
pgvector : Protéger les données contre l’exposition via les embeddings vectoriels

Le risque caché des embeddings vectoriels
Les embeddings vectoriels alimentent les applications d’IA générative, en permettant la recherche sémantique, les systèmes de recommandation et les analyses pilotées par l’IA. Dans PostgreSQL, l’extension pgvector rend possible le stockage et l’interrogation efficace des embeddings en haute dimension, améliorant ainsi les applications d’IA grâce à une recherche de similarité rapide. Mais bien qu’ils ne soient, après l’embedding, que des chiffres, ils peuvent tout de même divulguer des données sensibles.
Les embeddings vectoriels peuvent-ils réellement exposer des informations sensibles ?
Les embeddings vectoriels fonctionnent comme des coordonnées dans un espace multidimensionnel – ils ne contiennent pas directement de données sensibles, mais ils peuvent être exploités pour reconstruire des motifs. Protéger les informations sensibles signifie contrôler ce qui est intégré dans les embeddings et surveiller la manière dont ils sont interrogés.
Si les embeddings sont générés à partir de texte brut contenant des informations personnellement identifiables (IPI) telles que des noms, des numéros de sécurité sociale ou des adresses, le modèle peut encoder des motifs qui exposent indirectement ces informations. Des attaquants peuvent exploiter les recherches de voisins les plus proches pour reconstruire des données sensibles, conduisant à des violations de conformité et à des menaces en matière de sécurité.
Alors, les embeddings vectoriels peuvent-ils réellement exposer des informations sensibles ? Oui — des données sensibles peuvent être exposées via les embeddings dans certaines circonstances. Et, bien que les embeddings ne stockent pas de données brutes, la manière dont ils encodent les relations entre les points de données signifie que des informations sensibles pourraient être déduites lors d’interrogations astucieuses. Selon la façon dont les embeddings sont générés et les informations utilisées pour les créer, voici comment cela peut se produire :
🔍 Comment les données sensibles peuvent être exposées dans les embeddings
1. Encodage direct
- Si les embeddings sont créés à partir d’un texte brut contenant des informations sensibles (par exemple, numéros de sécurité sociale, noms ou adresses), le modèle peut encoder des motifs qui les révèlent indirectement.
➡️Exemple : Si SSN: 123-45-6789 fait partie du profil d’un employé utilisé pour la génération d’embeddings, un modèle peut générer des embeddings qui, lorsqu’ils sont interrogés de manière spécifique, pourraient renvoyer des vecteurs ressemblant ou corrélés à des motifs de données sensibles.
2. Corrélation implicite des données
- Si les embeddings sont entraînés sur des données structurées (par exemple, les rôles, salaires et départements des employés), des motifs dans ces données pourraient être corrélés avec des IPI.
➡️Exemple : Si le numéro de sécurité sociale d’un employé est utilisé lors de l’entraînement vectoriel avec le salaire et le département, un système d’IA pourrait dévoiler des détails sur le salaire lors de la recherche d’embeddings similaires.
3. Mémorisation par les modèles d’IA
- Si un modèle d’IA entraîné sur des données sensibles génère des embeddings, il peut mémoriser et régurgiter des détails spécifiques lorsqu’on le sollicite de manière astucieuse.
➡️Exemple : Si les embeddings stockent les noms et rôles des employés, un modèle pourrait récupérer des vecteurs similaires contenant des informations personnelles lorsqu’on lui demande « employés du secteur financier gagnant plus de 100K $. »
4. Risques de reconstruction
- Dans certains cas, les embeddings peuvent être rétroconçus à l’aide d’attaques adversariales, reconstruisant ainsi des parties des données originales.
➡️Exemple : Si un attaquant interroge le système avec des motifs d’entrée spécifiques, il pourrait extraire des données significatives à partir des embeddings.
🔓 Comment les données sensibles peuvent être exposées à partir de embeddings
Les attaquants ou des requêtes non intentionnelles peuvent exposer des IPI par le biais de :
- Recherches de voisins les plus proches – Trouver des embeddings proches des motifs de données sensibles.
