentir les requêtes ni forcer des modifications au niveau des applications.
Comment masquer les données sensibles dans Vertica efficacement nécessite donc d’appliquer la protection au moment de la requête. Plutôt que de modifier les données stockées, le masquage dynamique intercepte les résultats des requêtes et remplace les champs sensibles par des valeurs anonymisées ou partiellement masquées selon la politique en vigueur. Cette approche préserve ainsi l’utilité analytique tout en empêchant toute divulgation non autorisée.
Pourquoi le masquage des données sensibles dans Vertica est un défi
L’architecture de Vertica privilégie la rapidité et la scalabilité. Elle stocke les données dans des conteneurs ROS en colonnes, conserve les changements récents dans le WOS, et utilise des projections pour créer plusieurs représentations physiques d’une même table logique. Dans le même temps, cette conception complique les efforts de protection des données.
Plusieurs facteurs rendent le masquage particulièrement important dans les environnements Vertica :
- De larges tables analytiques combinent souvent des métriques commerciales avec des attributs sensibles.
- Plusieurs projections peuvent répliquer des colonnes sensibles à travers le cluster.
- Des clusters partagés desservent simultanément les outils BI, les pipelines ETL, les notebooks et les travaux ML.
- Les requêtes SQL ad hoc contournent fréquemment les couches de reporting organisées.
- Le contrôle d’accès natif basé sur les rôles ne fournit pas de rédaction au niveau des colonnes.
Les contrôles d’accès de Vertica déterminent qui peut interroger une table ; cependant, ils ne contrôlent pas quelles valeurs apparaissent dans les résultats des requêtes. Une fois une requête exécutée, Vertica retourne toutes les colonnes sélectionnées en clair. Pour combler cette lacune, les organisations introduisent une couche de masquage externe qui comprend la sensibilité des colonnes et le contexte utilisateur.
Pour plus de contexte sur la façon dont Vertica traite les workloads analytiques, consultez la documentation officielle de l’architecture Vertica.
Comment fonctionne le masquage dynamique des données avec Vertica
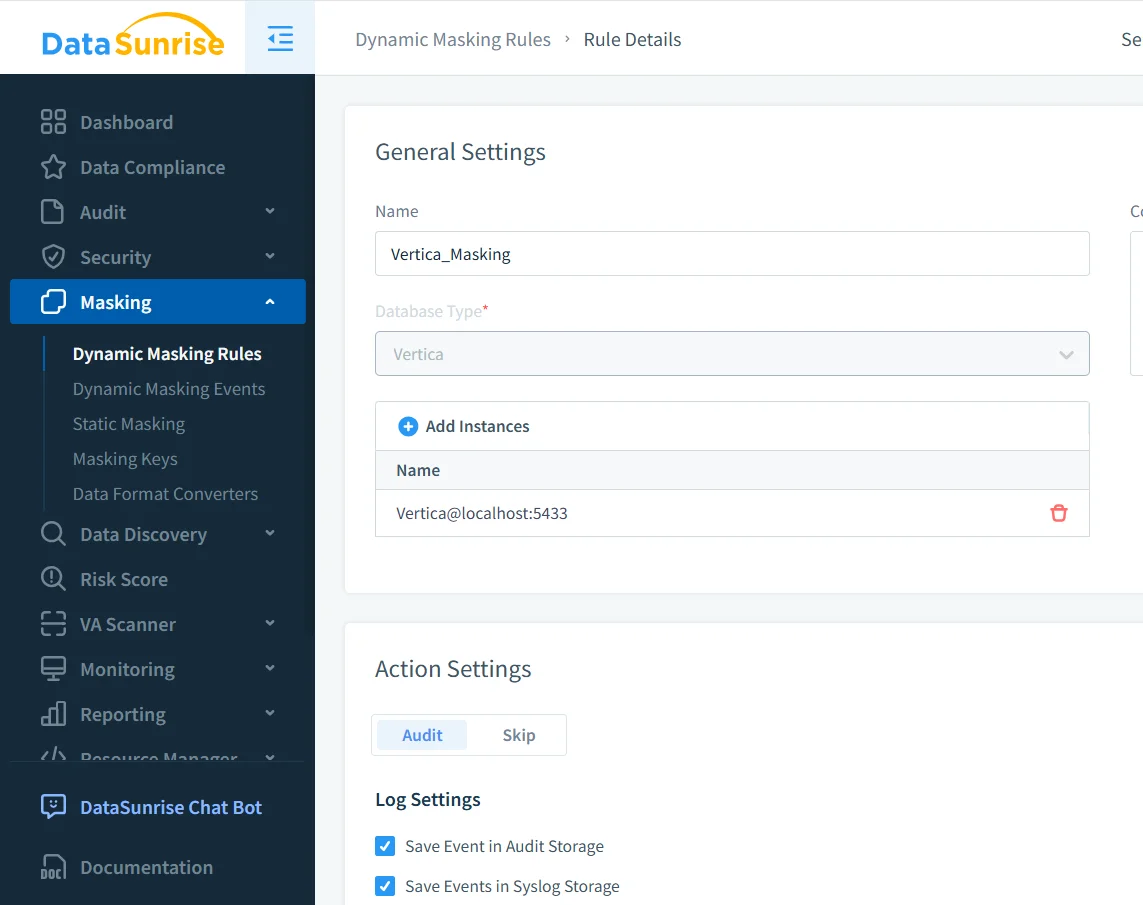
Les organisations implémentent généralement le masquage dynamique des données dans Vertica en utilisant un modèle basé sur un proxy. Dans cette configuration, les applications clientes se connectent à une passerelle de masquage au lieu de se connecter directement à la base de données. Ainsi, chaque requête SQL passe par cette passerelle où les politiques de masquage sont évaluées avant exécution.
