Guide Complet sur la Recherche de Données Sensibles dans les Images Hébergées sur AWS S3
Pour fournir à nos clients un outil de découverte des données puissant, il y a quelque temps, nous avons présenté la fonctionnalité OCR (Reconnaissance Optique de Caractères) intégrée dans notre module Data Discovery. Cette fonctionnalité vous permet de rechercher des données sensibles telles que des données personnelles, des numéros de cartes de crédit, des permis de conduire, etc. contenues dans des fichiers image. Le processus de découverte est effectué automatiquement sans intervention humaine. Le OCR Data Discovery fonctionne uniquement avec AWS S3 pour le moment.
Le OCR DD de DataSunrise est basé sur le moteur Tesseract qui utilise la technologie des réseaux de neurones pour la reconnaissance des caractères. Tesseract utilise la bibliothèque Leptonica pour lire des images dans l’un des formats suivants :
- PNG
- JPEG
- TIFF
- JPEG 2000
- GIF
- WebP (y compris WebP animé)
- BMP
- PNM
Fonctionnement
Une fois qu’une tâche OCR Data Discovery est lancée, le processus de découverte passe par les étapes suivantes :
- DataSunrise parcourt le contenu du compartiment S3 spécifié à la recherche d’images.
- Le préprocesseur du moteur OCR prépare les images découvertes pour un traitement ultérieur en améliorant leur contraste et leur netteté.
- DataSunrise, avec l’aide de la technologie OCR Tesseract, reconnaît le texte non structuré présent dans les images et utilise des algorithmes de découverte de données en fonction des paramètres de votre tâche de découverte.
En résultat, vous obtenez les noms et l’emplacement des fichiers image contenant des données sensibles ainsi que ces données dans un rapport DD.
Configuration d’une tâche OCR dans DataSunrise
Examinons maintenant le processus de création d’une tâche de découverte de données OCR.
Tout d’abord, notez que le OCR Data Discovery avec NLP Data Discovery nécessite Java 1.8+
Pour utiliser le OCR Data Discovery, vous devez procéder comme suit :
