Conformité NLP, LLM, ML pour Elasticsearch
Les déploiements modernes d’Elasticsearch ingèrent tout : journaux, analyses produit, clickstreams, signaux comportementaux, transcriptions de discussions, documents, traces et interactions clients. Ces environnements, souvent alimentés par des plateformes telles que Elasticsearch, accumulent d’immenses quantités de données non structurées et semi-structurées. Une grande partie de ce contenu contient des informations personnellement identifiables (PII), des informations de santé protégées (PHI), des identifiants et des attributs financiers. Sans contrôles de conformité automatisés — en particulier ceux alimentés par le NLP, les LLM et le ML — Elasticsearch devient un référentiel non contrôlé d’informations sensibles.
DataSunrise relève ce défi grâce à une découverte pilotée par NLP, une génération de politiques assistée par LLM, une analyse comportementale et une détection de dérive fondée sur le ML, sécurisant les documents JSON structurés, semi-structurés et en texte libre sur toute topologie de cluster. Ces contrôles complètent les mécanismes de défense natifs tels que RBAC et le Pare-feu de Base de Données, tout en s’intégrant aux outils avancés de gouvernance comme le Gestionnaire de Conformité.
Importance des outils de conformité des données NLP, LLM & ML
Les protections natives d’Elasticsearch se concentrent sur les permissions et la journalisation des API, mais n’analysent jamais ce que contiennent réellement les données. À mesure que les clusters grandissent, ils accumulent des mappages JSON incohérents, des champs dynamiques, des formats de journaux imprévisibles et des textes générés par les utilisateurs contenant des identifiants cachés. Cela crée des angles morts que les contrôles traditionnels — même combinés à la sécurité des données ou un contrôle d’accès basé sur les rôles strict — ne peuvent pas pleinement corriger.
Les couches de conformité NLP, LLM et ML comblent cette lacune. Elles interprètent le langage naturel, localisent les informations sensibles dans les entrées en texte libre, détectent automatiquement les manquements à la conformité et révèlent des risques que les règles d’indexation ne peuvent faire apparaître. Associées à l’audit continu via la Surveillance de l’activité de la base de données, ces capacités pilotées par l’IA préviennent la dérive réglementaire et renforcent la gouvernance pour les installations Elastic à grande échelle.
Fonctionnalités natives pour la conformité des données dans Elasticsearch
Elasticsearch intègre plusieurs mécanismes fondamentaux de sécurité et de gouvernance. Toutefois, ils restent opérationnels et ne peuvent assurer une conformité sémantique.
1. Sécurité au niveau de l’index & Contrôle d’accès basé sur les rôles
Le RBAC d’Elasticsearch permet des permissions au niveau des index, des restrictions au niveau des champs et des mappages de rôles basés sur le domaine :
PUT /_security/role/pii_reader
{
"indices": [
{
"names": [ "customer-data-*" ],
"privileges": [ "read" ],
"field_security": {
"grant": [ "name", "email", "account_id" ]
}
}
]
}
Cela aide à appliquer des contrôles de lecture similaires aux contrôles d’accès traditionnels, mais il ne peut pas classifier les PII ni s’ajuster automatiquement en cas de dérive du schéma.
2. Journalisation d’audit X-Pack
Les journaux d’audit capturent les événements d’authentification, l’application des rôles, l’usage des API et l’activité de lecture/écriture :
xpack.security.audit.enabled: true
xpack.security.audit.logfile.events:
include: ["authentication_success", "authentication_failed", "access_granted", "access_denied"]
Bien qu’Elasticsearch enregistre le comportement des utilisateurs, il manque de compréhension sémantique et de fonctionnalités avancées de détection des menaces que l’on trouve dans l’Analyse du Comportement Utilisateur.
3. Pipelines d’ingestion & Scripts
Les pipelines d’ingestion permettent des transformations déterministes comme le hachage ou la rédaction :
PUT _ingest/pipeline/redact_email
{
"processors": [
{
"gsub": {
"field": "message",
"pattern": "(?i)[A-Z0-9._%+-]+@[A-Z0-9.-]+",
"replacement": "[REDACTED_EMAIL]"
}
}
]
}
Utile mais limité — contrairement au Masquage Dynamique des Données, les pipelines n’identifient pas automatiquement le texte sensible et se cassent facilement lorsque les formats évoluent.
Outils de conformité des données NLP, LLM & ML pour Elasticsearch (DataSunrise)
DataSunrise étend Elasticsearch avec des capacités de conformité autonomes et multi-couches. Celles-ci s’intègrent parfaitement à son infrastructure existante et offrent une protection bien plus poussée que le RBAC basique, la rédaction par pipeline ou les journaux d’audit natifs.
Découverte des données sensibles basée sur le NLP
DataSunrise utilise l’analyse NLP pour identifier les informations sensibles dans les indices Elasticsearch. Il lit les documents, les champs imbriqués et les enregistrements en texte libre pour localiser les identifiants personnels, les détails financiers, les identifiants d’accès, les références liées aux PHI, les données géographiques et les PII intégrés dans les journaux et les transcriptions. Contrairement à l’inspection traditionnelle des mappages, le NLP détecte le sens plutôt que les noms des champs.