Le flux de masquage suit une séquence cohérente :
- Le moteur de masquage analyse et parse la requête SQL.
- Le moteur vérifie les colonnes référencées par rapport à un catalogue de sensibilité.
- Les règles de masquage sont évaluées en fonction de l’utilisateur, de l’application ou de l’environnement.
- La passerelle réécrit les résultats des requêtes pour que les valeurs sensibles apparaissent masquées.
Le système laisse les tables et projections Vertica sous-jacentes inchangées. Comme le masquage intervient uniquement dans le jeu de résultats renvoyé, cette approche évite la duplication des données et préserve les performances des requêtes.
De nombreuses organisations mettent en œuvre ce modèle en utilisant DataSunrise Data Compliance, qui offre une couche centralisée de masquage et de gouvernance devant Vertica.
Architecture : Comment masquer les données sensibles dans Vertica avant qu’elles ne quittent la base de données
Le schéma ci-dessous illustre comment les organisations masquent les données sensibles avant qu’elles n’atteignent les outils BI, les clients SQL ou les applications analytiques. En pratique, toutes les requêtes passent par une passerelle de masquage dédiée qui applique les politiques de manière cohérente.
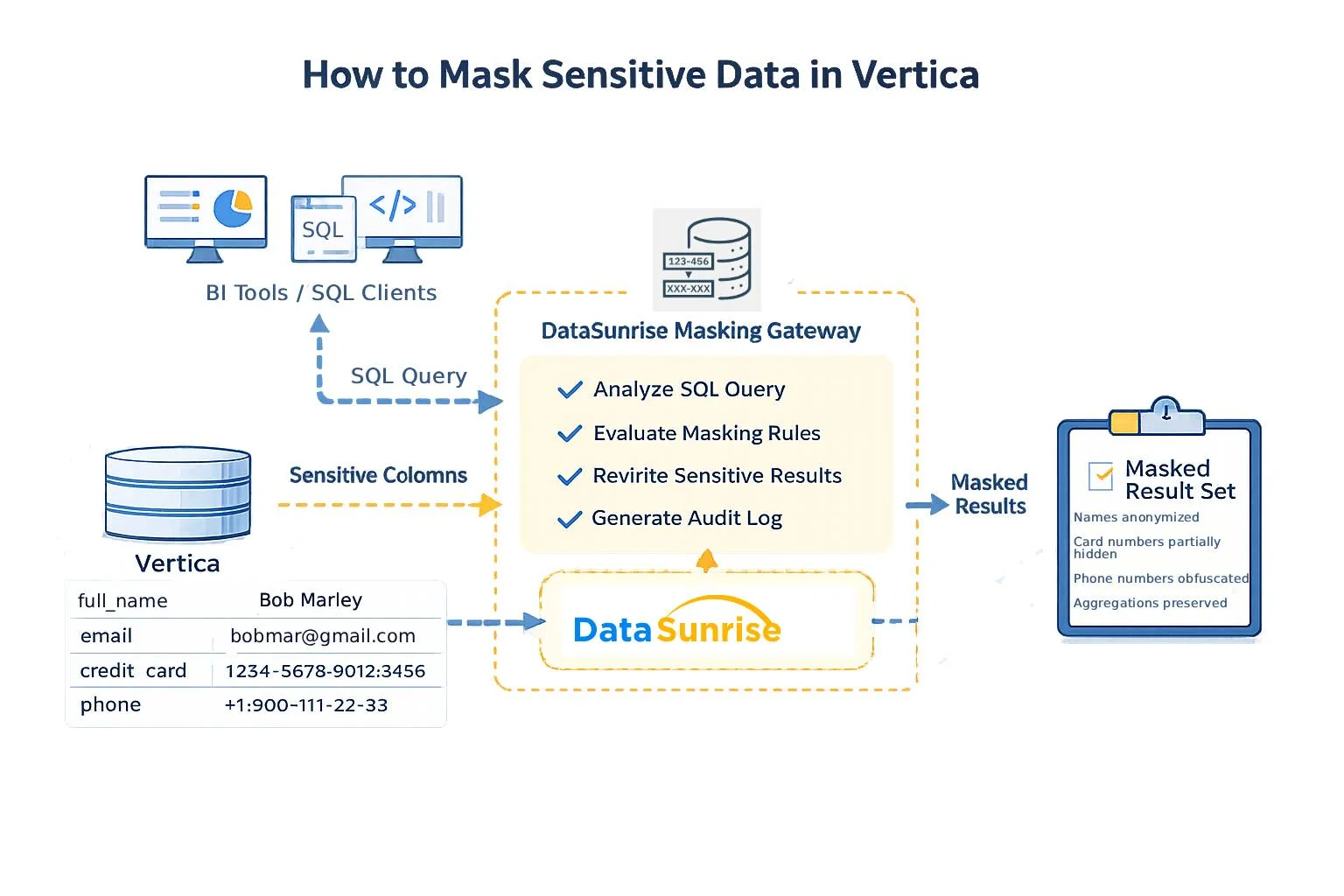
Cette architecture garantit que :
- Les applications continuent d’utiliser un SQL standard sans modifications.
