Umfassender Leitfaden: Wie man nach sensiblen Daten in Bildern sucht, die auf AWS S3 gehostet werden
Um unseren Kunden ein leistungsstarkes Werkzeug zur Datenerkennung zur Verfügung zu stellen, haben wir vor einiger Zeit die in unser Data Discovery-Modul integrierte OCR-(Optical Character Recognition)-Funktionalität vorgestellt. Diese Funktion ermöglicht es, in Bilddateien enthaltene sensible Daten wie personenbezogene Daten, Kreditkartennummern, Führerscheine usw. zu suchen. Der Entdeckungsprozess erfolgt automatisch, ohne dass menschliches Eingreifen erforderlich ist. OCR Data Discovery funktioniert bislang ausschließlich mit AWS S3.
Das OCR DD von DataSunrise basiert auf der Tesseract-Engine, die neuronale Netzwerktechnologie zur Zeichenerkennung verwendet. Tesseract nutzt die Leptonica-Bibliothek, um Bilder in einem der folgenden Formate zu lesen:
- PNG
- JPEG
- TIFF
- JPEG 2000
- GIF
- WebP (einschließlich animiertem WebP)
- BMP
- PNM
Wie es funktioniert
Sobald eine OCR Data Discovery-Aufgabe gestartet wird, durchläuft der Entdeckungsprozess die folgenden Phasen:
- DataSunrise durchsucht den Inhalt des angegebenen S3-Buckets nach Bildern.
- Der Preprozessor der OCR-Engine bereitet die gefundenen Bilder für die weitere Verarbeitung vor, indem er sie kontrastreicher und schärfer macht.
- DataSunrise erkennt mit Hilfe der Tesseract OCR-Technologie unstrukturierten Text in den Bildern und wendet Data Discovery-Algorithmen auf diesen Text gemäß den Einstellungen Ihrer Data Discovery-Aufgabe an.
Als Ergebnis erhalten Sie die Namen und Speicherorte der Bilddateien, die sensible Daten enthalten, sowie diese Daten in einem DD-Bericht.
Konfiguration einer OCR-Aufgabe in DataSunrise
Werfen wir nun einen Blick auf den Prozess zur Erstellung einer OCR Data Discovery-Aufgabe.
Zunächst beachten Sie, dass OCR Data Discovery mit NLP Data Discovery Java 1.8+ erfordert.
Um OCR Data Discovery zu nutzen, müssen Sie Folgendes tun:
- Erstellen Sie vor dem nächsten Schritt eine S3 DB-Instanz in DataSunrise (siehe DataSunrise User Guide für Details).
- Navigieren Sie zu Data Discovery → Periodische Datenerkennung
- Erstellen Sie eine Data Discovery-Aufgabe für Ihren S3-Bucket:
Füllen Sie die Allgemeinen Einstellungen aus:

- Benennen Sie die Aufgabe
- Wählen Sie den DS-Server aus, auf dem die Aufgabe gestartet werden soll
- Wenn Sie Data Discovery für mehrere DB-Instanzen durchführen möchten, aktivieren Sie das entsprechende Kontrollkästchen und wählen Sie die gewünschten Instanzen aus
- Aktivieren Sie das Kontrollkästchen “Berichte generieren”, um einen Bericht entweder im PDF- oder CSV-Format zu erstellen.
