Masquage des données dans Amazon OpenSearch
Le masquage des données dans Amazon OpenSearch est une méthode pratique pour réduire l’exposition des données sensibles sans compromettre les flux de travail de recherche, d’analyse et d’observabilité dont les équipes dépendent. Les clusters OpenSearch ingèrent souvent des événements d’authentification, des journaux d’activité client, des fragments de payload d’application et de la télémétrie opérationnelle. Ces ensembles de données incluent fréquemment des informations personnellement identifiables (PII), des identifiants de compte, des adresses IP et d’autres éléments soumis à réglementation — parfois intégrés dans des messages de journalisation non structurés ou des JSON imbriqués.
AWS fournit la plateforme managée pour le service Amazon OpenSearch, mais la responsabilité de conformité incombe toujours à l’organisation qui exploite les données. En termes de conformité, peu importe que les données soient « seulement dans les logs ». Si elles sont indexées et consultables, elles sont soumises aux exigences de gouvernance et d’audit.
Cet article explique ce qu’est le masquage des données, pourquoi OpenSearch nécessite un masquage au-delà des contrôles d’accès natifs et comment DataSunrise permet un masquage dynamique, des politiques définies par la découverte, l’audit et la génération de rapports pour les environnements OpenSearch.
Ce que signifie le masquage des données pour OpenSearch
De manière générale, le masquage des données remplace les valeurs sensibles par des représentations plus sûres tout en préservant l’utilisabilité. Contrairement au chiffrement au repos (qui protège le stockage), le masquage protège ce que les utilisateurs voient réellement dans les résultats des requêtes. Un aperçu utile est disponible ici : Qu’est-ce que le Masquage des Données.
Dans OpenSearch, le masquage est particulièrement précieux car :
- Les indices stockent souvent des documents semi-structurés avec des champs sensibles disséminés dans les payloads.
- Les tableaux de bord et alertes nécessitent souvent un accès en lecture large pour maintenir les opérations.
- Une fois qu’une requête est autorisée, retourner des valeurs brutes peut violer le principe du moindre privilège.
Pourquoi les contrôles natifs d’OpenSearch ne suffisent pas
Amazon OpenSearch prend en charge des mécanismes solides d’authentification et d’autorisation, et de nombreuses organisations utilisent un contrôle d’accès fin pour restreindre l’accès aux index ou aux champs. Cependant, le contrôle d’accès seul ne résout pas le problème de la « visibilité selon le besoin ». Dans beaucoup de cas, les utilisateurs doivent interroger un index pour effectuer leur travail, mais ils n’ont pas besoin des identifiants personnels bruts dans les résultats.
C’est l’écart comblé par le masquage : il préserve la visibilité opérationnelle (pertinence de recherche, agrégations, tableaux de bord) tout en réduisant l’exposition des valeurs sensibles.
Masquage dynamique vs. statique pour Amazon OpenSearch
Une stratégie de masquage efficace combine généralement deux approches :
- Masquage dynamique (masquage au moment de la requête) : les valeurs sont transformées lorsqu’elles sont renvoyées au demandeur, selon l’identité, le rôle ou le contexte. Voir Masquage Dynamique des Données.
- Masquage statique (masquage au repos pour les copies) : les valeurs sont transformées dans les ensembles de données exportés ou les copies non production utilisées pour les tests, l’analyse ou le développement. Voir Masquage Statique des Données.
Dans les environnements OpenSearch, le masquage dynamique est souvent la première victoire car il protège immédiatement les chemins d’accès en production — sans reconstruire les pipelines ni maintenir des indices parallèles.
Comment DataSunrise permet le masquage pour Amazon OpenSearch
DataSunrise fournit une couche centralisée de sécurité et de conformité pouvant appliquer des règles de masquage, l’audit et la génération de rapports de manière cohérente sur les environnements OpenSearch. Le flux de travail ressemble typiquement à ceci :
- Découvrir les champs et motifs sensibles à travers les indices.
- Restreindre les politiques aux indices, documents et champs qui nécessitent réellement une protection.
- Appliquer des règles de masquage dynamique aux résultats des requêtes selon les utilisateurs/rôles et l’intention d’accès.
- Auditer toute activité pertinente et générer des preuves prêtes pour la conformité.
