Wie man statisches Maskieren in Apache Cloudberry anwendet
Die Implementierung von statischem Maskieren für Apache Cloudberry ist essenziell geworden, um sensible Informationen in Nicht-Produktionsumgebungen zu schützen. Laut aktuellen Forschungen von IBM beliefen sich die durchschnittlichen Kosten einer Datenpanne im Jahr 2024 auf 4,88 Millionen US-Dollar, was robuste Datensicherheitsmaßnahmen wichtiger denn je macht.
Apache Cloudberry, eine quelloffene MPP-Datenbank basierend auf PostgreSQL, erfordert umfassende Datenschutzstrategien, um sensible Daten während der Entwicklungs- und Testprozesse abzusichern. Organisationen können von Cloudberrys Architektur und Datenladefunktionen profitieren, während sie geeignete Maskierungstechniken implementieren.
Diese Anleitung bietet praktische Schritte zur Umsetzung von statischem Maskieren mit nativen Methoden und zeigt auf, wie DataSunrise den Datenschutz in Apache-Cloudberry-Umgebungen automatisiert und verbessert.
Verstehen von statischem Maskieren in Apache Cloudberry
Statisches Datenmaskieren erstellt eine bereinigte Datenbankkopie, indem sensible Daten dauerhaft durch realistische, aber fiktive Werte ersetzt werden. Im Gegensatz zum dynamischen Maskieren, das Daten in Echtzeit maskiert, transformiert das statische Maskieren die Daten physisch in einer separaten Datenbankinstanz.
Dieser Ansatz ist besonders wertvoll für die Entwicklung und das Testen mit realistischen Datensätzen, Analyseumgebungen, die eine Exposition von personenbezogenen Daten (PII) vermeiden müssen, Drittanbieterdatenfreigabe für Integrationstests und Schulungssysteme, die repräsentative Daten benötigen, ohne die Privatsphäre zu gefährden. Organisationen, die statisches Maskieren implementieren, sollten auch Strategien zum Testdatenmanagement berücksichtigen, um die Wirksamkeit zu maximieren.
Native statische Maskierung in Apache Cloudberry
Apache Cloudberry erbt die Datenmanipulationsfähigkeiten von PostgreSQL. Obwohl es keine integrierte Funktion für statisches Maskieren gibt, können Sie mit nativen PostgreSQL-Funktionalitäten effektive Maskierungen umsetzen. Organisationen sollten jedoch über mögliche Sicherheitsbedrohungen im Umgang mit sensiblen Daten in Nicht-Produktionsumgebungen informiert sein.
Voraussetzungen
Stellen Sie vor der Implementierung des statischen Maskierens sicher, dass eine laufende Apache-Cloudberry-Instanz mit administrativen Rechten vorhanden ist, eine separate Zieldatenbank für die maskierte Kopie besteht und grundlegende SQL-Kenntnisse vorliegen.
Schritt 1: Maskierungsfunktionen implementieren
Erstellen Sie benutzerdefinierte Maskierungsfunktionen für gängige Datentypen:
-- Maskiere E-Mail-Adressen
CREATE OR REPLACE FUNCTION mask_email(email TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN CASE WHEN email IS NULL THEN NULL
ELSE 'masked_' || md5(email)::text || '@example.com' END;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
-- Maskiere Kreditkartennummern (erhalte die ersten 4 und letzten 4 Ziffern)
CREATE OR REPLACE FUNCTION mask_credit_card(card_number TEXT)
RETURNS TEXT AS $$
BEGIN
RETURN CASE WHEN card_number IS NULL THEN NULL
ELSE substring(card_number from 1 for 4) ||
repeat('*', length(card_number) - 8) ||
substring(card_number from length(card_number) - 3) END;
END;
$$ LANGUAGE plpgsql IMMUTABLE;
Schritt 2: Daten kopieren und maskieren
-- Kopiere und maskiere Kundentabelle
INSERT INTO cloudberry_masked.customer_data (
customer_id, email, credit_card
)
SELECT
customer_id,
mask_email(email),
mask_credit_card(credit_card)
FROM cloudberry_production.customer_data;
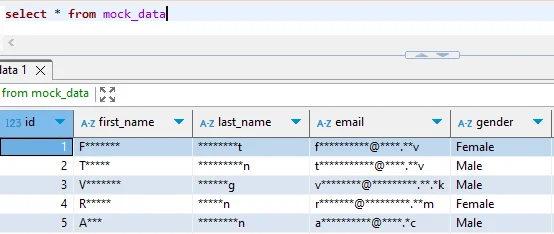
Schritt 3: Maskierte Daten überprüfen
-- Vergleiche Original- und maskierte Daten
SELECT customer_id, email FROM cloudberry_production.customer_data LIMIT 3;
SELECT customer_id, email FROM cloudberry_masked.customer_data LIMIT 3;
Beschränkungen des nativen Ansatzes
Der native Ansatz bringt für Organisationen mit erweiterten Anforderungen mehrere Herausforderungen mit sich. Der manuelle Prozess erfordert zeitintensive, individuelle SQL-Skripte für jede Tabelle, während das Fehlen einer automatischen Erkennung bedeutet, dass sensible Daten nicht automatisch über Schemas hinweg identifiziert werden können. Basis-Maskierungsfunktionen erfüllen möglicherweise nicht die Anforderungen von Compliance-Vorschriften, und ohne umfassende Audit-Trails fehlt es Organisationen an Nachverfolgbarkeit der Maskierungsvorgänge. Zudem kann die Performance bei großen Datenmengen, die über Cloudberrys MPP-Architektur verteilt sind, stark beeinträchtigt werden.