Les résultats alimentent directement la génération de politiques, le masquage et la création automatisée de règles — et s’intègrent aux pratiques de découverte au niveau de l’entreprise également utilisées dans la Découverte de Données et la Classification PII. Un rescannage régulier garantit qu’Elasticsearch reste conforme à mesure que les données évoluent et augmentent.
Autopilote de conformité assisté par LLM
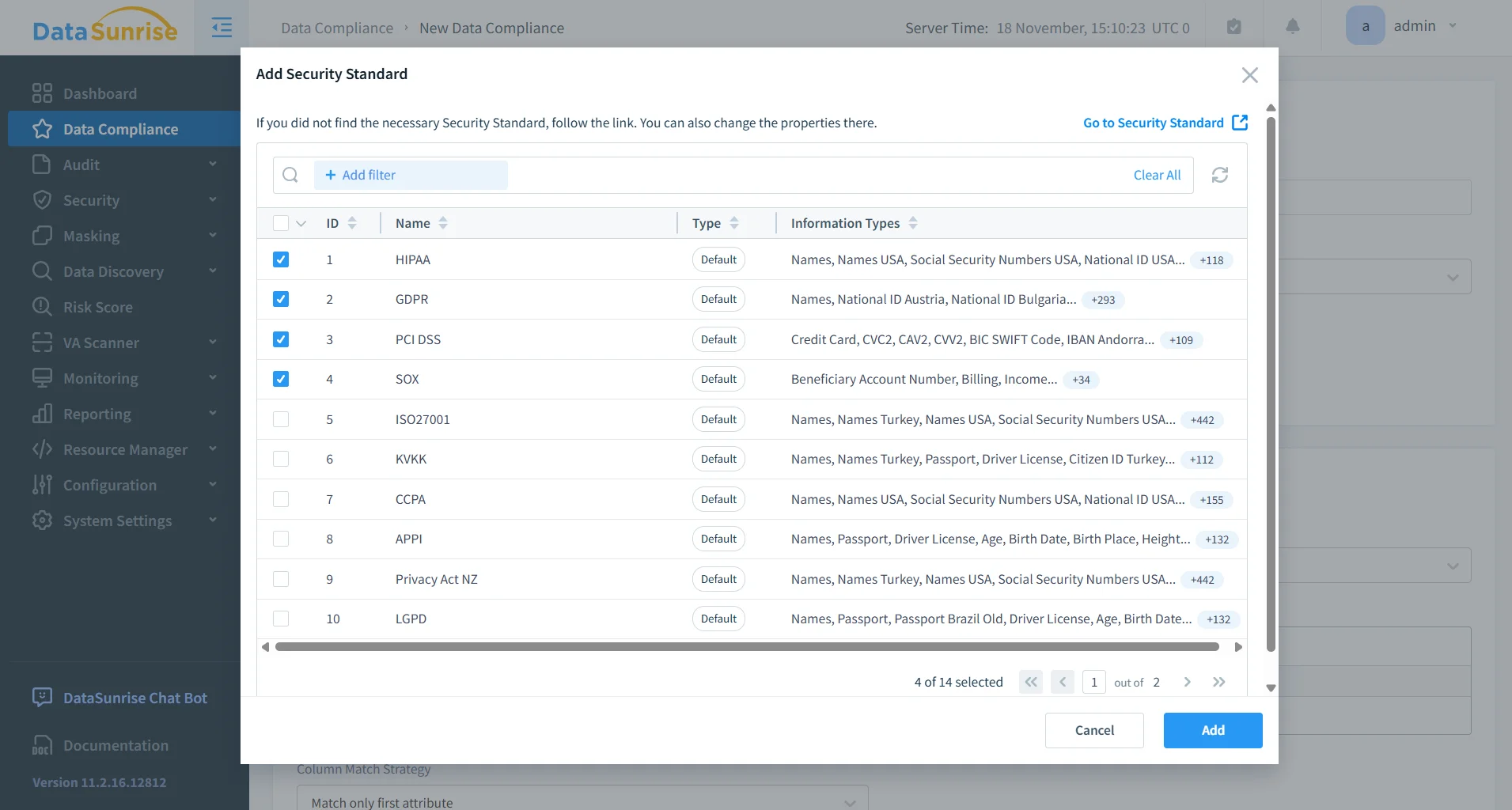
Les grands modèles de langage automatisent la création des règles de conformité, réduisant le travail manuel d’ingénierie des politiques. Le système génère des règles de masquage, construit des modèles d’audit alignés avec GDPR, HIPAA, PCI DSS, SOX et CCPA, et propose des restrictions d’accès basées sur les données sensibles découvertes.
Il offre également des suggestions de remédiation, aidant les équipes à comprendre les violations. L’automatisation par LLM s’aligne parfaitement avec la supervision centralisée gérée via la base de connaissances des Réglementations en matière de conformité des données et le cadre plus large Conformité SOX, PCI DSS, HIPAA.