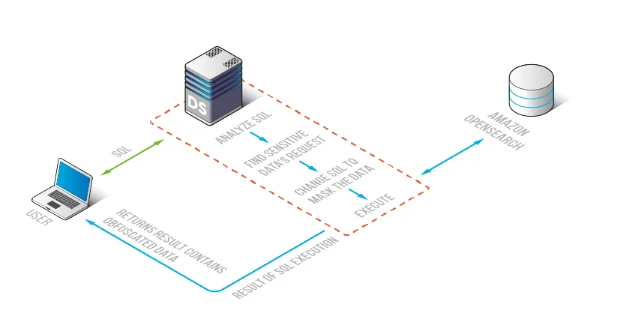
DataSunrise applique les règles de masquage permettant aux requêtes OpenSearch de rester fonctionnelles tout en obscurcissant les valeurs sensibles dans les résultats.
Étape 1 : Découvrir les données sensibles dans OpenSearch
Les règles de masquage ne valent que par l’exhaustivité de votre inventaire de données. Les données OpenSearch évoluent continuellement — de nouveaux champs apparaissent, les pipelines évoluent, et les logs de débogage « temporaires » deviennent permanents. La découverte automatisée est la méthode la plus fiable pour suivre ce rythme.
La découverte de données DataSunrise aide à identifier les motifs sensibles, y compris les PII, à travers les indices et documents OpenSearch. Les résultats de la découverte peuvent directement orienter les objets à gouverner et les champs à masquer.
Le masquage fondé sur la découverte soutient également les programmes réglementés conformes aux réglementations sur la conformité des données et aux cadres communs tels que la conformité GDPR, la conformité HIPAA et la conformité PCI DSS.
Étape 2 : Restreindre le masquage aux bons indices et champs
Une erreur opérationnelle fréquente est d’appliquer les contrôles de sécurité trop largement et de casser les tableaux de bord. Le masquage doit être précisément limité : uniquement là où des valeurs sensibles existent, et uniquement pour les rôles qui ne doivent pas voir les valeurs brutes.
Cette approche est plus facile à opérationnaliser lorsqu’elle est associée à un contrôle d’accès basé sur les rôles clair (RBAC) et au principe du moindre privilège. Le programme de conformité peut lui-même être géré de manière centralisée via le Compliance Manager.
Étape 3 : Configurer les règles de masquage dynamique