- Regroupement vectoriel – Regrouper des embeddings similaires pour déduire des détails personnels connexes.
- Injection de requêtes – Tromper le système afin qu’il révèle le contenu sensible stocké.
- Attaques adversariales – Exploiter des failles du modèle pour reconstruire les données d’entrée originales.
Résumé
Oui, des données sensibles peuvent fuir dans les embeddings si ceux-ci sont générés sans mesures de protection appropriées. Si un système d’IA utilise des embeddings créés à partir de données sensibles brutes, il peut restituer des informations similaires lorsqu’il est interrogé de manière astucieuse.
Bonnes pratiques : N’intégrez jamais des champs sensibles bruts, et nettoyez toujours les données avant la vectorisation.
Techniques pour prévenir les fuites d’IPI via les embeddings vectoriels
1. Assainissement des données avant la génération des embeddings
Avant de convertir les données en embeddings vectoriels, supprimez ou transformez les informations sensibles afin qu’elles n’entrent jamais dans l’espace vectoriel.
Supprimer les champs IPI – Évitez d’intégrer des données brutes comme les numéros de sécurité sociale, les noms et les adresses.
Généraliser les données – Au lieu de stocker des salaires exacts, catégorisez-les par tranches.
Tokenisation – Remplacez les données sensibles par des identifiants non réversibles.
Exemple : Plutôt que d’intégrer :
“John Doe, SSN: 123-45-6789, gagne 120 000 $”
Stocker : “Employé X, gagne entre 100K $ et 150K $”
Cela garantit que les IPI n’entrent jamais dans le magasin vectoriel dès le départ.
2. Masquage des données sensibles dans les requêtes et les réponses
Même si des IPI brutes ont été intégrées ou si les embeddings encodent des motifs liés aux IPI, vous pouvez toujours masquer ou obscurcir les données sensibles lors de la récupération.
Masquage dynamique des données – Rédigez ou transformez la sortie sensible avant qu’elle n’atteigne les utilisateurs.
Filtrage en temps réel des requêtes – Bloquez les recherches de similarités non autorisées sur les embeddings.
Contrôle d’accès et restrictions basées sur les rôles – Limitez l’accès à la recherche vectorielle aux utilisateurs de confiance.
Exemple : Si un utilisateur interroge les embeddings et récupère un morceau de données contenant des IPI :
Sortie originale : “Le salaire de John Doe est de 120 000 $”
Sortie masquée : “Le salaire de l’employé X est de 1XX 000 $”
Cela empêche l’exposition non intentionnelle d’informations sensibles.
Approches proactives vs réactives pour la sécurité des données dans les embeddings vectoriels
1️⃣ Sécurité proactive – Appliquer la protection des IPI avant l’embedding
Cette approche garantit que les données sensibles n’entrent jamais dans l’embedding dès le départ.
Comment ?
Assainir les données structurées avant la vectorisation. ✅
Masquer les informations sensibles avant l’embedding. ✅
Utiliser la tokenisation pour remplacer les valeurs identifiables. ✅
Appliquer des techniques de confidentialité différentielle pour introduire du bruit. ✅
Bénéfice : Cette approche élimine les risques à la source, rendant impossible que les requêtes sur les embeddings révèlent des IPI.
2️⃣ Sécurité réactive – Audit et masquage après l’embedding
Cette approche part du principe que les embeddings contiennent déjà des références à des informations sensibles et se concentre sur la détection et le masquage des IPI lors de la récupération.
Comment ?
Identifier les informations sensibles utilisées lors de la création des embeddings. ✅
Appliquer un masquage en temps réel avant d’afficher les données récupérées. ✅
Restreindre les requêtes non autorisées qui accèdent aux embeddings sensibles. ✅
Surveiller les recherches de similarité vectorielle pour détecter les schémas d’accès anormaux. ✅
Bénéfice : Même si des informations sensibles existent déjà dans les embeddings, cette méthode garantit qu’elles ne sont jamais exposées lors de la récupération.
