Anonymizzazione dei Dati in Percona Server per MySQL
L’anonymizzazione dei dati in Percona Server per MySQL non è una funzione di sicurezza cosmetica. È un controllo strutturale utilizzato quando i dati reali di produzione devono essere condivisi al di fuori del loro confine di fiducia originale senza esporre identità, credenziali o attributi regolamentati. In pratica, l’anonymizzazione riduce i rischi di esposizione a lungo termine e supporta direttamente strategie più ampie di sicurezza dei dati.
A differenza dell’auditing o del tracciamento delle attività, l’anonymizzazione modifica i dati stessi. L’obiettivo è rimuovere permanentemente la capacità di identificare gli individui mantenendo però sufficiente struttura per test, analisi e workflow di sviluppo. Questo approccio è particolarmente importante quando si trattano informazioni personali identificabili (PII) e altre categorie di dati regolamentati.
Questo articolo spiega come funziona l’anonymizzazione in Percona Server per MySQL utilizzando tecniche SQL native, dove questi metodi mostrano limiti e come le piattaforme centralizzate estendono l’anonymizzazione in un processo governato e ripetibile allineato con regolamenti per la conformità dei dati e requisiti di sicurezza.
Cosa Significa Anonymizzazione dei Dati nel Contesto MySQL
L’anonymizzazione dei dati è una trasformazione irreversibile di valori sensibili in modo che i soggetti dei dati non possano essere ri-identificati, neppure dagli amministratori. Una volta applicati, i dati anonimizzati solitamente escono dall’ambito dei regolamenti per la conformità dei dati e riducono significativamente i rischi a lungo termine per la sicurezza dei dati.
Nei sistemi basati su MySQL, l’anonymizzazione si utilizza quando i dati di produzione sono riutilizzati per test, analisi o archiviazione al di fuori di ambienti controllati. Viene comunemente applicata a identificativi personali, attributi finanziari e dati comportamentali o legati alla localizzazione, soprattutto in workflow non di produzione e in scenari di gestione dei dati di test.
A differenza del monitoraggio delle attività del database o dei controlli di accesso basati sul principio del minimo privilegio, l’anonymizzazione protegge i dati a riposo sostituendo completamente i valori sensibili. Una volta anonimizzati, i dati possono essere esportati, replicati o archiviati senza ulteriori controlli a runtime.
Tecniche Native di Anonymizzazione dei Dati in Percona Server per MySQL
Percona Server per MySQL non fornisce un motore di anonymizzazione nativo, un modello di policy o controlli sul ciclo di vita dei dati anonimizzati. Non esistono meccanismi integrati per identificare colonne sensibili, applicare lo scopo dell’anonymizzazione o convalidare i risultati. Di conseguenza, l’anonymizzazione si implementa combinando primitiva SQL standard come UPDATE, funzioni, join e tabelle di supporto.
Questi approcci possono ottenere trasformazioni irreversibili, ma dipendono interamente da logica manuale e disciplina operativa.
Sostituzione Deterministica con Istruzioni UPDATE
La tecnica di anonymizzazione più diretta è sovrascrivere le colonne sensibili con valori generati o sintetici. Questo metodo è comunemente usato quando si preparano copie di database di produzione per test o sviluppo.
UPDATE customers
SET
email = CONCAT('user_', id, '@example.com'),
phone = NULL,
full_name = CONCAT('Cliente_', id),
address = 'REDACTED',
birth_date = NULL;
Questo approccio preserva chiavi primarie e numero di righe, aiutando a mantenere una stabilità referenziale di base. I sistemi a valle che dipendono da identificatori come id continuano a funzionare, mentre i dati personali reali vengono rimossi.
Tuttavia, questo metodo ha scarsa scalabilità. Ogni tabella richiede una propria logica di anonymizzazione e ogni colonna sensibile deve essere gestita esplicitamente. Se successivamente viene aggiunta una colonna nuova, rimarrà non anonimizzata a meno che lo script non venga aggiornato. La consistenza referenziale tra tabelle correlate deve essere mantenuta manualmente e l’ordine di esecuzione diventa critico in schemi con identificatori condivisi. Non esiste una validazione integrata per confermare che l’anonymizzazione sia completa e, una volta eseguita, non è possibile annullarla senza ripristinare da backup. I dati originali sono distrutti permanentemente.