Erweitertes statisches Maskieren mit DataSunrise
DataSunrise bietet ein umfassendes Datenmaskieren, das die nativen Fähigkeiten von Apache Cloudberry wesentlich erweitert. Die Plattform implementiert Best Practices der Datenbanksicherheit und bietet fortschrittliche Funktionen zum Schutz sensibler Daten.
Wesentliche Vorteile
- Automatisierte Datenerkennung: Identifiziert sensible Daten gemäß den Frameworks GDPR, HIPAA und PCI DSS mithilfe fortgeschrittener Datenerkennungstechniken
- Vielfältige Maskierungsalgorithmen: Bietet verschiedene Maskierungsarten einschließlich Randomisierung, Substitution und formatwahrender Verschlüsselung
- No-Code In-Place Masking: Konfigurieren und Ausführen der Maskierung ohne komplexe SQL-Skripte
- Referentielle Integrität: Erhält automatisch Fremdschlüsselbeziehungen und Tabellenbeziehungen über maskierte Tabellen hinweg
- Umfassende Audit-Trails: Protokolliert alle Maskierungsvorgänge für Compliance-Anforderungen
- Plattformübergreifende Unterstützung: Einheitliche Richtlinienanwendung auf über 40 Datenbankplattformen
Implementierungsschritte mit DataSunrise
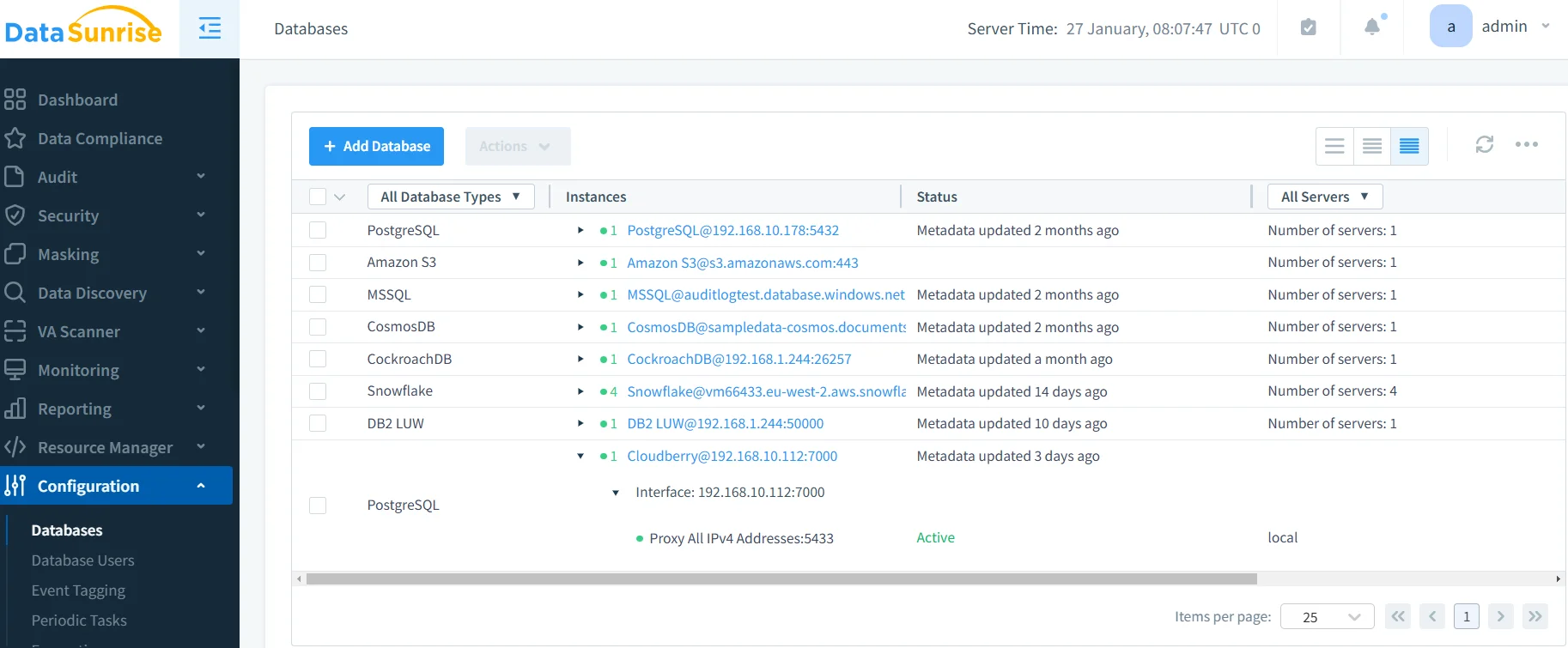
1. Verbindung zur Apache-Cloudberry-Instanz herstellen
Verbinden Sie Ihre Datenbank über die DataSunrise-Oberfläche mit Host, Port und Authentifizierungsdaten.
2. Sensible Daten erkennen
Navigieren Sie zum Modul zur Datenerkennung, wählen Sie Ihre Apache-Cloudberry-Instanz aus, wählen Sie regulatorische Vorlagen (GDPR, HIPAA, PCI DSS) und führen Sie einen Scan zur automatischen Identifikation sensibler Daten durch.