Im Abschnitt Suchparameter:
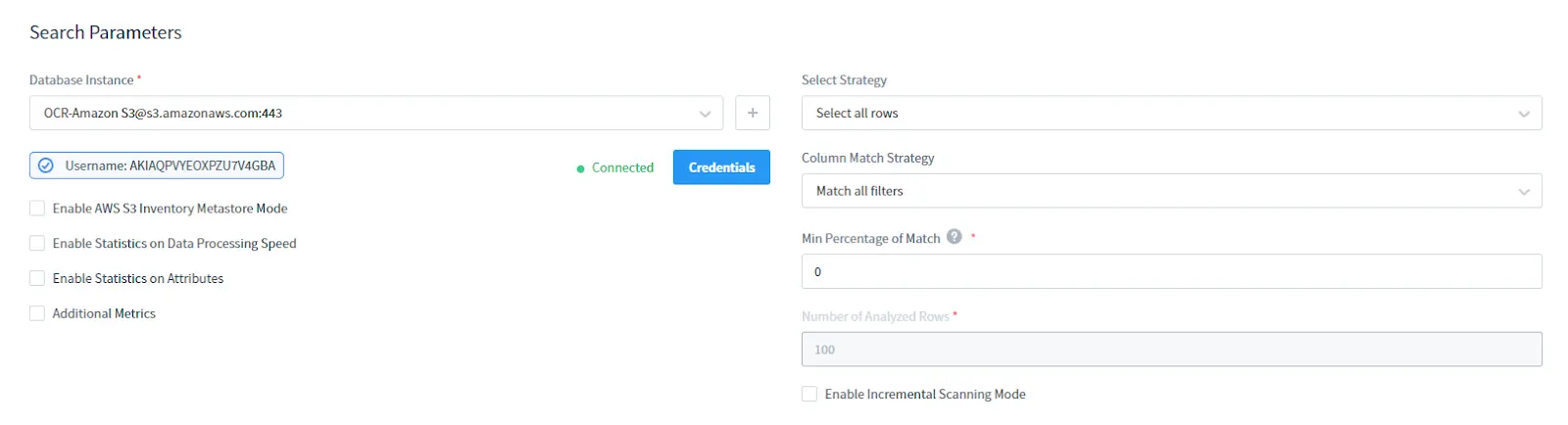
- Wählen Sie Ihre AWS S3 DB-Instanz. Geben Sie die Zugangsdaten für Ihr S3 an
- Wählen Sie die Auswahlstrategie: Alle Zeilen auswählen oder nur die obersten Zeilen
- Wählen Sie die Spaltenvergleichsstrategie: Spaltenfiltertyp
- Setzen Sie den Mindestprozentsatz der Übereinstimmung: Dies ist der Mindestprozentsatz der Zeilen in einer Spalte, die den Suchfilterbedingungen entsprechen, um die Spalte als enthalten der erforderlichen sensiblen Daten zu betrachten
- Wählen Sie die Anzahl der zu analysierenden Zeilen: Anzahl der analysierten Zeilen, die ausgewählt werden sollen
Bei Mehrprozessparametern:

Wählen Sie die Ausführungsstrategie: Einzelner DS-Server oder mehrere DS-Server für parallele Berechnungen
Wählen Sie die DB-Objekte, die durchsucht werden sollen:

Verwenden Sie den Objektbaum, um Objekte anzugeben, die während der Aufgabenausführung durchsucht werden sollen