- Les valeurs sensibles ne quittent jamais Vertica en clair.
- Les règles de masquage s’appliquent uniformément à tous les outils et utilisateurs.
Configurer une règle de masquage dynamique dans Vertica
La première étape pratique dans la compréhension de comment masquer les données sensibles dans Vertica consiste à définir une règle de masquage dynamique. Cette règle précise quelle instance Vertica protéger, quelles colonnes sont sensibles et comment le masquage doit se comporter.
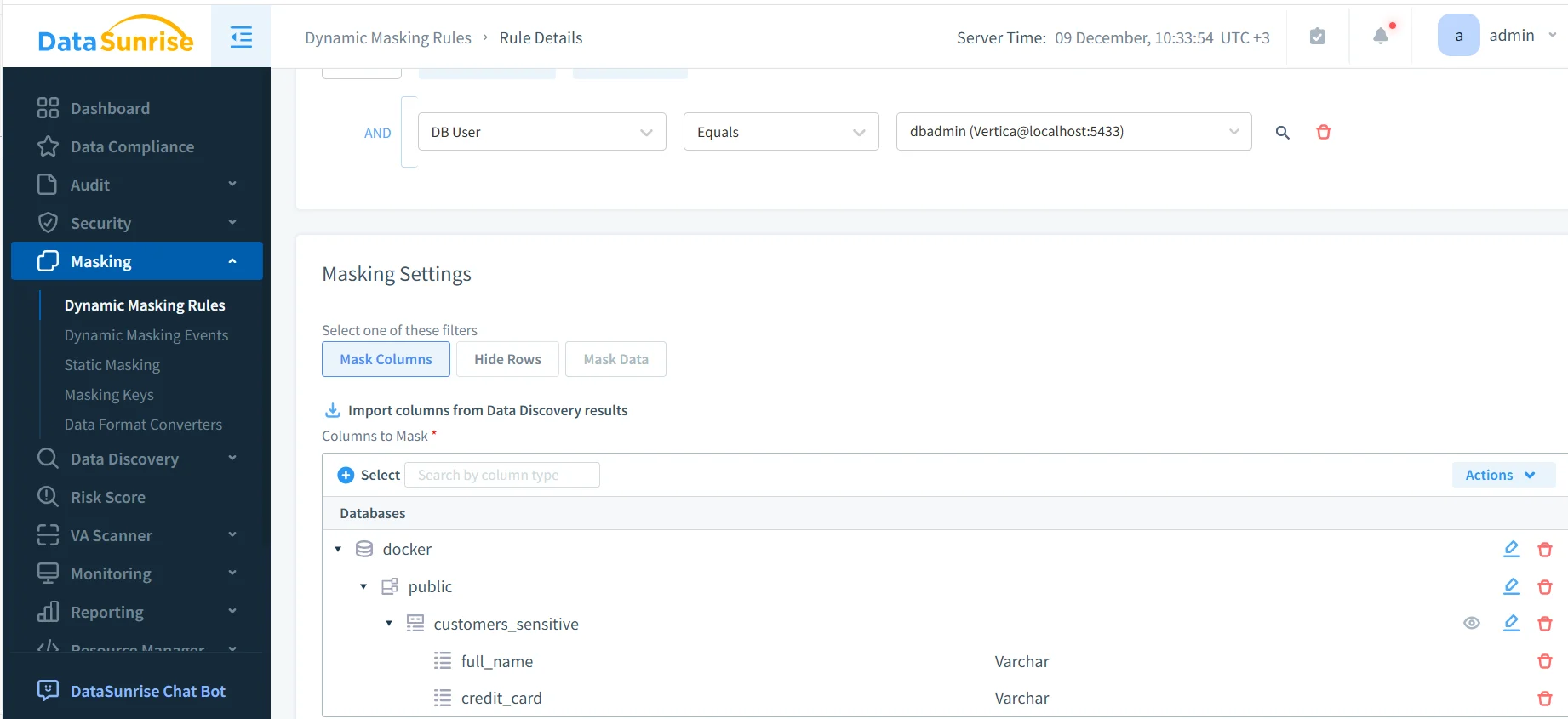
Dans cet exemple, l’administrateur configure une règle de masquage pour une instance de base de données Vertica et l’applique à un schéma et une table spécifiques. Des colonnes sensibles telles que full_name et credit_card sont sélectionnées explicitement. Une fois activée, la règle s’applique automatiquement à chaque requête correspondante.
