Outils de conformité des données NLP, LLM et ML pour Amazon OpenSearch
Les outils de conformité des données NLP, LLM & ML pour Amazon OpenSearch sont essentiels car OpenSearch n’est plus « juste une recherche » ou « juste des logs ». Dans les architectures modernes, il alimente l’observabilité, l’analyse de sécurité, et même les copilotes IA qui résument les incidents ou répondent aux questions sur les données télémétriques indexées. Dès que les données OpenSearch deviennent une source pour RAG, l’enrichissement des invites, ou l’extraction de caractéristiques ML, le risque de conformité augmente : les charges utiles non structurées peuvent contenir des identifiants, des secrets et des contextes réglementés qui sont désormais interrogeables à la vitesse de la machine.
AWS fournit la plateforme managée pour le service Amazon OpenSearch, mais la responsabilité d’identifier les données sensibles, de contrôler l’exposition et de produire des preuves d’audit revient à votre organisation. Ce guide montre où NLP/LLM/ML aident, où ils peuvent nuire, et comment DataSunrise permet la découverte automatisée, la gouvernance, l’audit, le masquage et la génération de rapports pour les environnements OpenSearch pilotés par l’IA.
Pourquoi les charges de travail IA augmentent la pression de conformité dans OpenSearch
Les défis classiques de conformité OpenSearch existent déjà : données semi-structurées, indices en évolution rapide, et accès étendus accordés pour la commodité. Les charges de travail IA amplifient ces problèmes car elles augmentent à la fois la portée des données et l’interprétation des données. Les pipelines NLP extraient des entités à partir de textes libres, les LLM résument le contenu (y compris des extraits sensibles), et les modèles ML détectent des schémas pouvant encoder indirectement des informations personnelles. Ce n’est pas théorique : un LLM répondant à « que s’est-il passé la nuit dernière ? » peut révéler involontairement des identifiants d’utilisateurs intégrés dans les logs.
C’est pourquoi la conformité sensible à l’IA doit s’aligner avec les réglementations de conformité des données et les cadres communs tels que le RGPD, les garanties techniques HIPAA, et le PCI DSS. En pratique, les régulateurs ne se soucient pas que les données soient dans une base, un index de logs, ou un cluster de recherche—si elles contiennent du contenu réglementé, elles doivent être gouvernées.
À quoi ressemble la « conformité prête pour l’IA » pour OpenSearch
Si OpenSearch alimente des systèmes NLP/LLM/ML, la conformité doit être continue et mesurable. Un programme pratique prêt pour l’IA se concentre sur cinq résultats :
- Connaître les données existantes : identifier continuellement les DPI et autres motifs sensibles à travers les indices et documents.
- Limiter ce à quoi l’IA peut accéder : appliquer des limites et périmètres d’accès pour éviter que « l’invite équivaut à un accès administrateur ».
- Réduire ce que l’IA peut révéler : masquer ou tokeniser les valeurs sensibles avant qu’elles n’atteignent les invites ou fenêtres contextuelles du modèle.
- Enregistrer les preuves : conserver des journaux et traces défendables qui indiquent qui a accédé à quoi et pourquoi.
- Automatiser les rapports : générer des packages de preuves reproductibles pour les audits et contrôles internes.
Comment NLP, LLM et ML soutiennent les contrôles de conformité
NLP pour la découverte des données sensibles non structurées
Les approches basées uniquement sur les expressions régulières échouent dans OpenSearch car les données les plus dangereuses sont souvent enfouies dans des logs en texte libre et des champs JSON imbriqués. Le NLP augmente la couverture en détectant les entités et le contexte dans les contenus non structurés. DataSunrise supporte la classification à grande échelle grâce à la découverte de données, aidant les équipes à localiser tôt les champs sensibles – avant que ces données ne soient ingérées dans les embeddings, invites, ou ensembles de données d’apprentissage.
LLM pour le contexte et l’explicabilité
Les LLM peuvent améliorer les flux de travail des analystes, mais ils introduisent aussi de nouvelles questions de conformité : quelles données le modèle a-t-il vues, qu’a-t-il résumé, et que produit-il ? La gouvernance avec LLM nécessite une application de politiques et une auditabilité des chemins d’accès – pas une confiance aveugle au niveau applicatif. C’est là que l’orchestration politique centralisée devient critique.
ML pour l’analyse comportementale et la détection d’anomalies
Le ML est bien adapté pour détecter les comportements de requête anormaux : rafales de recherches à haute cardinalité, accès répétés à des indices sensibles, ou schémas de récupération inhabituels compatibles avec du scraping. DataSunrise renforce cela avec une analyse du comportement utilisateur, permettant aux équipes d’identifier des usages suspects que les contrôles traditionnels autoriser/interdire pourraient manquer.