Sie können bestimmte Objekte von der Suche ausschließen, indem Sie den entsprechenden Objektbaum verwenden:

In den Sucheinstellungen:
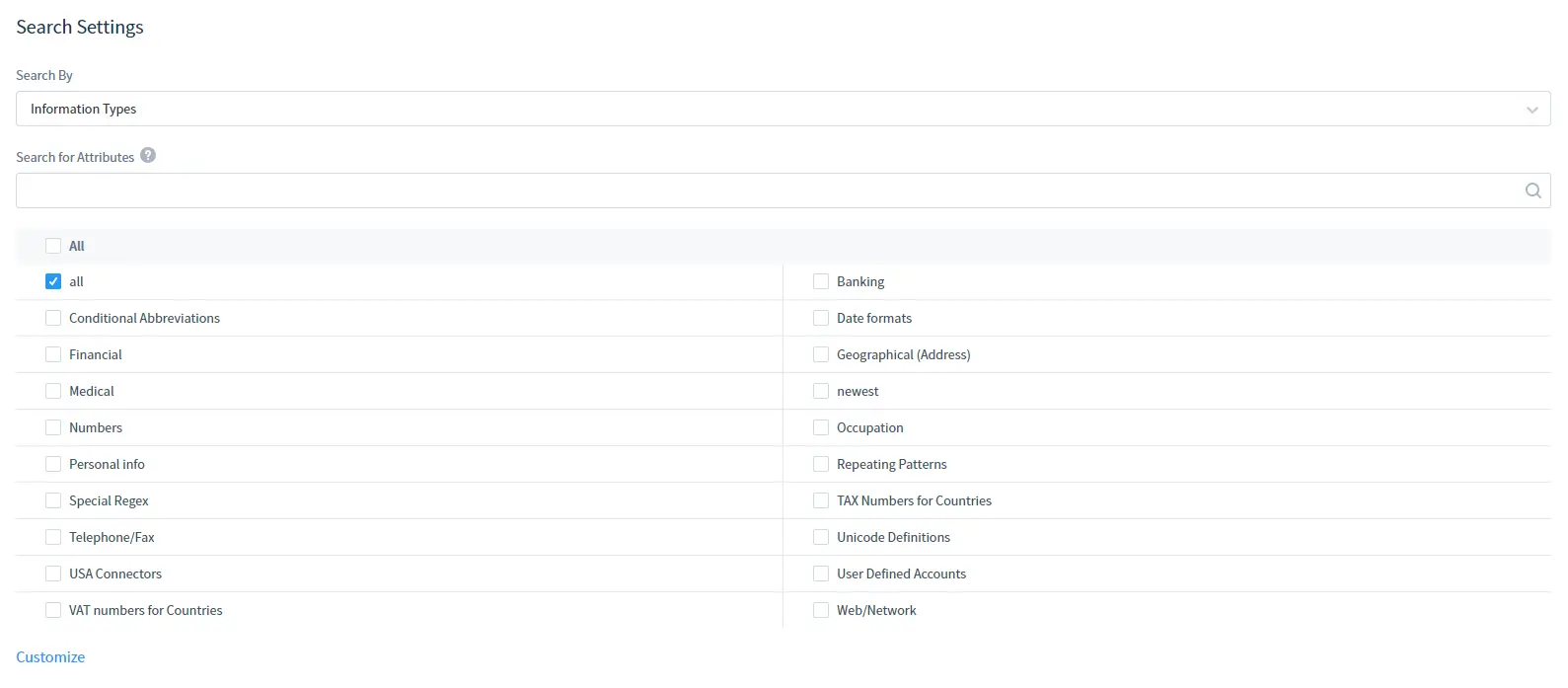
Wählen Sie den Informationstyp oder die Sicherheitsstandards, nach denen gesucht werden soll. Beachten Sie, dass Sie auch die Suche nach Attributen verwenden können, um einen Informationstyp oder Sicherheitsstandard, den Sie benötigen, über Attribute zu finden.
Bei Startfrequenz:
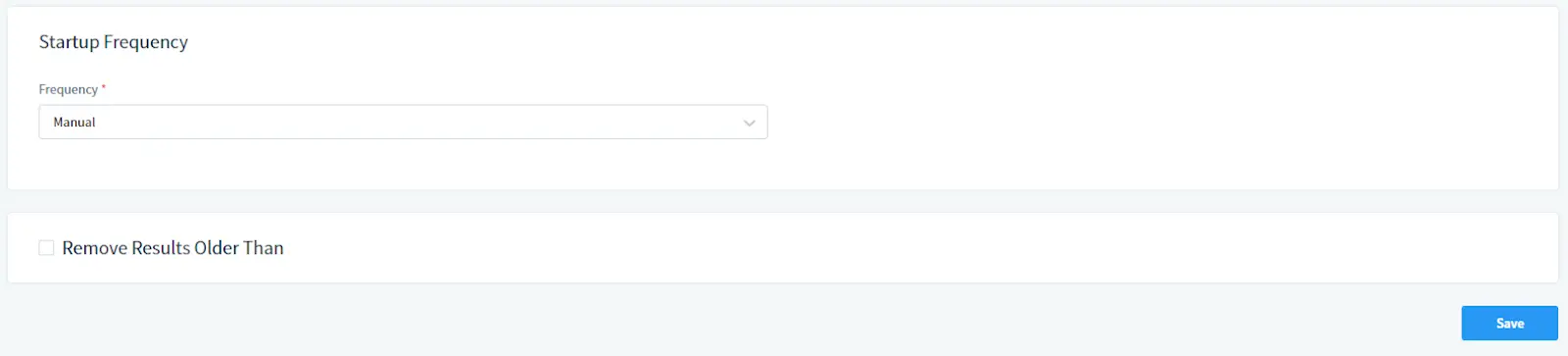
Wählen Sie die Ausführungsfrequenz der Aufgabe. Wählen Sie “Manuell” für einen manuellen Start oder legen Sie einen Zeitplan fest.
Wichtig: Sie müssen den zusätzlichen Parameter imageDataDiscovery vor dem Starten der Aufgabe aktivieren. Dies können Sie in den Zusätzlichen Parametern (Systemeinstellungen -> Zusätzliche Parameter) oder im Unterabschnitt Benutzerdefinierte zusätzliche Einstellungen auf der Aufgabenseite tun.