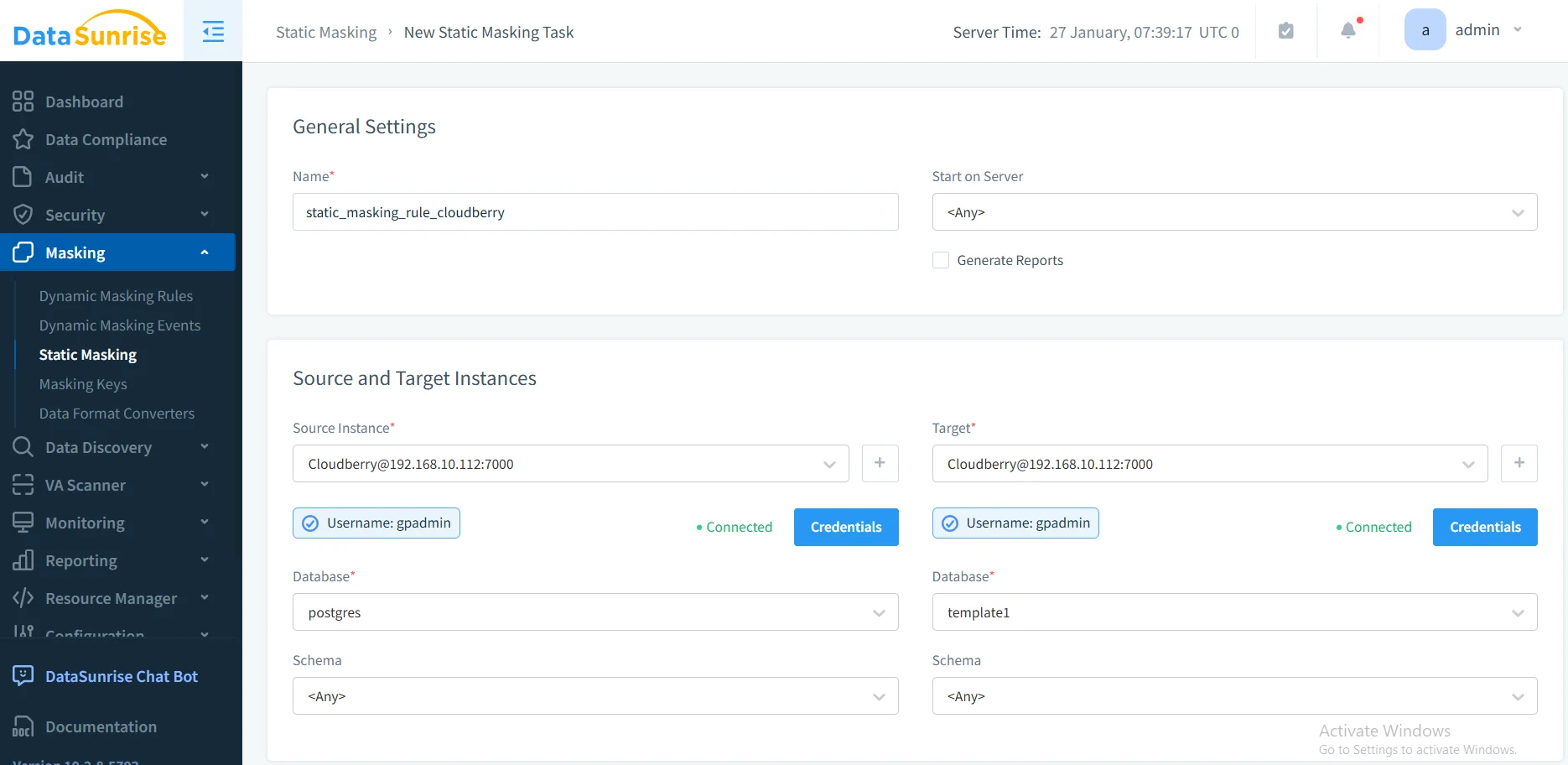
3. Maskierungsregeln konfigurieren
Wählen Sie Ihre Zieldatenbank oder Ihr Schema, wählen Sie passende Maskierungsalgorithmen für jeden Datentyp, konfigurieren Sie die Wahrung der referenziellen Integrität und legen Sie Optionen zur Konsistenz der Maskierung fest.
4. In-Place Maskierung ausführen
Wählen Sie Quell- und Zieldatenbanken aus, prüfen Sie den Maskierungsplan, führen Sie die Operation aus und überwachen Sie den Fortschritt in Echtzeit über das DataSunrise-Dashboard.
5. Ergebnisse überprüfen
DataSunrise stellt Validierungsberichte bereit, die maschinenmaskierte Datensätze, angewandte Algorithmen und Compliance-Abdeckungsmetriken anzeigen.
Best Practices für statisches Maskieren in Apache Cloudberry
| Bereich | Empfehlung |
|---|---|
| Datenklassifikation | Identifizieren Sie alle sensiblen Daten in Ihrem Cloudberry-Cluster; priorisieren Sie nach regulatorischen Anforderungen und Geschäftsauswirkungen; implementieren Sie angemessene Zugriffskontrollen und dokumentieren Sie Datenflüsse |
| Auswahl des Algorithmus | Verwenden Sie formatwahrende Maskierung für Anwendungs-Kompatibilität; wählen Sie deterministische Maskierung für Konsistenz oder zufällige für Sicherheit; stellen Sie sicher, dass Algorithmen regulatorische Anforderungen erfüllen, und erwägen Sie Datenbankverschlüsselung zum zusätzlichen Schutz |