Anonymizzazione Basata su Hash
L’hashing sostituisce i valori sensibili con digest a lunghezza fissa, rimuovendo la leggibilità ma mantenendo l’unicità. Questo metodo si usa talvolta quando è richiesta correlazione o deduplicazione senza esporre i valori originali.
UPDATE users
SET
national_id = SHA2(CONCAT(national_id, 'static_salt_123'), 256),
email = SHA2(CONCAT(email, 'static_salt_123'), 256);
L’anonymizzazione basata su hash è irreversibile, ma introduce rischi sottili. Sali prevedibili o riutilizzati indeboliscono la protezione e rendono gli hash vulnerabili a inferenze. Poiché input identici producono sempre hash identici, le relazioni tra tabelle e dataset restano visibili.
UPDATE payments
SET
payer_id = SHA2(CONCAT(payer_id, 'static_salt_123'), 256);
Mantenere la coerenza tra tabelle ora dipende dall’usare la medesima logica di hashing e salatura ovunque. Ogni deviazione interrompe join e correlazioni. Inoltre, in base al contesto e al rischio di ri-identificazione, i valori hash potrebbero ancora essere considerati dati personali sotto certe normative. Con la crescita dei dataset, gestire i sali e applicare hashing coerente tra ambienti diventa fragile e soggetto a errori.
Tabelle di Sostituzione con Token
Una tecnica più controllata utilizza tabelle di lookup che mappano valori originali a token sintetici. Questo consente di mantenere i dati anonimizzati realistici pur impedendo l’identificazione diretta.
CREATE TABLE token_emails (
original_email VARCHAR(255),
token_email VARCHAR(255)
);
INSERT INTO token_emails VALUES
('[email protected]', '[email protected]'),
('[email protected]', '[email protected]');
L’anonymizzazione viene quindi applicata tramite sostituzione basata su join:
UPDATE orders o
JOIN token_emails t
ON o.email = t.original_email
SET
o.email = t.token_email;
Questo approccio migliora la qualità dei dati per test e analisi, ma aumenta significativamente l’overhead operativo. La generazione di token deve evitare collisioni, i token devono rimanere consistenti in tutte le tabelle correlate e il riutilizzo deve essere attentamente controllato per prevenire inferenze. Nel tempo, le stesse tabelle di token diventano asset sensibili che richiedono protezione, rotazione e controllo degli accessi. Senza una governance centralizzata, la gestione del ciclo di vita dei token diventa rapidamente difficile da mantenere e da auditare.