- Avant de passer à l’étape suivante, créez une instance de base de données S3 dans DataSunrise (consultez le guide de l’utilisateur de DataSunrise pour plus de détails).
- Accédez à Data Discovery → Periodic Data Discovery
- Créez une tâche de découverte de données pour votre compartiment S3 :
Remplissez les Paramètres Généraux :

- Nommez la tâche
- Sélectionnez le serveur DS sur lequel démarrer la tâche
- Si vous souhaitez effectuer la découverte de données pour plusieurs instances de base de données, cochez la case correspondante et sélectionnez les instances concernées
- Cochez la case Générer des Rapports pour créer un rapport au format PDF ou CSV.
Dans la section Paramètres de Recherche :
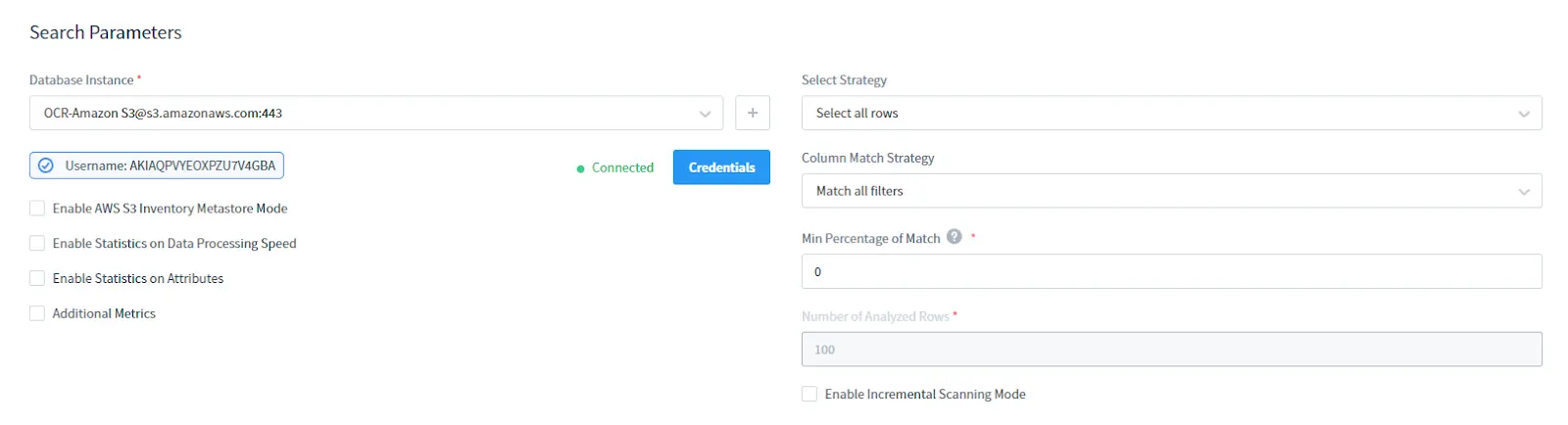
- Sélectionnez votre instance de base de données AWS S3. Fournissez les identifiants pour votre S3
- Choisissez la Stratégie de Sélection : sélectionner toutes les lignes ou seulement les premières lignes
- Sélectionnez la Stratégie de Correspondance de Colonne : type de filtrage de colonne
- Définissez le Pourcentage Minimum de Correspondance : c’est le pourcentage minimal de lignes dans une colonne correspondant aux conditions du filtre de recherche pour considérer que la colonne contient les données sensibles requises
- Sélectionnez le Nombre de Lignes Analysées : nombre de lignes analysées à sélectionner
Dans les Paramètres Multiprocessus :

Sélectionnez la Stratégie d’Exécution : Serveur DS Unique ou Plusieurs Serveurs DS pour un calcul parallèle
Sélectionnez les Objets de BD à explorer :

Utilisez l’arborescence des objets pour spécifier les objets qui doivent être parcourus lors de l’exécution de la tâche
Vous pouvez exclure certains objets de la recherche en utilisant l’arborescence d’objets correspondante :

Dans les Paramètres de Recherche :
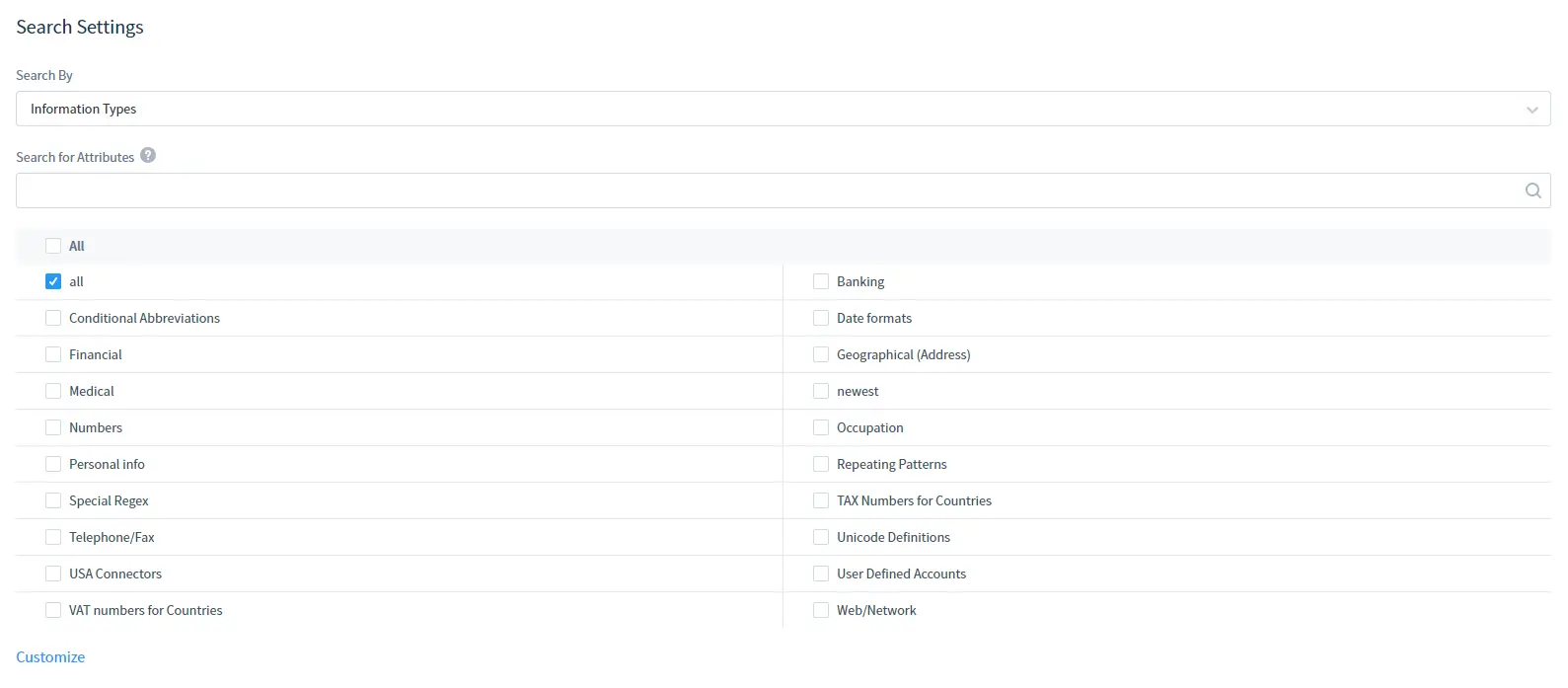
Sélectionnez le Type d’Information ou les Normes de Sécurité selon lesquels effectuer la recherche. Notez que vous pouvez également utiliser la Recherche par Attributs pour trouver un Type d’Information ou une Norme de Sécurité dont vous avez besoin via un attribut.