Les règles de masquage dynamique définissent comment les valeurs sensibles sont transformées au moment de la requête. Selon votre modèle de gouvernance, le masquage peut être appliqué à des rôles spécifiques (par exemple, des analystes support), des environnements (production vs staging), ou des sources de requête. Les résultats courants du masquage incluent une suppression totale, un masquage partiel, ou une normalisation où seule l’information minimale nécessaire reste visible.
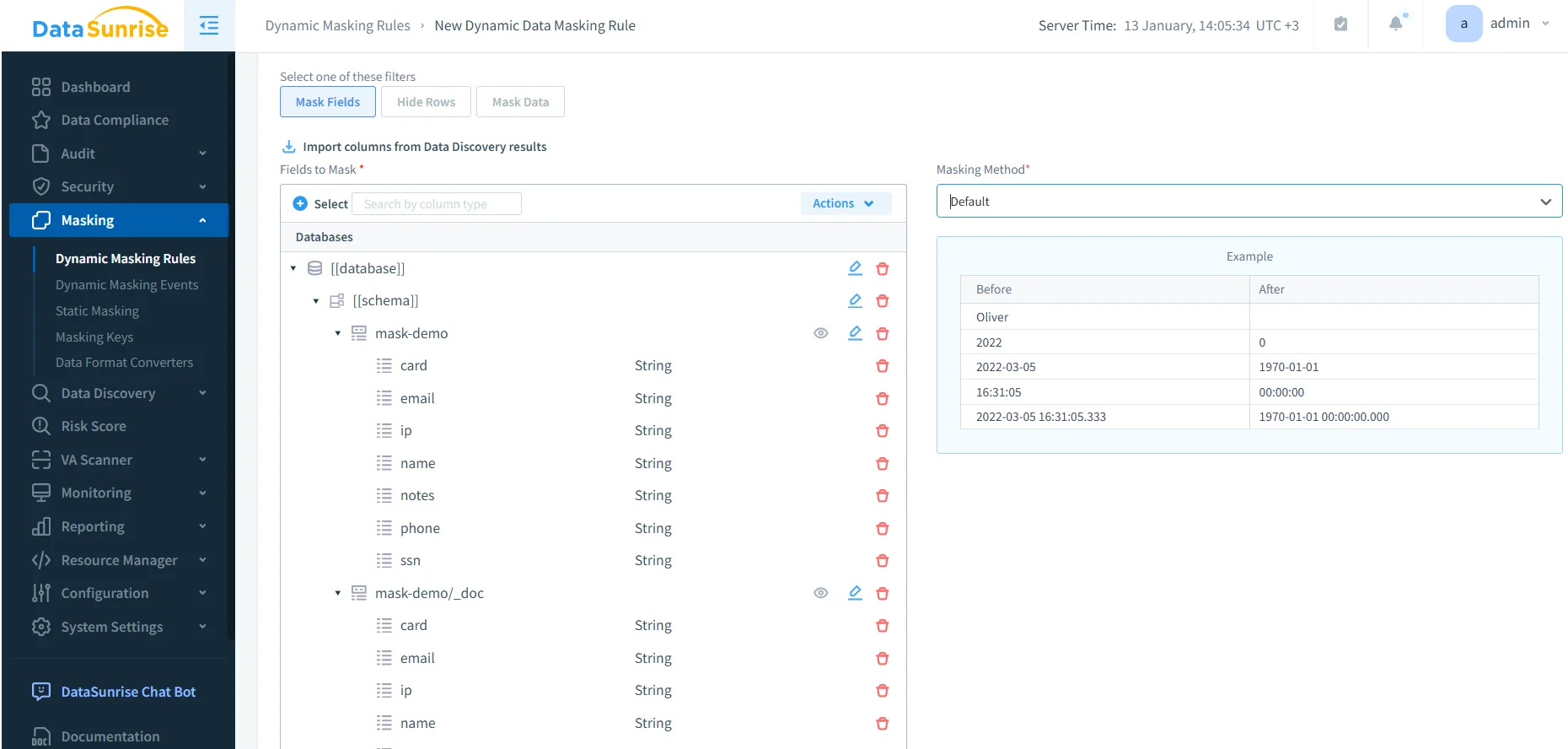
Créer une règle de masquage dynamique : sélectionnez les champs à masquer et choisissez la méthode de masquage pour les données OpenSearch gouvernées.
En pratique, les programmes de masquage réussis incluent :
- Ciblage au niveau des champs : masquer uniquement les champs contenant des valeurs sensibles.
- Visibilité consciente des rôles : permettre aux rôles privilégiés de voir les valeurs complètes lorsque cela est justifié, et masquer pour tous les autres.
- Application déterministe : résoudre les chevauchements de politiques avec un ordre d’évaluation prévisible.
Lorsque plusieurs contrôles s’appliquent, une application cohérente dépend de la priorité des règles. DataSunrise supporte un comportement déterministe grâce à la priorisation des règles.
Étape 4 : Auditer les accès masqués et conserver les preuves
Le masquage est un contrôle de sécurité, mais la conformité nécessite des preuves. Il faut démontrer que les valeurs sensibles ont été protégées et que les accès ont été enregistrés de manière cohérente à travers les environnements.
DataSunrise fournit une audite centralisée des données, des journaux d’audit détaillés, et des pistes d’audit immuables. Pour la surveillance continue, la surveillance d’activité base de données aide à identifier des schémas inhabituels tels que les tentatives d’extraction massive, les recherches répétées de champs sensibles, ou des sources d’accès anormales.