🎯 La meilleure stratégie de sécurité ? – Utiliser les DEUX
La sécurité la plus robuste provient de la combinaison des deux méthodes :
- Proactif – L’assainissement empêche l’ intégration de données sensibles.
- Réactif – La surveillance garantit que les embeddings existants ne fuient pas d’IPI.
Comment DataSunrise sécurise les données derrière l’embedding vectoriel
DataSunrise propose une solution de sécurité complète pour protéger les données référencées par les embeddings pgvector avant et après leur création.
🛡️ Protection proactive : Sécuriser les données sources avant l’embedding
Pour les organisations qui traitent d’énormes quantités de données structurées et non structurées, DataSunrise aide en :
- Détectant les IPI avant qu’elles ne fassent partie d’un embedding.
- Masquant les données sensibles avant la vectorisation.
- Utilisant des techniques d’anonymisation des données pour supprimer certains détails personnels
Exemple : Avant d’intégrer des profils clients, DataSunrise peut analyser le stockage des données à la recherche d’informations sensibles, supprimer les numéros de sécurité sociale, anonymiser les adresses et généraliser les données financières, garantissant ainsi que la représentation vectorisée ne contient aucun détail privé.

🛡️ Protection réactive : Sécuriser les données sources avec des embeddings existants et des applications d’IA
Si une application d’IA fonctionne déjà avec des embeddings contenant des références à des données sensibles, DataSunrise offre :
- La découverte des données sensibles pour les données utilisées lors de la création des embeddings.
- Le masquage dynamique des résultats des requêtes sensibles.
- L’audit en temps réel pour détecter les recherches de similarité vectorielle non autorisées.
Exemple : Si un attaquant tente d’interroger les embeddings pour accéder à des données pouvant contenir des IPI, DataSunrise suit et surveille ces tentatives et masque les informations sensibles avant qu’elles ne soient exposées.
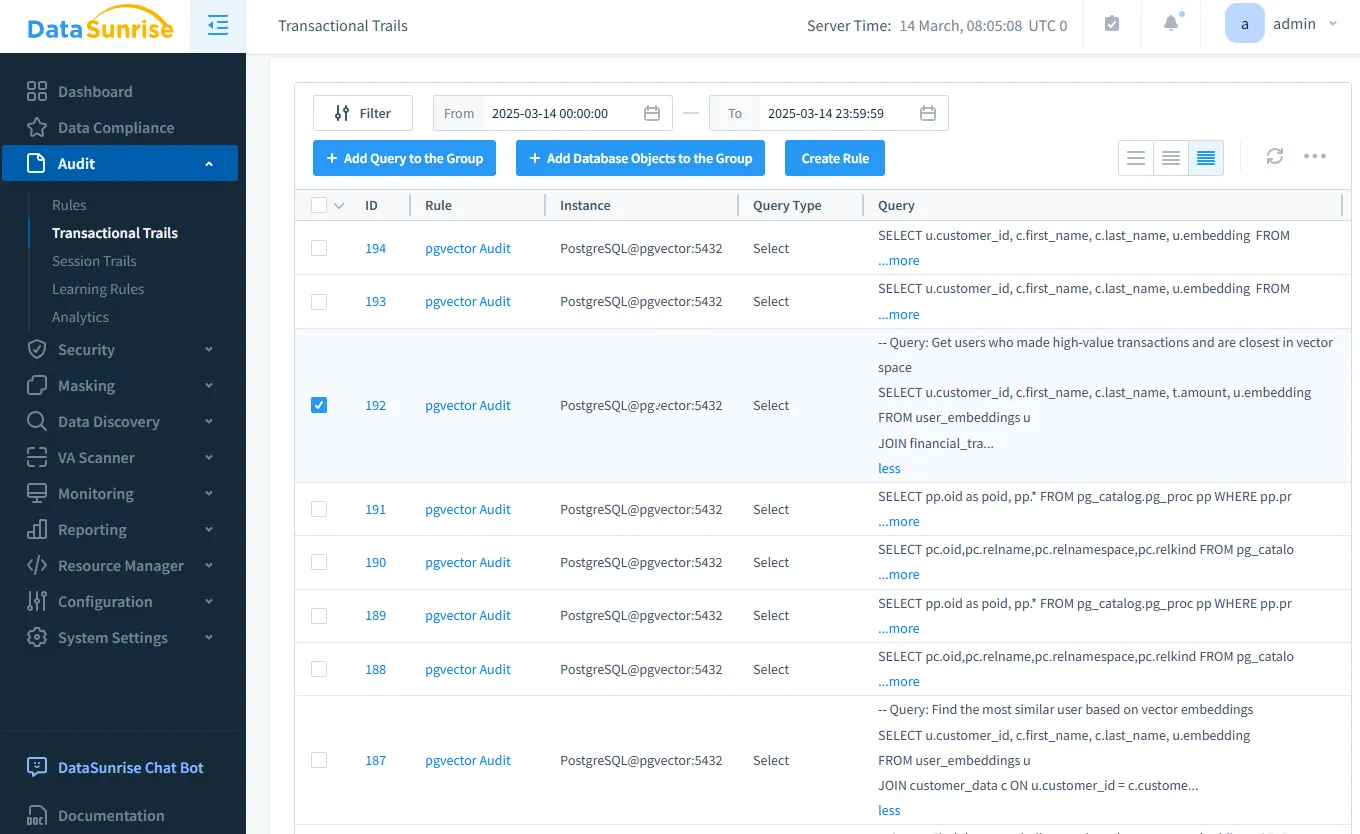
Le tableau ci-dessous illustre l’approche globale de DataSunrise pour sécuriser les embeddings vectoriels, en abordant à la fois la prévention et la détection de l’exposition des données sensibles :