| Leistungsoptimierung | Bearbeiten Sie große Tabellen in Batches; nutzen Sie Cloudberrys MPP-Architektur für parallele Ausführung; planen Sie Maskierung während Nebenzeiten, um Auswirkungen zu minimieren |
| Sicherheit & Compliance | Führen Sie detaillierte Protokolle der Maskierungsaktivitäten; beschränken Sie Zugriffe mit rollebasierter Zugriffskontrolle (RBAC); legen Sie regelmäßige Aktualisierungspläne fest; validieren Sie die Compliance durch automatisierte Berichterstattung |
Fazit
Während Apache Cloudberrys PostgreSQL-Grundlage grundlegende Transformationsfähigkeiten bietet, erfordern native Implementierungen erheblichen manuellen Aufwand und fehlen an Enterprise-Funktionen. DataSunrise bietet umfassendes Maskieren durch automatisierte Erkennung, intelligente Algorithmen und zentralisierte Richtlinienverwaltung.
Mit verschiedenen Bereitstellungsoptionen, die Cloud-, On-Premises- und Hybrid-Umgebungen unterstützen, bietet DataSunrise die nötige Flexibilität für moderne Datenarchitekturen.
Schützen Sie Ihre Daten mit DataSunrise
Sichern Sie Ihre Daten auf jeder Ebene mit DataSunrise. Erkennen Sie Bedrohungen in Echtzeit mit Activity Monitoring, Data Masking und Database Firewall. Erzwingen Sie die Einhaltung von Datenstandards, entdecken Sie sensible Daten und schützen Sie Workloads über 50+ unterstützte Cloud-, On-Premise- und KI-System-Datenquellen-Integrationen.
Beginnen Sie noch heute, Ihre kritischen Daten zu schützen
Demo anfordern Jetzt herunterladen