Anonymizzazione dei Dati in Vertica
L’anonymizzazione dei dati in Vertica è una capacità cruciale per le organizzazioni che si affidano ad analisi su larga scala mentre elaborano informazioni personali, finanziarie o regolamentate. Vertica è progettata per carichi di lavoro analitici ad alte prestazioni, rendendola ideale per report BI, analisi clienti e data science. Allo stesso tempo, questa flessibilità analitica aumenta il rischio che valori sensibili possano apparire nei risultati delle query, esportazioni o sistemi downstream se non vengono adeguatamente protetti.
Nei moderni ambienti Vertica, più team e strumenti spesso accedono agli stessi dataset. Gli analisti esplorano i dati in modo interattivo, i dashboard BI eseguono query pianificate e le pipeline di machine learning estraggono grandi dataset di addestramento. Poiché questi carichi di lavoro operano su tabelle condivise, le organizzazioni devono garantire che gli attributi sensibili rimangano protetti senza interrompere i flussi analitici o duplicare i dati.
Questo articolo spiega come l’anonymizzazione dei dati possa essere implementata in Vertica utilizzando un’applicazione centralizzata, tecniche di anonymizzazione dinamica e auditing continuo, con DataSunrise Data Compliance che agisce come livello di protezione.
Perché l’Anonymizzazione dei Dati è Necessaria in Vertica
L’architettura di Vertica dà priorità alle prestazioni analitiche. I dati sono memorizzati in contenitori ROS colonnari, gli aggiornamenti recenti risiedono in WOS e le proiezioni creano molteplici layout fisici ottimizzati della stessa tabella logica. Sebbene questo design acceleri le query, complica anche la protezione granulare dei dati.
In pratica, diversi fattori aumentano la necessità di anonymizzazione:
- Tabelle analitiche ampie spesso combinano metriche con dati PII o di pagamento.
- Le proiezioni replicano colonne sensibili su più nodi.
- I cluster condivisi supportano strumenti BI, job ETL, notebook e pipeline ML.
- Query SQL ad-hoc bypassano i livelli di reporting curati.
- I controlli RBAC nativi limitano l’accesso ma non la visibilità a livello di valore.
Non appena un utente ha accesso SELECT, Vertica restituisce tutti i valori selezionati in chiaro. Di conseguenza, le organizzazioni richiedono meccanismi di anonymizzazione che operino in tempo reale sulle query, anziché basarsi esclusivamente su permessi statici.
Per un contesto aggiuntivo, vedere la documentazione ufficiale sull’architettura di Vertica.
Architettura Centralizzata per l’Anonymizzazione in Vertica
Un approccio consolidato all’anonymizzazione dei dati in Vertica consiste nel separare l’applicazione delle regole dallo storage. In questo modello, le applicazioni client si connettono tramite un gateway centralizzato invece di collegarsi direttamente a Vertica. Ogni query SQL viene ispezionata, le regole di anonymizzazione valutate e i valori sensibili trasformati prima che i risultati vengano restituiti.
Molte organizzazioni implementano questa architettura usando DataSunrise come proxy trasparente. Poiché l’applicazione delle regole avviene esternamente a Vertica, schemi, proiezioni e logica applicativa restano invariati.