| Fonctionnalité | Protection proactive | Protection réactive |
|---|---|---|
| Découverte de données | Identifie les données sensibles avant l’embedding | Analyse les sources d’embedding pour détecter une potentielle exposition d’IPI |
| Audit des données | Enregistre la génération des embeddings | Détecte les requêtes suspectes |
| Sécurité des données | Empêche les IPI d’être intégrées dans les embeddings | Bloque les recherches vectorielles non autorisées |
| Masquage des données | Cache les données sensibles avant l’embedding | Masque les informations sensibles lors de la récupération |
Conclusion : Une approche à double niveau pour la sécurité
Les embeddings vectoriels dans pgvector sont puissants, mais ils peuvent exposer des données sensibles s’ils ne sont pas gérés correctement. La meilleure approche est de combiner des techniques de sécurité proactives et réactives afin de minimiser les risques.
🔹 Avant la création des embeddings – Assainir, masquer et contrôler l’accès aux données.
🔹 Après l’existence des embeddings – Auditer, surveiller et masquer les IPI dans les réponses de l’IA générative.
Pour sécuriser les embeddings vectoriels dans PostgreSQL avec pgvector, les organisations devraient :
- ✅ Utiliser des mesures proactives afin d’empêcher l’entrée d’IPI dans les embeddings.
- ✅ Mettre en place une sécurité réactive pour surveiller et masquer les informations récupérées.
- 🛡️ Tirer parti de DataSunrise pour détecter, protéger et empêcher l’exposition des données sensibles à chaque étape.
DataSunrise permet d’utiliser les deux stratégies, garantissant que les applications propulsées par l’IA restent sécurisées et conformes. Que vous construisiez un nouveau système d’IA ou que vous sécurisiez un système existant, DataSunrise offre une protection de bout en bout pour les données vectorisées sensibles.
En intégrant les Fonctionnalités de Sécurité de DataSunrise, les entreprises peuvent utiliser leurs données pour les embeddings vectoriels sans risquer de violer la confidentialité des données.
Besoin de sécuriser vos données d’embeddings vectoriels ? Planifiez une démonstration DataSunrise dès aujourd’hui pour protéger vos applications d’IA générative !