Architecture de référence : couche de conformité consciente de l’IA pour OpenSearch
Le modèle le plus sûr est d’appliquer la conformité proche de la couche d’accès OpenSearch afin que la découverte, les politiques, et les preuves d’audit soient cohérentes à travers les outils — tableaux de bord, API, et agents IA. DataSunrise fournit une couche centralisée de conformité pour la gouvernance et la collecte de preuves sans nécessiter de refonte des index.
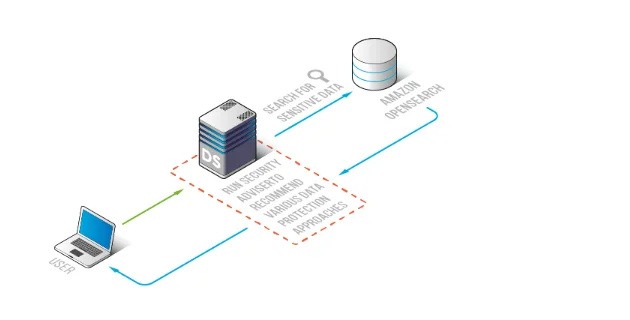
Cartographie des contrôles : Où s’insèrent les outils de conformité dans un pipeline NLP/LLM/ML
| Étape IA | Risque OpenSearch | Contrôle de conformité | Résultat |
|---|---|---|---|
| Ingestion | Champs sensibles indexés dans des documents recherchables | Découverte + définition du périmètre | Inventaire connu et objets gouvernés |
| Récupération (RAG) | Les invites extraient des identifiants bruts dans le contexte | Masquage + moindre privilège | Exposition réduite dans le contexte LLM |
| Analyse | Accès large pour tableaux de bord et enquêtes | Contrôles d’accès centralisés + journalisation d’audit | Traçabilité et responsabilité |
| Entraînement de modèle | Ensembles de données d’entraînement contenant des données réglementées | Masquage statique ou données synthétiques | Jeux de données sûrs pour le réglage ML/LLM |
| Opérations | Dérive : nouveaux indices/pipelines apparaissent silencieusement | Surveillance continue + reporting | Les contrôles restent à jour dans le temps |
Outils DataSunrise pour automatiser la conformité OpenSearch
1) Gestion de la conformité pilotée par les politiques
Pour étendre la gouvernance, les politiques doivent être définies centralement et appliquées uniformément. DataSunrise propose des workflows politiques via Compliance Manager, permettant aux équipes de standardiser les règles dans tous les environnements. Associez les politiques avec RBAC et des contrôles d’accès centralisés pour que les outils IA et les utilisateurs n’obtiennent que l’accès requis par leur rôle.
2) Sélection du périmètre pour les objets sensibles OpenSearch