Les administrateurs peuvent affiner davantage les règles de masquage en utilisant des conditions telles que :
- Utilisateur ou rôle de base de données
- Type d’application cliente
- Emplacement réseau ou environnement
Parce que la règle opère en dehors de Vertica, elle reste efficace même lorsque les schémas évoluent ou que les projections changent.
Résultats des requêtes masquées en pratique
Du point de vue de l’utilisateur, le masquage dynamique ne modifie pas la façon dont les requêtes sont écrites. Les analystes émettent les mêmes instructions SQL qu’à l’accoutumée. Cependant, la différence se manifeste dans les valeurs retournées.
Sans masquage, les résultats des requêtes incluraient les vrais noms, numéros de carte ou détails téléphoniques. Avec le masquage activé, les utilisateurs non privilégiés reçoivent des valeurs anonymisées ou partiellement cachées. En même temps, les agrégations, jointures et filtres continuent à fonctionner correctement, de sorte que les workflows analytiques restent intacts.
Cette approche s’aligne avec les principes de minimisation des données et de pseudonymisation définis dans le RGPD et soutient l’analyse sécurisée conformément aux réglementations telles que HIPAA.
Audit de l’accès masqué dans Vertica
Le masquage seul ne suffit pas à satisfaire les exigences de conformité. Les organisations doivent également démontrer que le masquage a été appliqué de manière constante. Par conséquent, le masquage dynamique fonctionne de concert avec l’audit.
Chaque requête masquée génère un enregistrement d’audit qui capture :
- L’utilisateur de la base de données et l’application cliente
- La requête SQL exécutée
- La règle de masquage qui a été appliquée
- Le timestamp et le contexte d’exécution
Au lieu de parser plusieurs tables système Vertica, les équipes conformité examinent une piste d’audit centralisée. En conséquence, les enquêtes deviennent plus rapides et les audits réglementaires plus aisés. Pour des concepts liés, voir Surveillance des activités de base de données.
Masquage dynamique comparé à d’autres approches
| Approche | Description | Limitations |
|---|---|---|
| Tables statiques masquées | Copies pré-masquées des données de production | Maintenance élevée, duplication des données |
| Vues SQL | Colonnes masquées exposées via des vues | Contournées par les requêtes ad hoc |
| Contrôle d’accès basé sur les rôles uniquement | Permissions au niveau table ou schéma | Pas de protection au niveau des colonnes |
| Masquage dynamique des données | Masquage des valeurs au moment de la requête | Nécessite une couche d’application externe |
Bonnes pratiques pour masquer les données sensibles dans Vertica
- Commencez par la découverte. La classification automatisée fournit la base pour un masquage efficace.
- Centralisez les politiques. Gardez la logique de masquage dans DataSunrise plutôt que dispersée dans des vues SQL.
- Testez avec des workloads réels. Validez le masquage à l’aide de requêtes BI et notebooks concrètes.
- Revuez régulièrement les audits. La surveillance continue aide à détecter rapidement les accès imprévus.
- Alignez avec la stratégie de sécurité. Coordonnez le masquage avec les contrôles plus larges de sécurité des données.
Conclusion
Comment masquer les données sensibles dans Vertica consiste avant tout à appliquer la protection au bon niveau. En masquant les données de manière dynamique au moment de la requête, les organisations préservent la puissance analytique de Vertica tout en réduisant le risque d’exposition des informations confidentielles.
Avec une passerelle de masquage dédiée, les valeurs sensibles restent protégées à travers dashboards, scripts et pipelines. En conséquence, les analystes continuent de travailler efficacement, tandis que les équipes conformité gagnent en visibilité et en contrôle. Cet équilibre fait du masquage dynamique des données une capacité fondamentale pour une analytique sécurisée dans Vertica.