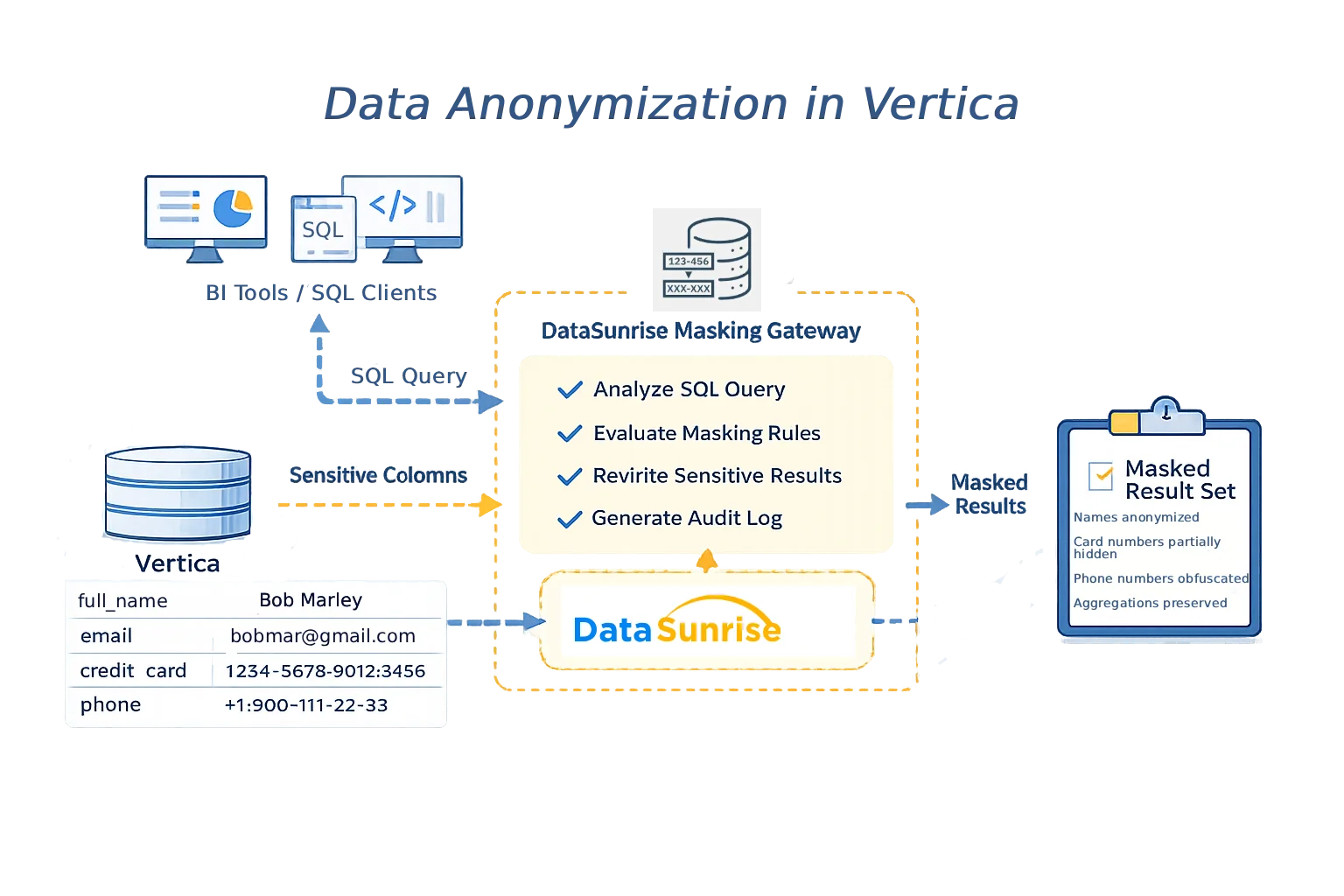
Architettura centralizzata di anonymizzazione dei dati per Vertica con DataSunrise come livello di applicazione delle regole.
Questa architettura assicura che le politiche di anonymizzazione si applichino in modo uniforme su tutti i percorsi di accesso, inclusi client SQL, strumenti BI e pipeline automatizzate.
L’Anonymizzazione Dinamica come Tecnica Principale
L’anonymizzazione dinamica è la tecnica più efficace per proteggere dati sensibili nelle analisi Vertica. Invece di modificare permanentemente i valori memorizzati, l’anonymizzazione avviene al momento della query. Quando una query fa riferimento a colonne sensibili, i valori restituiti sono sostituiti con rappresentazioni anonimizzate.
DataSunrise fornisce meccanismi integrati di mascheramento dinamico dei dati e anonymizzazione che valutano ogni query rispetto alle regole di policy. Queste regole possono considerare:
- Utente o ruolo del database
- Tipo di applicazione client
- Ambiente (produzione, staging, analisi)
- Classificazione di sensibilità di ogni colonna
Poiché l’anonymizzazione avviene solo nel set di risultati, Vertica continua a elaborare internamente i valori reali. Di conseguenza, aggregazioni, join, filtri e calcoli restano accurati.