Les outils de conformité doivent être précis : gouverner les indices sensibles sans perturber les analyses à faible risque. DataSunrise supporte le découpage au niveau des objets afin que les politiques s’appliquent uniquement là où c’est nécessaire – particulièrement important quand le même cluster OpenSearch dessert à la fois des tableaux de bord opérationnels et des workflows IA.
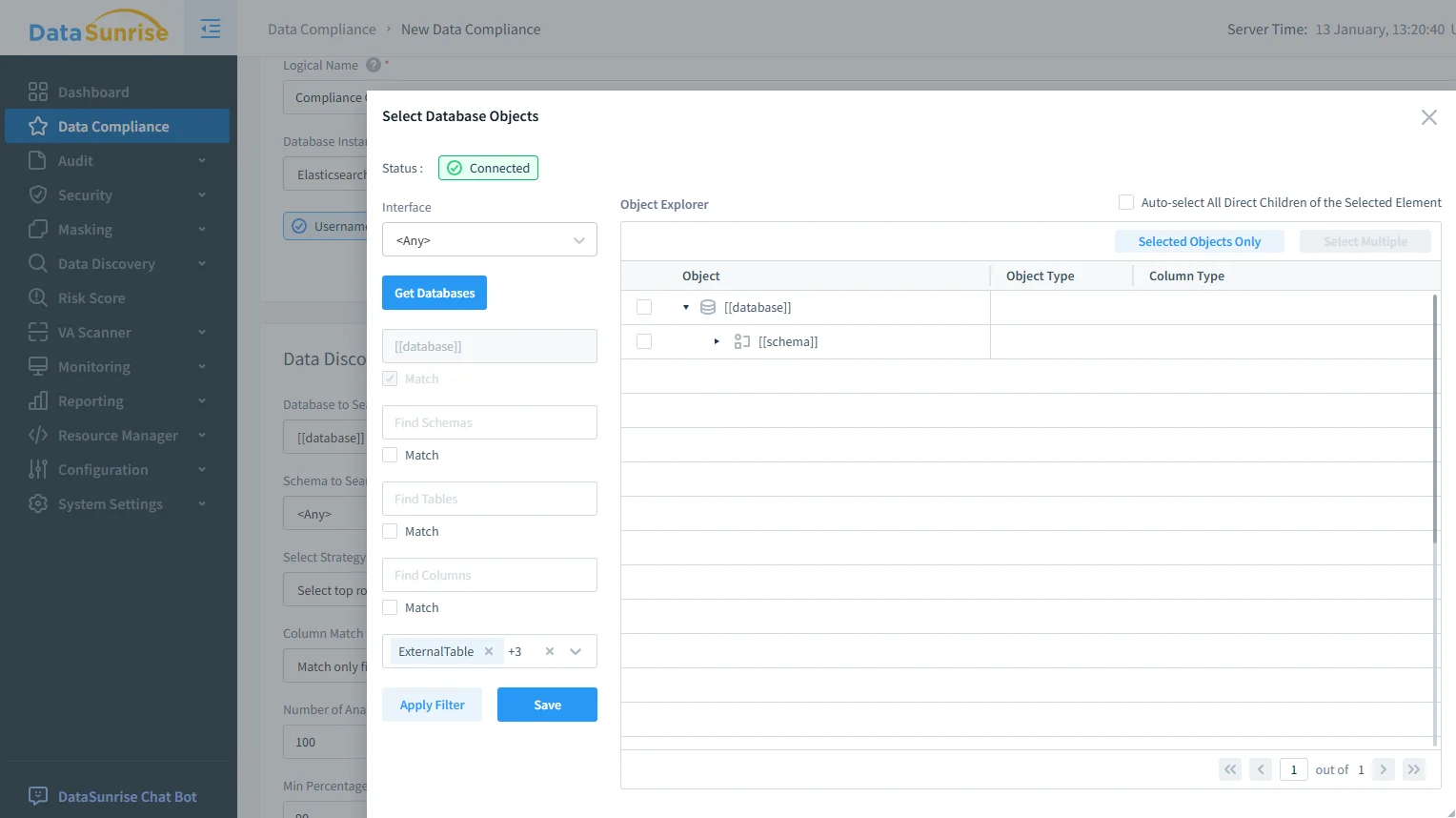
Sélection de périmètre pour la conformité OpenSearch : choisissez les objets gouvernés pour que les workflows IA ne touchent qu’aux indices et champs approuvés.
3) Audit et preuves pour l’accès piloté par l’IA
L’IA augmente le nombre de chemins d’accès (tableaux de bord, API, agents), donc les preuves d’audit doivent être centralisées. DataSunrise prend en charge des journaux d’audit détaillés via Data Audit, et préserve une traçabilité de qualité investigatoire avec des traces d’audit. Pour la supervision en temps réel, la surveillance des activités de base de données aide à détecter tôt les comportements de requêtes à risques.
Pour des recommandations de journalisation de service de base, AWS documente la journalisation d’audit OpenSearch ici : journaux d’audit Amazon OpenSearch. Dans les environnements fortement IA, les preuves centralisées sont généralement plus faciles à défendre que des journaux dispersés sur plusieurs couches.
4) Masquage et sécurité des jeux de données pour les pipelines ML/LLM
La plupart des charges de travail IA ne nécessitent pas d’identifiants bruts. DataSunrise réduit l’exposition grâce au masquage dynamique des données pour la protection à la requête et au masquage statique des données pour des extraits plus sûrs et des pipelines non productifs. Lorsque l’entraînement ou les tests nécessitent une structure réaliste sans identités réelles, la génération de données synthétiques aide à garder l’expérimentation IA conforme.
5) Contrôles de sécurité préventifs et validation de posture
Les agents IA peuvent involontairement amplifier les abus (par exemple, « chercher tout pour X »). Les contrôles préventifs aident à limiter le rayon d’impact. Utilisez des règles de pare-feu de base de données pour bloquer les modèles abusifs et une évaluation des vulnérabilités pour identifier la dérive et les mauvaises configurations qui peuvent compromettre la conformité.