Dans la section Fréquence de Démarrage :
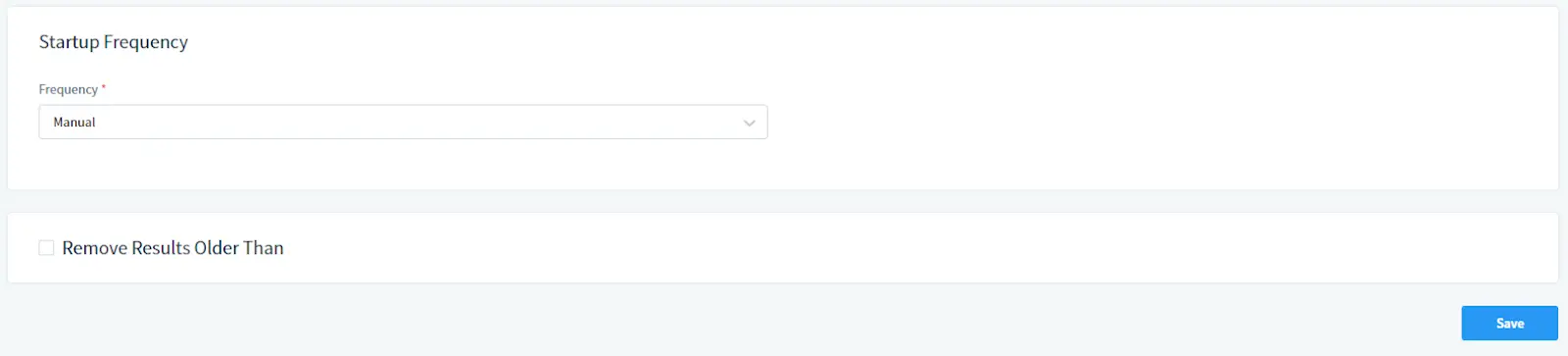
Sélectionnez la fréquence d’exécution de la tâche. Choisissez Manuel pour un démarrage manuel ou définissez un horaire.
Important : vous devez activer le paramètre supplémentaire imageDataDiscovery avant de lancer la tâche. Vous pouvez le faire dans Paramètres Supplémentaires (Paramètres Système -> Paramètres Supplémentaires) ou dans la sous-section Paramètres Supplémentaires Personnalisés de la page de la tâche.