Wählen Sie imageDataDiscovery in der Liste aus und aktivieren Sie es, wie unten gezeigt:
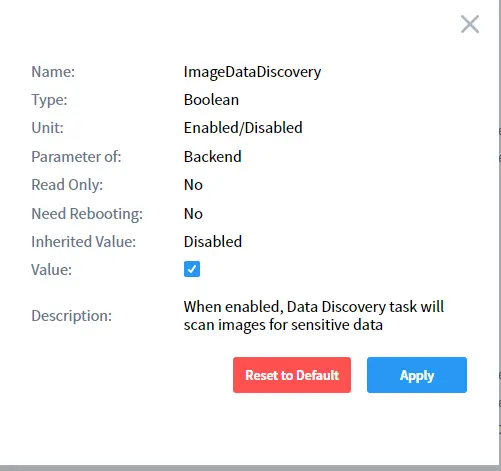
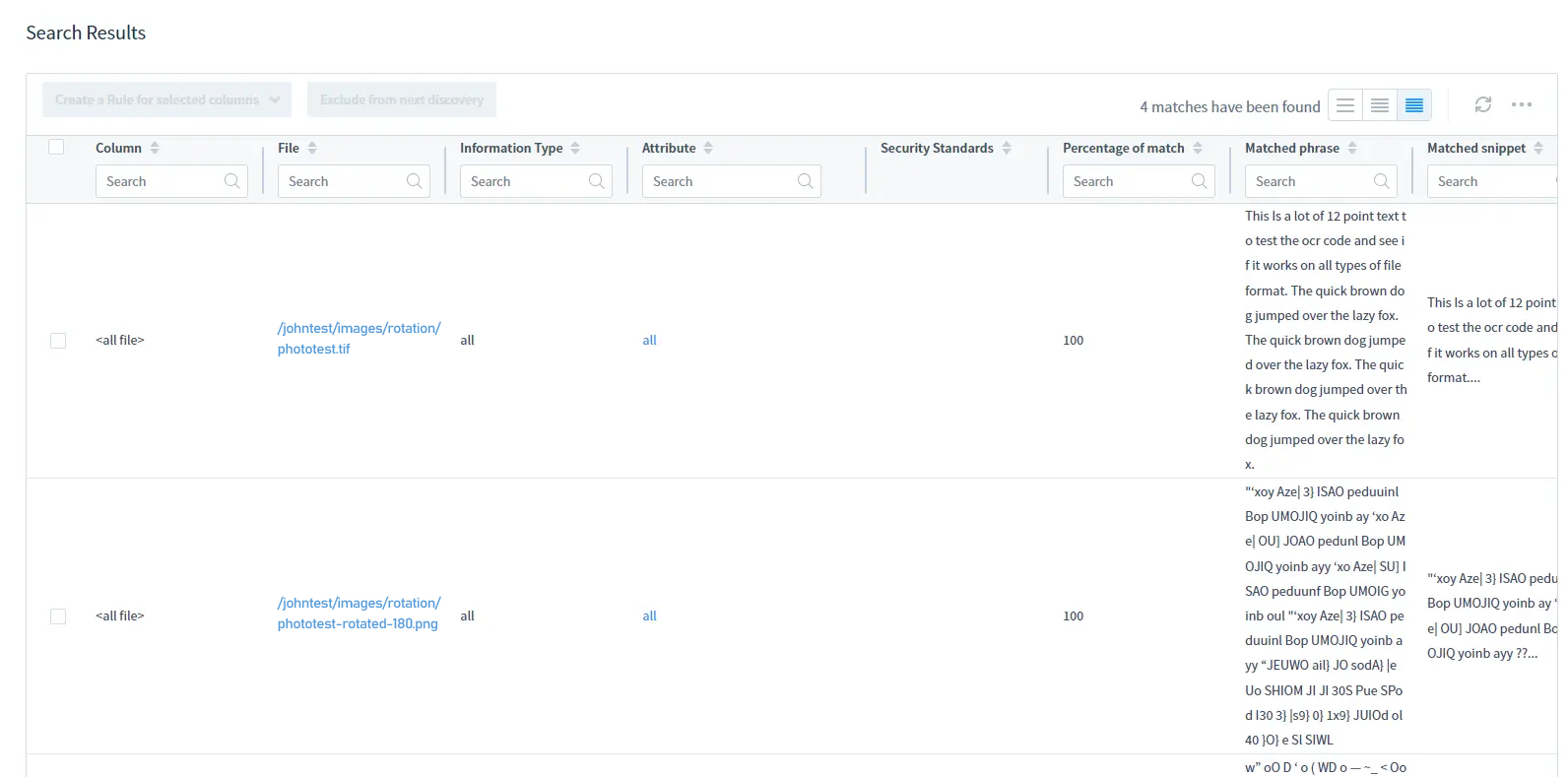
Führen Sie die Aufgabe manuell oder nach Zeitplan aus und DataSunrise führt die OCR-Erkennung automatisch durch:

Für Suchergebnisse konsultieren Sie die Tabelle mit den Suchergebnissen: