
Statisches Datenmaskieren für Apache Hive

Einführung
Apache Hive, ein Open-Source Data Warehouse-System, das auf Apache Hadoop aufbaut, bietet eine SQL-ähnliche Schnittstelle namens HiveQL zur Verwaltung und Analyse großer Datensätze. Beim Umgang mit sensiblen Daten in Hive-Umgebungen benötigen Organisationen häufig robuste Sicherheitsmaßnahmen wie Datenmaskierung und verschiedene Maskierungstechniken, um die Einhaltung der Datenschutzvorschriften zu gewährleisten. Statisches Datenmaskieren für Apache Hive stellt einen besonders effektiven Ansatz dar, indem anonymisierte Kopien von Produktionsdaten für Entwicklungs- und Testzwecke erstellt werden, wobei die Nützlichkeit der Daten und die referenzielle Integrität erhalten bleiben. Dieser Artikel wird verschiedene statische Maskierungsoptionen in Hive untersuchen.
Was ist statisches Datenmaskieren?
Statisches Datenmaskieren erstellt eine bereinigte Kopie Ihres Data Warehouses. Es ersetzt sensible Informationen durch fiktive, aber realistische Daten, sodass Organisationen maskierte Daten in Nicht-Produktionsumgebungen verwenden können, ohne die Offenlegung vertraulicher Informationen zu riskieren.
Implementierung von statischem Datenmaskieren für Apache Hive mit nativen Funktionen
Apache Hive bietet mehrere integrierte Funktionen zum grundlegenden Datenschutz, die für einfache Anwendungsfälle recht effektiv sein können. Diese nativen Funktionen ermöglichen es Organisationen, effektives Datenmanagement zu betreiben, indem sie maskierte Kopien ihrer Data Warehouses für Test- und Entwicklungszwecke erstellen.
Verwendung von Hives integrierten Funktionen
Hive bietet mehrere integrierte Funktionen, die kombiniert werden können, um effektive Maskierungsstrategien zu erstellen. Hier ist ein praktisches Beispiel, das gängige Maskierungsmuster zeigt:
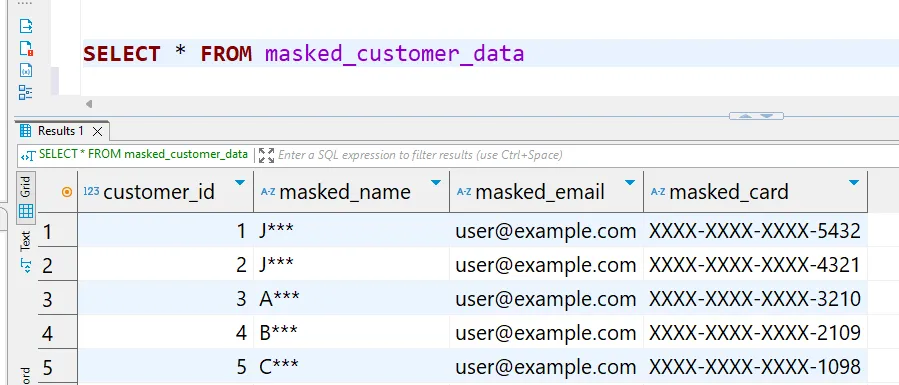
CREATE TABLE masked_customer_data AS
SELECT
customer_id,
CONCAT(SUBSTR(name, 1, 1), '***') as masked_name,
REGEXP_REPLACE(email, '(.*)@(.*)', '[email protected]') as masked_email,
CONCAT('XXXX-XXXX-XXXX-', SUBSTR(credit_card, -4)) as masked_card
FROM customer_data;
Die maskierte Tabelle enthält anonymisierte, aber realistisch aussehende Daten, die die referenzielle Integrität bewahren und gleichzeitig sensible Informationen schützen.
Erstellen geschützter Ansichten
Für komplexere Maskierungsanforderungen können Sie geschützte statische Kopien mittels Ansichten erstellen. Diese Methode ist besonders nützlich, wenn Sie unterschiedliche Maskierungsstufen für verschiedene Arten sensibler Informationen benötigen:
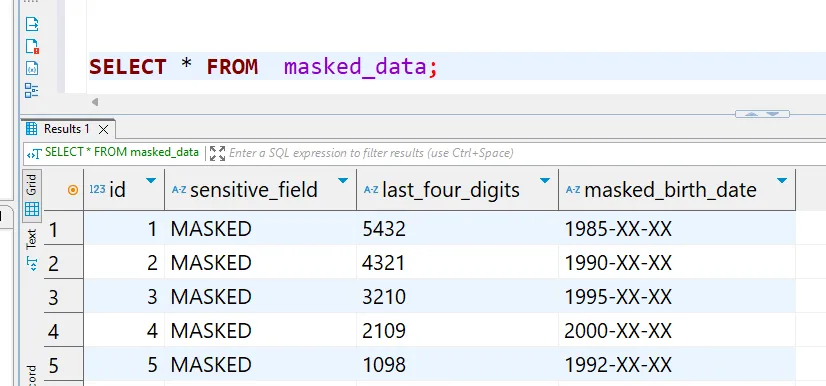
CREATE TABLE masked_data AS
SELECT
id,
-- Ersetze das gesamte Feld durch einen statischen Wert
'MASKED' as sensitive_field,
-- Teile der Daten bei Bedarf beibehalten
SUBSTR(account_number, -4) as last_four_digits,
-- Daten maskieren und das Jahr beibehalten
CONCAT(YEAR(birth_date), '-XX-XX') as masked_birth_date
FROM source_table;
Beispielausgabe bei SELECT * Abfrage:
Diese Maskierungstechniken bieten eine solide Grundlage zum Schutz sensibler Daten in Entwicklungs- und Testumgebungen, während die Nutzbarkeit der Daten für Nicht-Produktionsanwendungen erhalten bleibt. Die maskierten Kopien bewahren die ursprüngliche Datenstruktur und die Beziehungen, was sie für Anwendungstests und Entwicklungsarbeiten geeignet macht.
Praktische Tipps für die Hive-Maskierung
1. Konsistente Maskierung: Verwenden Sie für Felder wie E-Mail-Adressen, die in mehreren Tabellen erscheinen, überall die gleiche Maskierungsfunktion, um Konsistenz zu gewährleisten.
2. Leistung beachten: Erstellen Sie maskierte Tabellen anstelle von Ansichten, wenn sich die Daten nicht häufig ändern. Dieser Ansatz:
- Verringert die Verarbeitungszeit
- Verbessert die Abfrageleistung
- Stellt die maskierten Daten sofort zur Verfügung
3. Datenformat beibehalten: Beachten Sie, wie unsere Maskierung das ursprüngliche Datenformat beibehält:
- Kreditkarten behalten das Format XXXX-XXXX-XXXX-1234
- E-Mails bleiben gültig aussehend mit ‘@domain.com’
- Namen behalten eine lesbare Struktur
Bedenken Sie, dass diese nativen Funktionen zwar für grundlegende Maskierungsanforderungen nützlich sind, Unternehmensumgebungen jedoch oft anspruchsvollere Lösungen benötigen, die zusätzliche Funktionen wie Datenerkennung, konsistente Maskierung über Datenbanken hinweg und erweiterte Verschlüsselungsoptionen bieten.
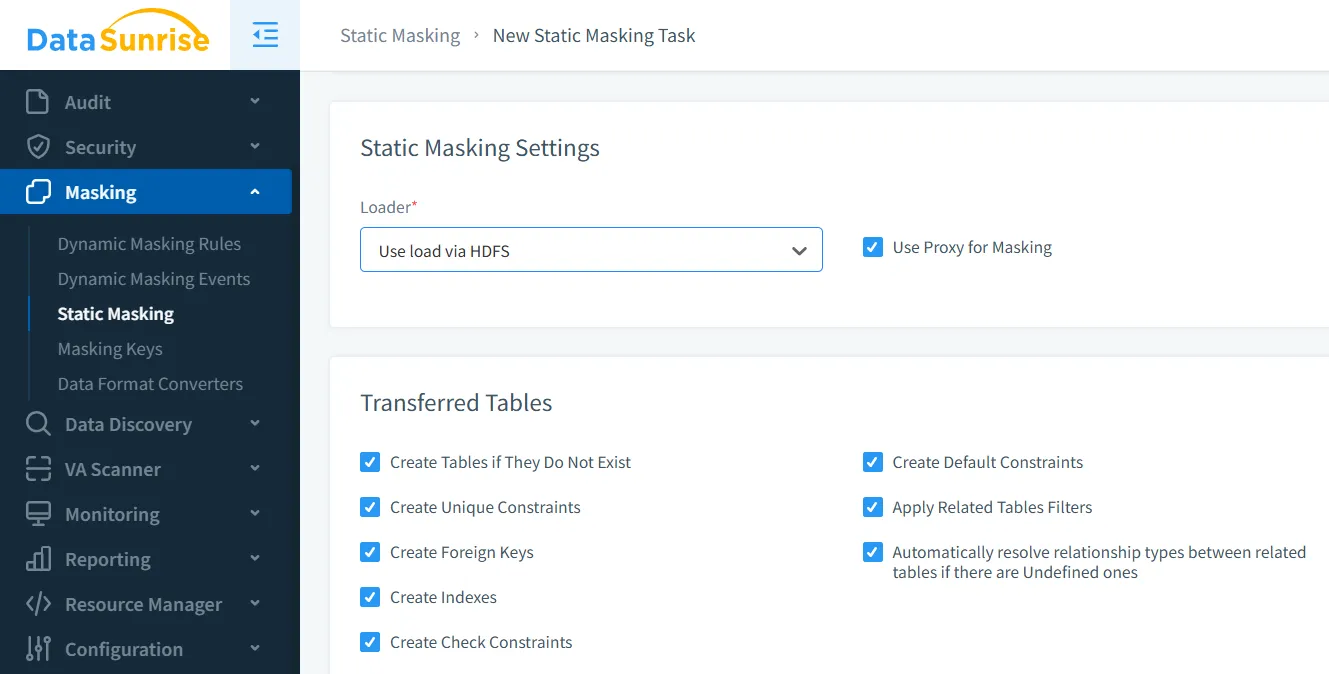
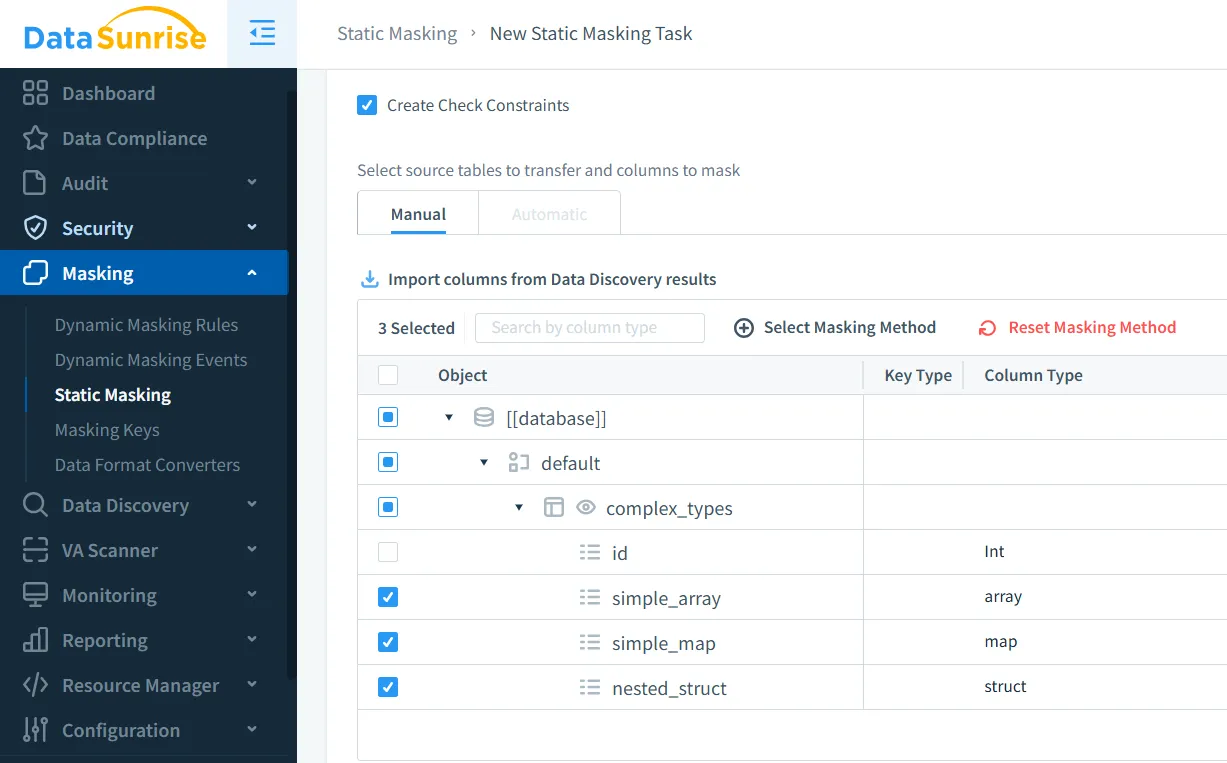
Erweitertes statisches Datenmaskieren für Apache Hive mit DataSunrise
DataSunrise glänzt beim statischen Datenmaskieren durch eine umfangreichere und komfortablere Lösung. Mit verschiedenen Maskierungstypen, einschließlich dynamischen Maskierens und statischen Optionen, können Sie eine Kopie der Daten erstellen, bei der sensible Informationen maskiert sind, aber der Datenwert und die ursprüngliche Struktur erhalten bleiben, was sie ideal für Anwendungen wie Testen, Entwicklung und Compliance macht.
Statisches Datenmaskieren für Apache Hive und andere Datenbanken in DataSunrise bietet:
- Datenintegrität und Konsistenz: Bewahrt die ursprüngliche Datenstruktur zum Testen und Analysieren und erhält Datenbeziehungen über verwandte Tabellen hinweg durch konsistente Maskierung sensibler Informationen.
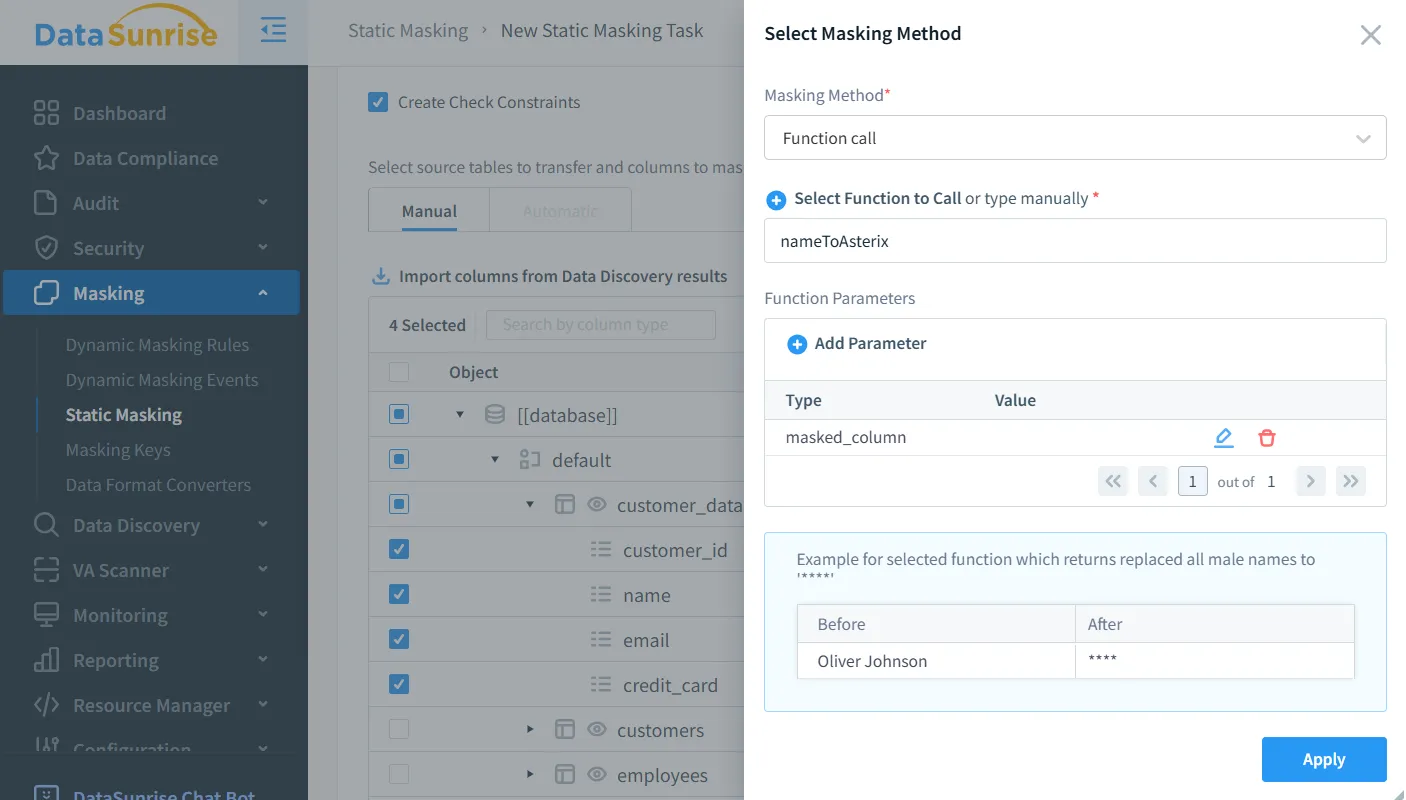
Anpassbare Algorithmen: Bietet eine umfangreiche Bibliothek vorgefertigter Maskierungsvorlagen sowie die Möglichkeit, benutzerdefinierte Maskierungslogik durch benutzerdefinierte Funktionen und Lua-Skripte zu erstellen. Dieser Ansatz ermöglicht es Organisationen, sowohl standardisierte als auch hochspezialisierte Datenanonymisierungsregeln zu implementieren.
Unterstützung komplexer Datentypen und Tabellenformate: Bewältigt Hive-spezifische Datenstrukturen umfassend – von einfachen ARRAYS und MAPS bis hin zu tief verschachtelten Kombinationen aus komplexen Typen, wobei Datenbeziehungen und Strukturintegrität während der Maskierungsoperationen erhalten bleiben.
Fazit
Statisches Datenmaskieren für Apache Hive ist ein entscheidendes Werkzeug zum Schutz sensibler Daten und zur Sicherstellung der Regelkonformität in Big Data-Umgebungen. Unabhängig davon, ob Hives integrierte Funktionen oder umfassende Lösungen wie DataSunrise verwendet werden, können Organisationen vertrauliche Informationen effektiv schützen und gleichzeitig die Daten für Entwicklungs- und Testzwecke nutzbar halten.
DataSunrise bietet benutzerfreundliche und flexible Werkzeuge für umfassende Datenbanksicherheit, einschließlich Prüfungs-, Maskierungs- und Datenerkennungsfunktionen. Um mehr darüber zu erfahren, wie DataSunrise Ihren Hive-Datenschutz verbessern kann, besuchen Sie unsere Website für eine Online-Demo und entdecken Sie unser vollständiges Sortiment an Sicherheitslösungen.