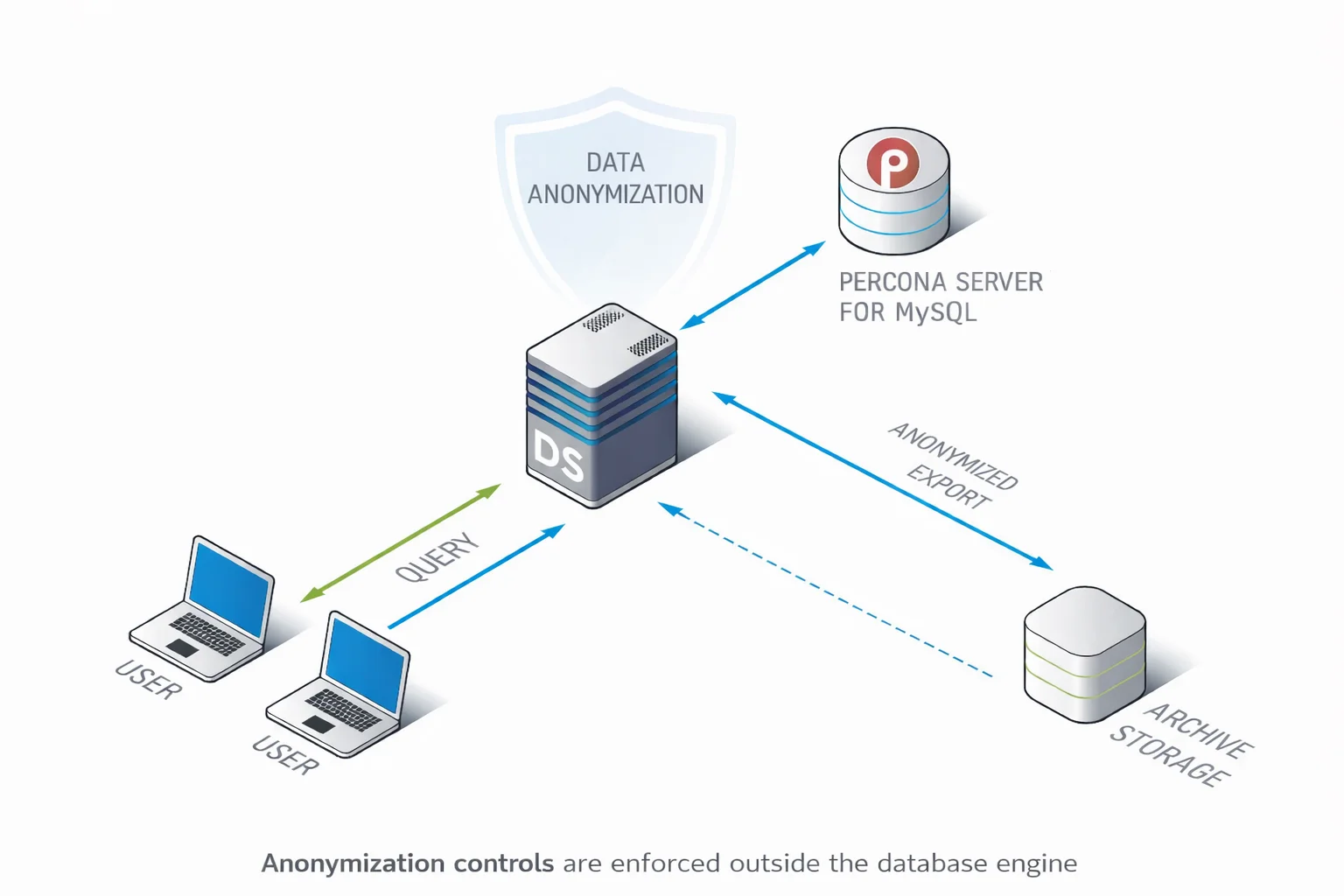
Anonymizzazione Centralizzata dei Dati con DataSunrise
DataSunrise tratta l’anonymizzazione dei dati come un processo di sicurezza governato piuttosto che come un’operazione distruttiva una tantum in SQL. Invece di incorporare logiche irreversibili negli schemi di database o mantenere script di anonymizzazione fragili, le regole di anonymizzazione sono definite centralmente e applicate coerentemente in tutti gli ambienti Percona Server per MySQL.
Questo approccio separa la logica di anonymizzazione dalla struttura del database. I database restano intatti mentre l’anonymizzazione viene applicata come uno strato di trasformazione controllato. Di conseguenza, le stesse policy possono essere riutilizzate su repliche di produzione, ambienti di test, esportazioni e archivi senza riscrivere SQL o rischiare risultati incoerenti.
L’anonymizzazione centralizzata introduce anche visibilità e controllo assenti nelle soluzioni native. Gli amministratori possono vedere quali dati sono stati anonimizzati, come sono stati trasformati e dove sono state applicate tali trasformazioni.
Individuazione dei Dati Sensibili
Il processo inizia con l’individuazione automatizzata dei dati sensibili. Invece di affidarsi a revisioni manuali degli schemi, DataSunrise scansiona i database per identificare dati personali, attributi finanziari, credenziali ed altri campi regolamentati. L’individuazione opera a livello di colonna e considera sia schemi di denominazione che contenuti, riducendo il rischio di identificatori nascosti trascurati.
Questo passaggio stabilisce un ambito verificato per l’anonymizzazione, garantendo che la protezione venga applicata a tutti i dati rilevanti e non solo a un sottoinsieme stimato.
Definizione delle Policy
Una volta identificati i dati sensibili, le policy di anonymizzazione vengono definite centralmente. Le policy specificano come le diverse categorie di dati devono essere trasformate, ad esempio con sostituzione tramite valori sintetici, tokenizzazione o anonymizzazione irreversibile.
Le policy sono riutilizzabili e versionate. La stessa logica di anonymizzazione può essere applicata coerentemente su più database e ambienti, eliminando divergenze causate da script SQL copiati e incollati. Le modifiche alle policy si propagano automaticamente senza necessità di modificare schemi di database o codice applicativo.