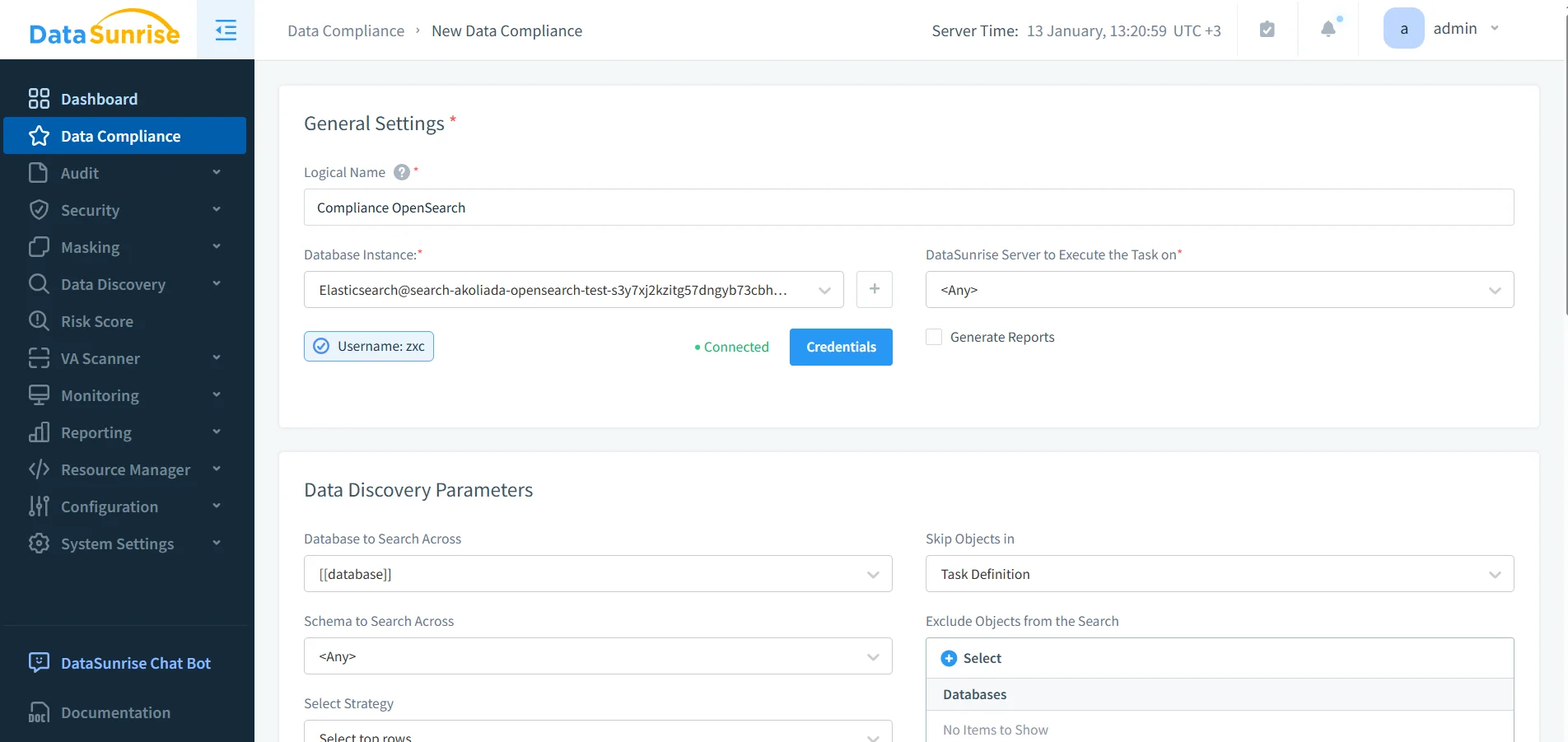
Configuration des règles de conformité : automatisez les actions de gouvernance (audit, masquage, reporting) pour les workflows OpenSearch assistés par IA.
Reporting automatisé pour la conformité NLP, LLM et ML
Les auditeurs ne veulent pas de captures d’écran ; ils veulent des preuves répétables. DataSunrise prend en charge la génération de rapports automatisés avec la génération de rapports et le reporting de conformité automatisé. Dans les environnements fortement IA, l’automatisation fait la différence entre « nous pensons être conformes » et « voici le paquet de preuves ».
Pour maintenir la conformité malgré les changements d’indices et pipelines, alignez les contrôles avec la protection continue des données pour que la découverte, les politiques, et les preuves restent à jour.
Conclusion
Les outils de conformité des données NLP, LLM & ML pour Amazon OpenSearch fonctionnent mieux lorsqu’ils ne sont pas des « ajouts » isolés, mais font partie d’un plan de contrôle : découvrir les données sensibles continuellement, définir précisément les accès, réduire l’exposition via le masquage, surveiller les anomalies, et générer automatiquement des preuves prêtes pour l’audit. DataSunrise fournit un ensemble intégré de contrôles pour gouverner à grande échelle les charges de travail OpenSearch pilotées par IA.
Pour planifier le déploiement, consultez la présentation de DataSunrise et les modes de déploiement disponibles, puis démarrez avec le téléchargement ou demandez une démonstration guidée.
