
Cos’è un File CSV?
Introduzione: Il Modesto File CSV
I file CSV risalgono ai primi giorni dell’informatica e rimangono un formato affidabile per lo scambio di dati. Negli anni ’70 e all’inizio degli anni ’80, il linguaggio Fortran 77 di IBM introdusse il tipo di dato carattere, abilitando il supporto per input e output separati da virgole. Questi file semplici ma potenti hanno superato la prova del tempo.
In precedenza abbiamo descritto le capacità di DataSunrise nella gestione di dati semistrutturati in JSON. Se stai trattando dataset strutturati o non strutturati, assicurati di consultare la nostra copertura delle sue funzionalità di protezione dei dati.
Con DataSunrise, puoi mascherare e scoprire informazioni sensibili all’interno di file formattati in CSV archiviati localmente o su Amazon S3. Di seguito un esempio di applicazione del mascheramento a un file CSV durante l’elaborazione.
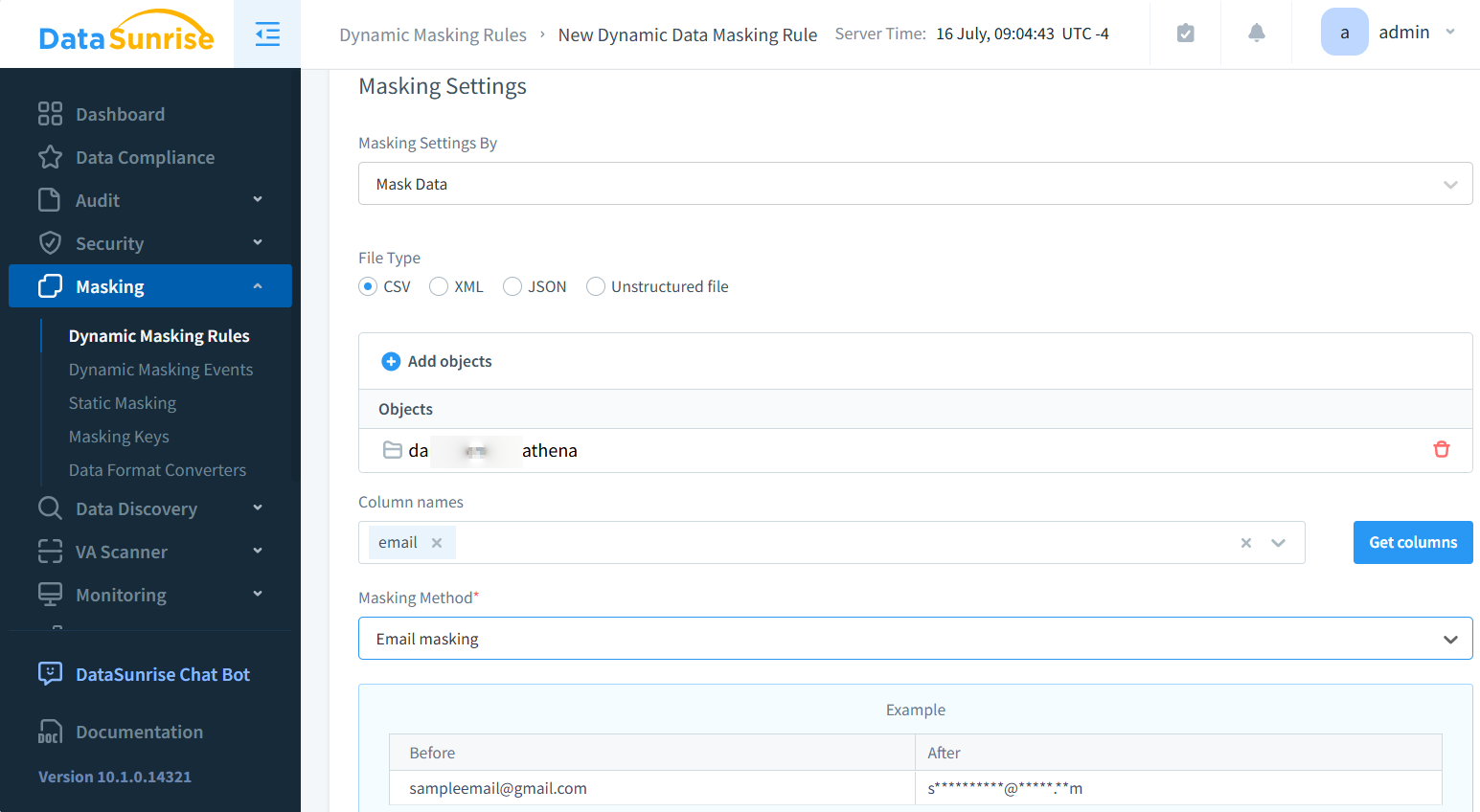
Dopo una configurazione semplice, il file mascherato può essere accesso tramite il proxy S3 di DataSunrise usando client come S3Browser. Assicurati di configurare correttamente le impostazioni del proxy per visualizzare il contenuto mascherato, come mostrato di seguito:

Sullo scenario ampio dei formati dati, il file CSV spicca per chiarezza e portabilità. Memorizza dati tabellari in una struttura semplice dove ogni riga rappresenta una linea e i valori sono separati da virgole. Questa semplicità consente al formato di rimanere compatibile su piattaforme e sistemi diversi.
Cos’è un File CSV?
Usato per rappresentare righe e colonne in testo semplice, un file CSV fornisce un modo leggero per archiviare e scambiare dati strutturati. Ogni linea contiene una riga e le virgole dividono i campi al suo interno. Il risultato è un formato facile da leggere e generare programmaticamente.
I file usano tipicamente l’estensione “.csv”—esempi includono “contacts.csv” o “report_data.csv”. Aprili in un editor di testo e vedrai una lista di valori separati da virgole. Strumenti come Excel o Google Sheets interpretano il contenuto come tabelle strutturate.