Configurazione delle Regole di Anonymizzazione in Vertica
Per applicare l’anonymizzazione, gli amministratori definiscono una regola che prende di mira un’istanza Vertica e specifica quali colonne richiedono protezione. Le regole fanno tipicamente riferimento a schemi o tabelle identificate tramite scoperta automatica.

Configurazione della regola di anonymizzazione per un’istanza database Vertica.
In questa fase, gli amministratori abilitano l’auditing per gli eventi di anonymizzazione e definiscono come i valori sensibili devono essere trasformati. I formati possono includere anonymizzazione totale, mascheramento parziale o tokenizzazione a seconda dei requisiti di policy.
Risultati Anonimizzati nelle Query Analitiche
Dal punto di vista dell’utente, l’anonymizzazione è trasparente. Le query utilizzano SQL standard e Vertica le esegue normalmente. Tuttavia, i valori sensibili appaiono anonimizzati nei risultati restituiti.
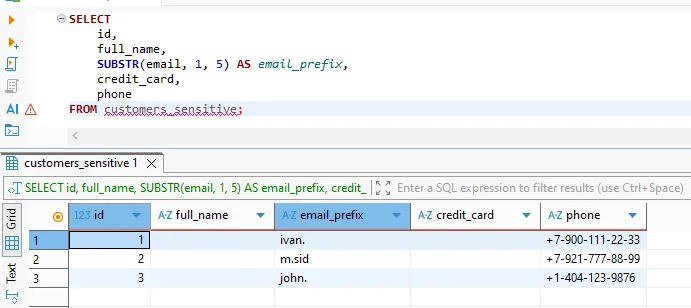
Set di risultati anonimizzato restituito al client mantenendo la struttura analitica.
Questo comportamento consente agli analisti di lavorare con dataset realistici evitando l’esposizione di identità reali. Allo stesso tempo, le pipeline di machine learning possono consumare dati di addestramento anonimizzati senza divulgare informazioni personali.
Auditing e Visibilità per Accessi Anonimizzati
L’anonymizzazione deve restare tracciabile per supportare la conformità. Le organizzazioni devono dimostrare quando è avvenuta l’anonymizzazione, quali regole sono state applicate e chi ha avuto accesso ai dati.
DataSunrise registra automaticamente eventi di audit per ogni query anonimizzata. Questi record si integrano con il Monitoraggio delle Attività del Database e possono essere esportati verso sistemi SIEM.
L’auditing centralizzato semplifica la conformità a regolamenti come GDPR, HIPAA e SOX, supportando anche le indagini interne.
Confronto tra Approcci di Anonymizzazione in Vertica
| Approccio | Descrizione | Adattabilità a Vertica |
|---|---|---|
| Anonymizzazione statica | Creare dataset anonimi permanenti | Elevata manutenzione, flessibilità limitata |
| View SQL | Anonymizzare dati usando viste predefinite | Facilmente aggirabile con query dirette |
| Logica a livello applicazione | Anonymizzazione all’interno di BI o app | Copertura incoerente |
| Anonymizzazione dinamica | Anonymizzare i risultati in tempo reale | Centralizzata e scalabile |
Best Practice per l’Anonymizzazione dei Dati in Vertica
- Iniziare con la scoperta automatizzata per identificare i campi sensibili.
- Applicare l’anonymizzazione a livello di query invece di copiare i dati.
- Testare le policy con carichi di lavoro reali di BI e analisi.
- Rivedere regolarmente i log di audit per pattern di accesso inaspettati.
- Allineare l’anonymizzazione con strategie più ampie di sicurezza dei dati.
Conclusione
L’anonymizzazione dei dati in Vertica fornisce un metodo scalabile e compatibile con l’analisi per proteggere le informazioni sensibili. Anonymizzando dinamicamente i valori al momento della query, le organizzazioni riducono i rischi di esposizione preservando potenza e flessibilità di Vertica.
Con DataSunrise come livello centralizzato di applicazione delle regole, i team ottengono protezione coerente, completa visibilità di audit e conformità normativa su dashboard, script e pipeline di machine learning—senza sacrificare le prestazioni.