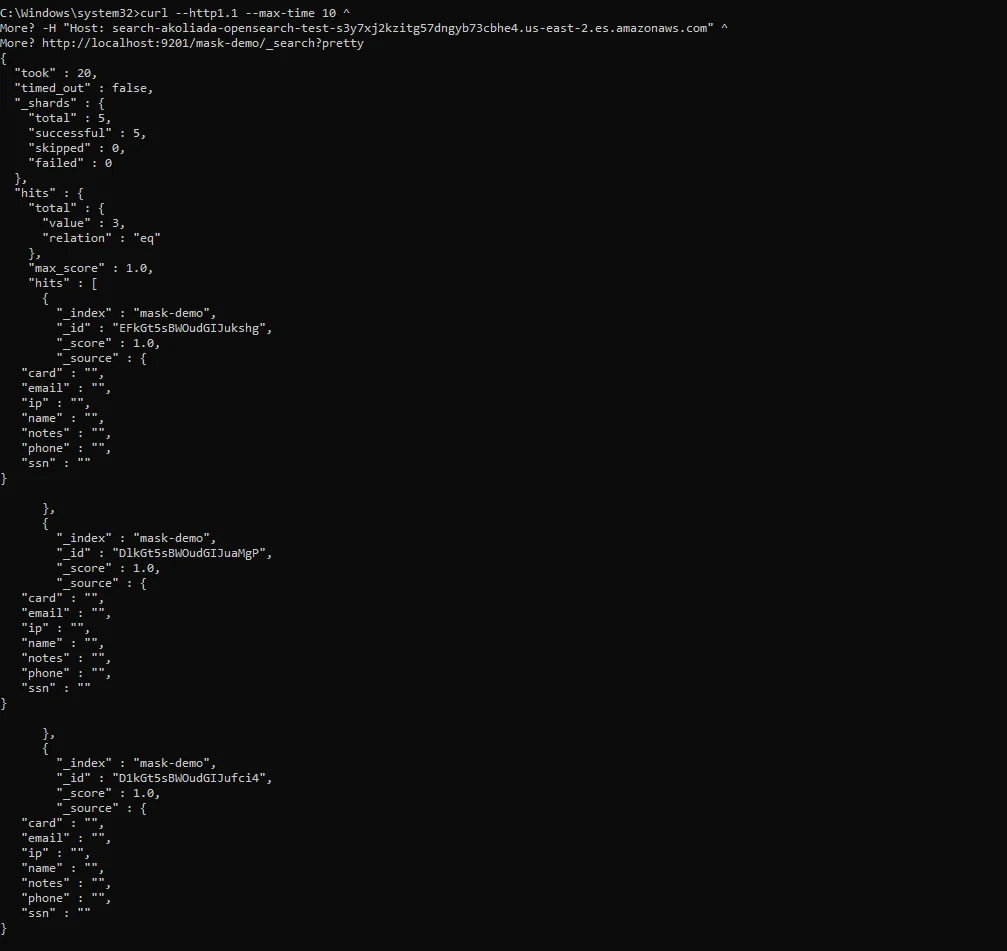
Audit des accès masqués : les sorties des requêtes montrent des valeurs obfusquées tandis que l’activité reste traçable pour les enquêtes et audits.
AWS fournit aussi des fonctionnalités de journalisation au niveau service comme référence minimale. Voir journaux d’audit Amazon OpenSearch. Cependant, les programmes de conformité exigent souvent des preuves cohérentes et des points de contrôle unifiés sur plusieurs environnements et chemins d’accès.
Renforcer le masquage avec des contrôles de sécurité préventifs
Le masquage réduit l’exposition, mais ne devrait pas être la seule ligne de défense. Les programmes solides associent le masquage à des contrôles préventifs qui réduisent les risques d’abus, de mauvaise configuration et de dérive.
- Règles de pare-feu base de données pour bloquer les schémas de requête abusifs.
- Évaluation des vulnérabilités pour détecter faiblesses de configuration et dérives.
- Protection continue des données pour maintenir les contrôles actifs au fur et à mesure de l’évolution des environnements OpenSearch.
Reporting : transformer les contrôles de masquage en preuve de conformité
Les auditeurs acceptent rarement un simple « nous avons activé le masquage » comme preuve. Ils veulent des preuves que les contrôles existent, sont appliqués de manière cohérente et restent actifs dans le temps. DataSunrise supporte la consolidation des preuves de conformité via la génération de rapports, réunissant les résultats de découverte, les politiques de masquage, et l’activité d’audit dans des livrables prêts à être examinés.
Conclusion : rendre le masquage dans OpenSearch opérationnel, pas occasionnel
Le masquage des données dans Amazon OpenSearch est un contrôle pratique et à fort impact pour réduire l’exposition des données sensibles tout en conservant les fonctionnalités de recherche et d’analyse. L’approche la plus efficace combine la découverte, l’application précise des politiques, le masquage dynamique au moment de la requête, et la collecte de preuves prêtes pour l’audit — afin que la conformité soit continue et non réactive.
Pour explorer les options d’implémentation, consultez la présentation de DataSunrise, comparez les modes de déploiement, et commencez par une démonstration ou un téléchargement pour évaluation.