Pur essendo la virgola il delimitatore standard, in alcune implementazioni regionali o personalizzate possono apparire punti e virgola, tabulazioni o pipe. L’inclusione di una riga di intestazione è opzionale ma raccomandata, specialmente quando il set di dati contiene più campi.
A differenza di formati più sofisticati, questo non supporta formule incorporate, stili o dati annidati. Questo compromesso lo rende ideale per esportazioni pulite ma inadatto a report complessi.
Perché Usare File CSV?
Questo formato rimane popolare grazie alla sua semplicità e versatilità:
- Semplicità: Facile da leggere, anche per utenti senza esperienza tecnica.
- Compatibilità: Supportato praticamente da tutti gli strumenti di fogli di calcolo e database.
- Scambio di dati: Utile per trasferire dati tra sistemi con formati diversi.
- Efficienza dimensionale: Più piccolo rispetto ai formati binari, favorendo archiviazione e prestazioni.
Esempio di CSV
Ecco un esempio base per illustrare come appare un file CSV:
Nome, Età, Città John Doe, 30, New York Jane Smith, 25, Londra Bob Johnson, 35, Parigi
Ogni record è su una linea separata, con virgole a separare i singoli campi. Questa struttura è coerente nella maggior parte dei file CSV.
Lavorare con i File CSV in Python
Python offre librerie integrate che rendono semplice lavorare con i file CSV. Il modulo csv è spesso usato per leggere e scrivere questi file in script di base.
import csv
# Lettura di un file
with open('data.csv', 'r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
# Scrittura su file
with open('output.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['Nome', 'Età', 'Città'])
csv_writer.writerow(['Alice', '28', 'Berlino'])
Uso di Pandas
Per workflow più avanzati, la libreria pandas è spesso preferita. Permette agli sviluppatori di caricare file CSV, manipolarli usando potenti strutture DataFrame ed esportare risultati puliti.
import pandas as pd
# Lettura
df = pd.read_csv('data.csv')
print(df.head())
# Scrittura
df.to_csv('output.csv', index=False)
Compiti come filtrare, ordinare e aggregare dati sono molto più semplici con pandas. La libreria rende anche facile salvare dataset modificati in formato CSV per condivisione o archiviazione.