Sélectionnez imageDataDiscovery dans la liste et activez-le comme indiqué ci-dessous :
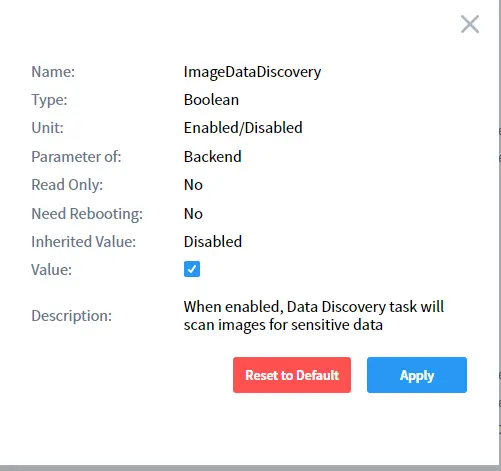
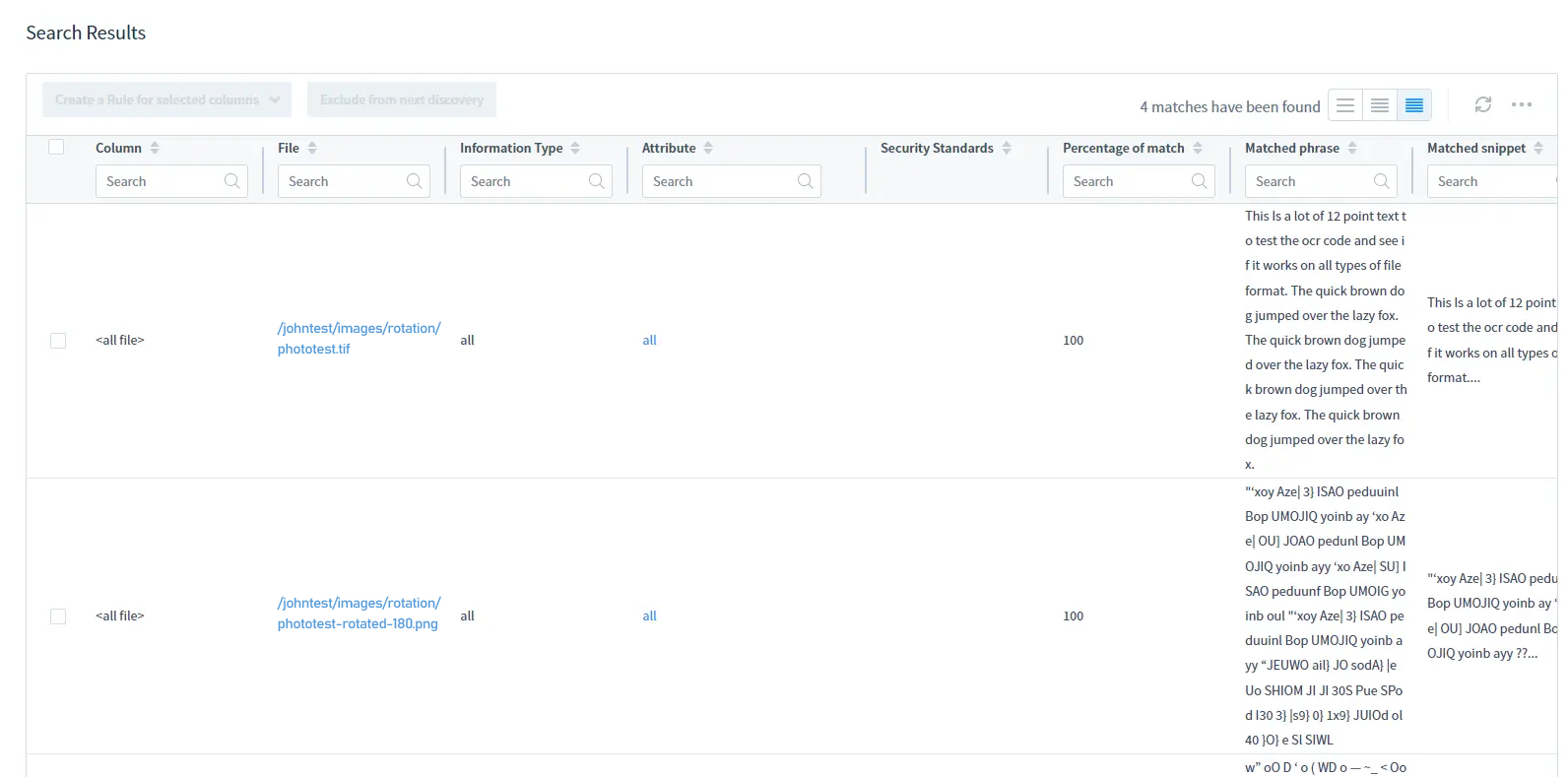
Exécutez la tâche manuellement ou selon un calendrier et DataSunrise effectuera automatiquement la découverte OCR :

Pour les résultats de recherche, référez-vous au tableau des Résultats de Recherche :