Selezione della Modalità di Esecuzione
L’anonymizzazione viene quindi applicata in base al contesto di esecuzione anziché a SQL hardcoded. Questo permette alle organizzazioni di controllare dove e quando avviene l’anonymizzazione senza duplicare la logica.
Obiettivi tipici di esecuzione includono ambienti di test e sviluppo, esportazioni di dati condivise con terze parti, repliche di database utilizzate per analisi e dataset archiviati per conservazione a lungo termine. Ogni contesto può riutilizzare le stesse policy mantenendo però un isolamento operativo.
Questo modello assicura che i sistemi di produzione rimangano intatti mentre i consumatori di dati a valle ricevono dataset sicuri e anonimizzati.
Verifica e Reportistica
Dopo l’esecuzione, DataSunrise fornisce capacità di verifica e reportistica assenti negli approcci nativi. Gli amministratori possono confermare quali dataset sono stati anonimizzati, quali policy sono state applicate e se la copertura è stata completa.
Questi report costituiscono prove per revisioni di sicurezza interne e audit di conformità esterni. Invece di affidarsi alla fiducia negli script, le organizzazioni ottengono una prova documentata che l’anonymizzazione è stata applicata coerentemente e correttamente.
Trasformando l’anonymizzazione in un flusso di lavoro gestito piuttosto che in un’attività distruttiva SQL, l’anonymizzazione centralizzata elimina le ipotesi, riduce il rischio operativo e si scala tra ambienti senza aumentare la complessità.
Impatto Aziendale di una Corretta Anonymizzazione dei Dati
| Area Aziendale | Impatto |
|---|---|
| Rischio di Sicurezza | Riduzione dell’impatto delle violazioni rimuovendo dati sensibili utilizzabili da sistemi non di produzione e dataset condivisi |
| Efficienza Operativa | Provisioning più rapido di ambienti di test, QA e analisi senza attese per pulizie manuali dei dati |
| Conformità | Riduzione dell’ambito degli audit di conformità escludendo dataset anonimizzati dalla supervisione normativa |
| Affidabilità Ingegneristica | Eliminazione dell’errore umano associato a script manuali SQL per l’anonymizzazione |
| Governance dei Dati | Separazione chiara e applicabile tra dati di produzione e non di produzione |
Una corretta anonymizzazione sposta la sicurezza a monte. I dati sensibili vengono rimossi prima che possano diffondersi in ambienti dove i controlli di accesso, il monitoraggio e la disciplina operativa sono più deboli. Invece di tentare di proteggere i dati ovunque, le organizzazioni prevengono l’esposizione alla fonte.
Conclusione
Percona Server per MySQL offre abbastanza flessibilità per implementare una basic anonymizzazione dei dati usando tecniche SQL native. Per dataset piccoli e operazioni una tantum, questo approccio può essere sufficiente, specialmente quando l’anonymizzazione è ben circoscritta e controllata manualmente. Tuttavia, anche in questi casi, l’anonymizzazione deve essere trattata come parte di più ampie pratiche di sicurezza dei dati piuttosto che come un compito di manutenzione isolato.
Con la crescita degli ambienti e l’inasprimento dei regolamenti per la conformità dei dati, l’anonymizzazione manuale diventa rapidamente fragile, opaca e difficile da validare. Gli script divergono, le colonne sensibili vengono trascurate e non esiste un modo affidabile per provare che l’anonymizzazione sia stata applicata coerentemente su test, analisi e dataset archiviate. Questa situazione è particolarmente problematica in workflow su larga scala di gestione dei dati di test in cui i dati vengono frequentemente copiati e riutilizzati.
Piattaforme centralizzate come DataSunrise trasformano l’anonymizzazione in un processo controllato, auditabile e ripetibile. Combinando la scoperta automatica di dati sensibili, trasformazioni guidate da policy e reportistica pronta per la conformità, l’anonymizzazione diventa parte dell’architettura di sicurezza anziché un ripensamento distruttivo. Questo modello centralizzato si integra naturalmente anche con altri meccanismi di protezione, inclusa la mascheratura dinamica dei dati, senza duplicare la logica o aumentare il carico operativo.
Quando eseguita correttamente, l’anonymizzazione non riguarda solo la nascondere i dati. Riguarda il rimuovere il rischio alla fonte, prima che le informazioni sensibili si diffondano in ambienti dove non dovrebbero più essere presenti.
