Apprentissage Fédéré Sécurisé
Alors que les organisations s’activent à entraîner ensemble des modèles d’IA plus intelligents, l’apprentissage fédéré (FL) est devenu l’une des techniques les plus prometteuses pour collaborer sans compromettre la confidentialité des données. Au lieu de centraliser les données sur un serveur unique, chaque participant entraîne un modèle local et ne partage que ses mises à jour.
Si cette configuration réduit l’exposition, elle introduit aussi de nouvelles surfaces d’attaque. Des vulnérabilités telles que l’inversion de gradient et l’empoisonnement des données peuvent toujours révéler des informations privées ou manipuler les résultats. Assurer un apprentissage fédéré sécurisé nécessite une combinaison de cryptographie, de surveillance et de cadres solides de conformité des données.
Comprendre l’Apprentissage Fédéré Sécurisé
Dans les systèmes fédérés, les participants — souvent des hôpitaux, des banques ou des institutions de recherche — entraînent de manière collaborative un modèle partagé. Chaque nœud calcule les mises à jour localement et n’envoie que les paramètres du modèle ou les gradients à un agrégateur.
Cependant, des attaquants peuvent toujours rétroconcevoir des données sensibles à partir de ces gradients. Des chercheurs de Google AI ont introduit ce concept, mais des études ultérieures ont démontré que même les gradients chiffrés peuvent divulguer des informations identifiables s’ils ne sont pas gérés correctement.
C’est là qu’intervient l’apprentissage fédéré sécurisé — en introduisant :
Un chiffrement de bout en bout
Surveillance des activités pour l’auditabilité
Détection d’anomalies via l’analyse comportementale
Ces mesures garantissent que les mises à jour du modèle restent vérifiables, chiffrées et conformes pour tous les participants.
Principaux Défis de Sécurité
Attaques d’Inversion de Gradient – Les adversaires reconstruisent des échantillons privés à partir des gradients partagés, exposant des informations personnelles identifiables (PII).
Empoisonnement du Modèle – Des contributeurs malveillants peuvent injecter des données biaisées ou des portes dérobées, contournant les défenses du pare-feu.
Agrégateurs Non Fiables – Sans un strict contrôle d’accès basé sur les rôles, les nœuds centraux deviennent des points uniques de défaillance.
Dérive de Conformité – Les flux de données multi-juridictionnels posent des défis pour le maintien de la conformité continue avec le RGPD et la HIPAA.
Des revues académiques récentes, comme Zhu et al. (2023), soulignent que les modèles fédérés nécessitent non seulement un chiffrement, mais aussi une gouvernance comportementale — validant les contributions, le contrôle d’accès et les journaux tout au long du cycle de vie du modèle.
Mise en œuvre de l’Agrégation Sécurisée
Le fragment Python suivant démontre un mécanisme d’agrégation sécurisée simplifié qui valide la confiance et filtre les mises à jour malveillantes avant intégration :
from typing import Dict, List
import hashlib
class FederatedSecurityAggregator:
def __init__(self, threshold: float = 0.7):
self.threshold = threshold
self.trust_registry: Dict[str, float] = {}
def hash_gradient(self, gradient: List[float]) -> str:
"""Générer un hash pour la vérification d’intégrité."""
return hashlib.sha256(str(gradient).encode()).hexdigest()
def validate_node(self, node_id: str, gradient: List[float]) -> Dict:
"""Évaluer la fiabilité du nœud et détecter les anomalies."""
gradient_hash = self.hash_gradient(gradient)
trust_score = self.trust_registry.get(node_id, 0.8)
malicious = trust_score < self.threshold
return {
"node": node_id,
"hash": gradient_hash,
"trust_score": trust_score,
"malicious": malicious,
"recommendation": "Exclude" if malicious else "Accept"
}
def aggregate(self, updates: Dict[str, List[float]]):
"""Agrèger uniquement les mises à jour vérifiées."""
return {
node: self.validate_node(node, grad)
for node, grad in updates.items()
}
Cette logique peut être intégrée dans les journaux d’audit et l’historique des activités de données pour la traçabilité et la validation de la conformité.
Bonnes Pratiques d’Implémentation
Pour les Organisations
Confidentialité dès la Conception – Appliquez le masquage dynamique et le masquage statique des données avant l’entraînement.