Intelligence d’audit basée sur le ML
Le ML évalue l’activité Elasticsearch et met en évidence les anomalies. Il détecte les pics de récupération de données, les schémas de requêtes inhabituels, les rafales de mises à jour, les abus de rôles élevés et les écarts par rapport aux comportements usuels des utilisateurs. Ces informations apportent une intelligence absente des journaux d’audit natifs et renforcent significativement la détection proactive aux côtés de protections existantes telles que la Détection de Menaces.
Les informations ML s’intègrent à votre écosystème d’audit global, complétant la journalisation structurée analysée via les Journaux d’Audit et soutenant l’analyse à long terme à travers l’Historique d’Activité des Données.
Masquage dynamique des données pour Elasticsearch
Le masquage dynamique garantit que les données sensibles ne sont jamais exposées directement lors de l’exécution des requêtes. DataSunrise masque les données en temps réel à travers les dashboards Kibana, les appels API REST, les requêtes OpenSearch, les flux d’ingestion et les pipelines analytiques.
Les modes de masquage incluent le hachage cohérent, la tokenisation, la suppression basée sur les rôles et la rédaction. Contrairement à la rédaction statique ou au masquage basé sur l’ingestion, le masquage dynamique fonctionne de manière similaire aux outils de Masquage Statique des Données et au Masquage sur Place disponibles sur d’autres plateformes — sans réindexation ni réécriture de pipeline.
Calibration réglementaire continue
À mesure que les structures Elasticsearch évoluent, DataSunrise adapte automatiquement les règles de conformité. Il détecte les nouveaux index, les nouveaux champs, les modifications de mappages, les nouvelles catégories sensibles et les changements dans les exigences réglementaires.
Cette fonctionnalité adaptative reflète la posture plus large de DataSunrise utilisée dans les environnements multi-bases de données et cloud, aussi soutenue par les Modes de déploiement et les stratégies d’application multi-réglementation liées à la Conformité GDPR.
Tableau de bord unifié de conformité
DataSunrise agrège les informations issues de la découverte, du masquage, de l’intelligence d’audit ML et de la détection d’anomalies dans un tableau de bord de gouvernance centralisé. Les équipes peuvent évaluer la répartition des données sensibles, faire correspondre les événements aux règles de sécurité issues du Guide de Sécurité, analyser l’efficacité du masquage, inspecter les violations des politiques et générer des rapports prêts pour les régulateurs grâce au module intégré de Génération de Rapports.
Les vues intégrées rendent possible la gouvernance des déploiements hybrides et multi-cloud Elasticsearch avec la même rigueur appliquée aux bases SQL, NoSQL, au stockage cloud et aux référentiels d’objets.
Impact métier
| Bénéfice | Description |
|---|---|
| Réduction majeure du travail manuel de conformité | La découverte automatique et la construction des politiques éliminent le travail fastidieux d’écriture des règles et de mappage des schémas. |
| Visibilité complète sur les données en texte libre | Le NLP détecte le contenu sensible caché dans les journaux, messages, documents et données de chat — ce qu’Elasticsearch seul ne peut atteindre. |
| Protection en temps réel sans réindexation | Le masquage dynamique protège instantanément les documents sans modifier les données sources ni les pipelines d’ingestion. |
| Préparation accélérée à l’audit et à la certification | Les rapports pilotés par IA accélèrent la préparation GDPR, HIPAA, SOX et PCI DSS. |
| Défense proactive contre les abus de données | La détection d’anomalies alimentée par ML stoppe les schémas d’abus avant qu’ils ne dégénèrent en violations. |
Conclusion
La fonctionnalité intégrée d’Elasticsearch offre une sécurité de base mais manque d’interprétation sémantique et de gouvernance automatisée. Les schémas dynamiques, les JSON désordonnés et l’ingestion de texte libre nécessitent des outils de conformité capables de comprendre le langage, le comportement et le risque.
DataSunrise fournit la détection de sensibilité par NLP, la génération de règles basée sur LLM, l’intelligence d’audit pilotée par ML, le masquage dynamique, des tableaux de bord de conformité unifiés et une calibration continue — combinant toutes les capacités présentes sur sa plateforme, depuis l’Audit de Données jusqu’à la Protection Continue des Données et la Sécurité Inspirée par les Données. Ensemble, elles élèvent Elasticsearch au rang d’environnement sécurisé et conforme de niveau entreprise.
Protégez vos données avec DataSunrise
Sécurisez vos données à chaque niveau avec DataSunrise. Détectez les menaces en temps réel grâce à la surveillance des activités, au masquage des données et au pare-feu de base de données. Appliquez la conformité des données, découvrez les données sensibles et protégez les charges de travail via plus de 50 intégrations supportées pour le cloud, sur site et les systèmes de données basés sur l'IA.
Commencez à protéger vos données critiques dès aujourd’hui
Demander une démo Télécharger maintenant