Pregi e Difetti dei File Separati da Virgola
Vantaggi
- Leggibilità umana: I file possono essere aperti e interpretati manualmente
- Leggerezza: Overhead minimo rispetto ai formati binari
- Supporto universale: Funziona in quasi tutti gli strumenti correlati ai dati
Svantaggi
- Limitata complessità: Non supporta dati annidati o tipi di dati ricchi
- Nessuno schema imposto: Ordine e tipo delle colonne sono debolmente definiti
- Rischi di integrità: Mancano controlli incorporati per validazione o gestione errori
I File CSV nello Scambio di Dati
Questo formato file è usato in molti campi e workflow:
- Business intelligence: Spostamento di report tra strumenti come Tableau e magazzini dati basati su SQL
- Ricerca scientifica: Pubblicazione di dataset per riuso e validazione
- Applicazioni web: Permettere agli utenti di esportare dati per backup o analisi
- IoT e registrazione sensori: Formato semplice per acquisire letture
File CSV negli Ambienti Aziendali
Molti sistemi aziendali usano ancora file CSV per importazioni, esportazioni e audit. Le istituzioni finanziarie generano riepiloghi delle transazioni in questo formato. I sistemi sanitari si affidano a trasferimenti CSV sicuri per condividere dati dei pazienti. Per le migrazioni, il CSV spesso agisce da ponte tra sistemi legacy e moderni.
File CSV nel Campo Big Data
Nonostante l’ascesa di Parquet e Avro, i file CSV non sono scomparsi dal mondo Big Data. Servono ancora a scopi chiave in certi flussi dati.
- Ingestione: I dati spesso arrivano inizialmente come CSV prima della trasformazione
- Compatibilità legacy: Molti sistemi upstream esportano testo semplice
- Esportazione dei risultati: Il CSV rende facile condividere o archiviare dati
Tuttavia, limitazioni legate a schema, compressione e parsing lo rendono meno adatto ad analisi su larga scala. Qui i formati binari tendono a eccellere.
Quando Usare un File CSV vs Formato Binario
| Caso d’Uso | Formato Migliore | Perché |
|---|---|---|
| Scambio dati tra sistemi | CSV | Semplice, leggibile dall’uomo, supportato ovunque |
| Analisi su larga scala | Parquet / Avro | Supporto schema e compressione ad alte prestazioni |
| Esportazioni o log giornalieri | CSV | Facile da automatizzare e revisionare manualmente |
Conclusione: Il Valore Duraturo dei File CSV
Anche con la diffusione di formati dati moderni e sistemi di archiviazione complessi, il CSV rimane uno degli elementi più versatili e affidabili dell’ecosistema dati odierno. La sua semplicità, compatibilità universale e struttura leggibile rendono questo formato essenziale per lo scambio dati, analisi rapide, prototipazione e archiviazione a lungo termine.
Negli ambienti aziendali, strumenti come DataSunrise aumentano ulteriormente la praticità dei file CSV aggiungendo funzionalità critiche come il mascheramento dinamico o statico dei dati, un audit logging dettagliato, classificazione dati e scoperta automatizzata di campi sensibili. Queste funzionalità aiutano le organizzazioni a gestire in sicurezza i flussi basati su CSV, ridurre i rischi operativi e soddisfare obblighi di compliance in framework come GDPR, HIPAA e PCI DSS. Se i tuoi team lavorano con dataset sensibili in CSV, considera di esplorare le soluzioni di sicurezza di DataSunrise—visita la panoramica della piattaforma o programma una demo per scoprire come semplificare protezione e governance.