Stratégie d’Audit Unifiée – Maintenez des pistes d’audit continues entre les nœuds via des outils de découverte de données.
Conformité Réglementaire – Validez le respect des cadres régionaux (RGPD, HIPAA, PCI DSS).
Collaboration Chiffrée – Employez le chiffrement des bases de données pour les canaux inter-organisationnels.
Pour les Équipes Techniques
Notation de Confiance – Maintenez des métriques de fiabilité des nœuds via l’analyse comportementale.
Sécurité des Reverse Proxy – Routez tout le trafic via un reverse proxy pour un contrôle des flux de données.
Surveillance Centralisée – Combinez la surveillance des activités en base avec des politiques de sécurité adaptatives.
Validation Continue – Réévaluez périodiquement les mises à jour des modèles et appliquez le principe du moindre privilège.
FAQ : Apprentissage Fédéré Sécurisé
Q1. Qu’est-ce que l’apprentissage fédéré en une phrase ?
L’apprentissage fédéré permet à plusieurs parties d’entraîner un modèle partagé en conservant les données brutes localement et en ne partageant que les mises à jour du modèle.
Q2. L’apprentissage fédéré rend-il le partage de données conforme par défaut ?
Non — le FL réduit l’exposition mais il faut toujours des politiques, des logs et des contrôles pour satisfaire les cadres comme le RGPD et la HIPAA ; utilisez des contrôles continus de conformité des données.
Q3. Comment prévenir les fuites par inversion de gradient ?
Combinez agrégation sécurisée (par exemple calcul multipartite ou chiffrement homomorphe) avec du bruit de confidentialité différentielle sur les mises à jour, plus un contrôle d’accès strict et des pistes d’audit.
Q4. Quelle est la différence entre TLS et l’agrégation sécurisée ?
TLS protège les mises à jour en transit ; l’agrégation sécurisée assure que le serveur ne peut pas voir les mises à jour individuelles, même si le transport est sécurisé. Utilisez les deux.
Q5. Comment détecte-t-on les mises à jour empoisonnées ou contenant des portes dérobées ?
Utilisez la notation de confiance et la détection d’anomalies (ex. valeurs aberrantes de similarité cosinus, filtres basés sur la perte), mettez en quarantaine les nœuds suspects et appliquez un contrôle d’accès basé sur les rôles.
Q6. Que fait réellement un agrégateur ?
Il vérifie, agrège les mises à jour chiffrées, produit un modèle global et le redistribue ; il ne doit pas accéder aux données brutes ni aux mises à jour clients non anonymisées.
Q7. Où s’insère la conformité dans la boucle ?
Comme une couche de supervision : elle surveille les journaux, configurations et preuves (paramètres de confidentialité différentielle, cycles de vie des clés, correspondances politiques) sans recevoir les gradients. Voir la surveillance des activités base de données et les journaux d’audit.
Q8. Ai-je besoin de confidentialité différentielle à chaque itération ?
De préférence oui pour les données sensibles ; le bruit appliqué à chaque tour avec une comptabilité de la confidentialité limite la fuite cumulée tout en conservant l’utilité.
Q9. Puis-je masquer les champs sensibles avant l’entraînement ?
Oui — appliquez le masquage dynamique ou statique des données en périphérie pour que les champs sensibles n’entrent jamais dans la chaîne de traitement des caractéristiques.
Q10. Comment journaliser sans fuir de données ?
Journalisez les métadonnées (alarmes règles, budgets DP, IDs de nœuds, hachages) et stockez-les dans un dépôt d’audit à preuve de falsification ; évitez les charges utiles brutes.
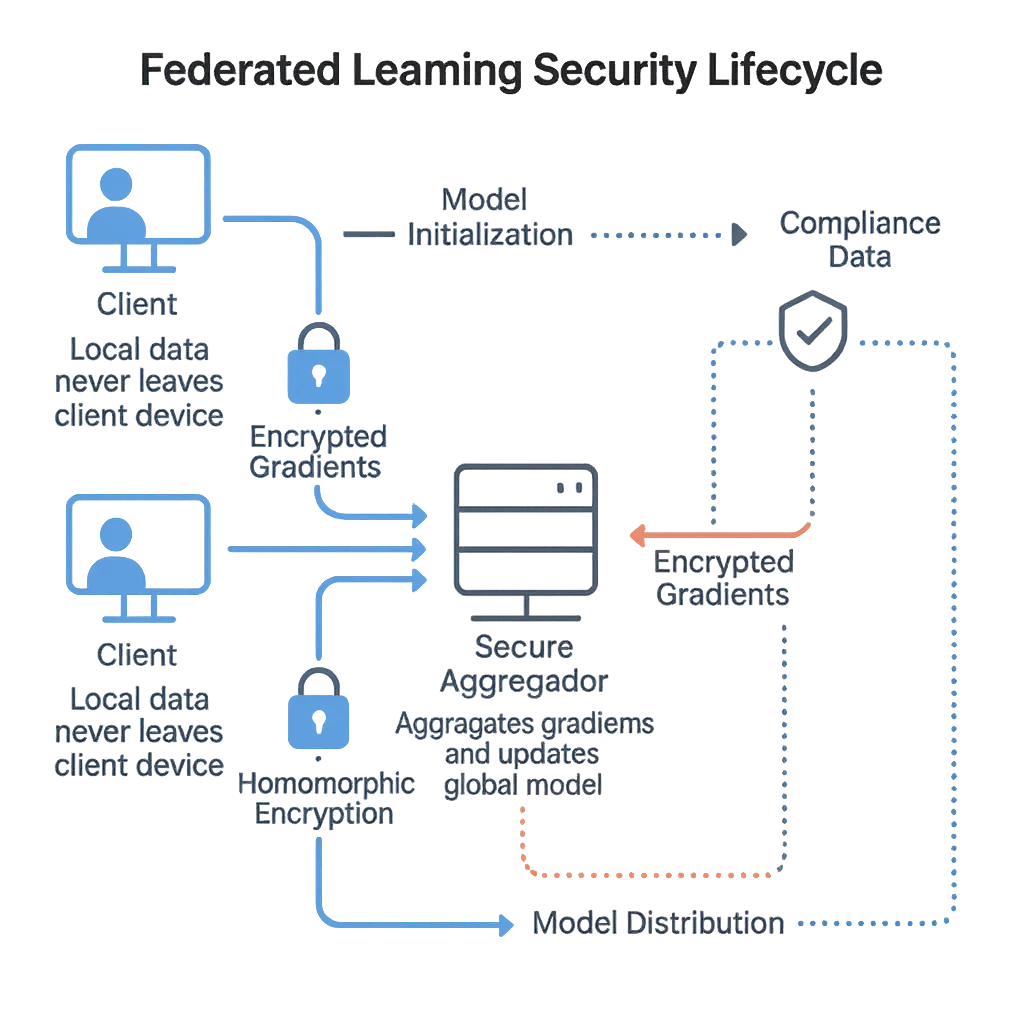
Q11. Quel est le cycle de vie d’un modèle dans l’apprentissage fédéré sécurisé ?
Initialisation → distribution aux clients → entraînement local → mise à jour chiffrée → agrégation sécurisée → validation → mise à jour globale du modèle → redistribution ; répétez avec gestion des versions et restauration.
Q12. Comment DataSunrise aide-t-il ?
Il fournit une surveillance basée sur proxy, le chiffrement, l’analyse comportementale, l’application des politiques et des preuves de conformité tout au long de la pipeline fédérée.
Construire la Confiance dans l’IA Collaborative
L’apprentissage fédéré démontre que collaboration et confidentialité peuvent coexister — mais seulement avec une auditabilité transparente, du chiffrement et une gouvernance rigoureuse. Sans cela, il risque de devenir un angle mort exploitable.
En combinant agrégation sécurisée, analyse comportementale et conformité réglementaire, DataSunrise offre une base pour une IA collaborative digne de confiance. Ses modules de Protection des Données et d’Audit garantissent que chaque contribution au modèle reste vérifiable, traçable et conforme.
Lectures recommandées :
Protégez vos données avec DataSunrise
Sécurisez vos données à chaque niveau avec DataSunrise. Détectez les menaces en temps réel grâce à la surveillance des activités, au masquage des données et au pare-feu de base de données. Appliquez la conformité des données, découvrez les données sensibles et protégez les charges de travail via plus de 50 intégrations supportées pour le cloud, sur site et les systèmes de données basés sur l'IA.
Commencez à protéger vos données critiques dès aujourd’hui
Demander une démo Télécharger maintenant