
Come eseguire l’audit di Apache Hive

Introduzione
Apache Hive è ampiamente utilizzato da numerose organizzazioni per elaborare e analizzare grandi quantità di dati strutturati memorizzati in Hadoop. Con l’aumento del volume di dati sensibili elaborati tramite Hive, l’implementazione di efficaci meccanismi di audit diventa essenziale non solo per la sicurezza, ma anche per la conformità normativa.
Questa guida La condurrà attraverso il processo di configurazione e impostazione delle funzionalità di audit per Apache Hive, dalle capacità di audit native a soluzioni avanzate con DataSunrise, assicurando di disporre della visibilità necessaria per monitorare l’accesso ai dati, rilevare attività non autorizzate e mantenere la conformità.
Come eseguire l’audit di Apache Hive utilizzando le capacità native
Apache Hive offre diversi meccanismi integrati per l’audit che È possibile configurare per tenere traccia delle attività degli utenti e delle operazioni eseguite sui dati. Esploriamo come impostare queste capacità di audit native:
Fase 1: Abilitare l’Autorizzazione Basata sugli Standard SQL
L’autorizzazione basata sugli standard SQL in Hive fornisce un modello di controllo degli accessi basato sui ruoli che include funzionalità di audit di base. Tale modello registra le operazioni e le modifiche dei privilegi effettuate dagli utenti.
Per abilitare l’autorizzazione basata sugli standard SQL, modifichi il file di configurazione hive-site.xml:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
Dopo aver apportato queste modifiche, riavvii i servizi Hive per applicare la configurazione.
Fase 2: Configurare il Framework di Logging
Apache Hive utilizza Log4j per la registrazione degli eventi, il quale può essere configurato per acquisire le informazioni di audit. Per migliorare il logging di audit, modifichi il file hive-log4j2.properties:
# Hive Audit Logging
appender.AUDIT.type = RollingFile
appender.AUDIT.name = AUDIT
appender.AUDIT.fileName = ${sys:hive.log.dir}/${sys:hive.log.file}.audit
appender.AUDIT.filePattern = ${sys:hive.log.dir}/${sys:hive.log.file}.audit.%d{yyyy-MM-dd}
appender.AUDIT.layout.type = PatternLayout
appender.AUDIT.layout.pattern = %d{ISO8601} %p %c: %m%n
appender.AUDIT.policies.type = Policies
appender.AUDIT.policies.time.type = TimeBasedTriggeringPolicy
appender.AUDIT.policies.time.interval = 1
appender.AUDIT.policies.time.modulate = true
appender.AUDIT.strategy.type = DefaultRolloverStrategy
appender.AUDIT.strategy.max = 30
# Audit Logger
logger.audit.name = org.apache.hadoop.hive.ql.audit
logger.audit.level = INFO
logger.audit.additivity = false
logger.audit.appenderRef.audit.ref = AUDIT
Queste impostazioni creano un file di log di audit dedicato che cattura tutti gli eventi di audit in un formato strutturato.
Fase 3: Abilitare i Log di Audit di HDFS
Poiché le operazioni di Hive comportano in ultima analisi operazioni su HDFS, abilitare i log di audit di HDFS fornisce un ulteriore livello di auditing. Modifichi il file hdfs-site.xml:
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.audit.log.async</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.audit.log.debug.cmdlist</name>
<value>open,create,delete,append,rename</value>
</property>
Riavvii i servizi HDFS per applicare queste modifiche.
Fase 4: Testare il Logging di Audit
Per verificare che l’audit funzioni correttamente, Esegua varie operazioni in Hive e controlli i log di audit:
-- Creare un database di test
CREATE DATABASE audit_test;
-- Creare una tabella
USE audit_test;
CREATE TABLE employee (
id INT,
name STRING,
salary FLOAT
);
-- Inserire dati
INSERT INTO employee VALUES (1, 'John Doe', 75000.00);
INSERT INTO employee VALUES (2, 'Jane Smith', 85000.00);
-- Interrogare i dati
SELECT * FROM employee WHERE salary > 80000;
-- Aggiornare i dati
UPDATE employee SET salary = 90000.00 WHERE id = 1;
-- Eliminare la tabella
DROP TABLE employee;
Dopo aver eseguito queste operazioni, controlli i log di audit per verificare che tutte le attività vengano registrate:
cat ${HIVE_LOG_DIR}/hive.log.audit

Fase 5: Integrare con Apache Ranger (Opzionale)
Per funzionalità di auditing più complete, integri Apache Hive con Apache Ranger. Ranger fornisce un’amministrazione centralizzata della sicurezza e log di audit dettagliati per i componenti di Hadoop.
-
Installi Apache Ranger utilizzando la guida ufficiale all’installazione.
-
Configuri il plugin Ranger per Hive modificando
hive-site.xml:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value>
</property>
- Configuri le impostazioni di audit di Ranger in
ranger-hive-audit.xml:
<property>
<name>xasecure.audit.is.enabled</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.driver</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.url</name>
<value>jdbc:postgresql://ranger-db:5432/ranger</value>
</property>
Limitazioni dell’Auditing Nativo
Sebbene questi meccanismi di audit nativi forniscano funzionalità di base, presentano diverse limitazioni:
- Dati di Audit Frammentati: Le informazioni di audit sono disgregate su più file di log e sistemi.
- Configurazione Complessa: Configurare un sistema di audit completo richiede la gestione di molteplici componenti.
- Strumenti di Monitoraggio Limitati: I log di audit nativi mancano di interfacce user-friendly per l’analisi.
- Reporting di Conformità Manuale: La generazione di report di conformità richiede script personalizzati o estrazioni manuali.
- Elevato Impatto sulle Risorse: Un auditing esteso può incidere sulle prestazioni in ambienti ad alto volume.
Come eseguire l’audit di Apache Hive in modo efficiente con DataSunrise
Per le organizzazioni che richiedono soluzioni di auditing più complete, DataSunrise offre funzionalità avanzate che affrontano le limitazioni dell’audit nativo di Hive. Esplori come configurare e impostare DataSunrise per eseguire l’audit di Apache Hive:
Fase 1: Distribuire DataSunrise
Inizi distribuendo DataSunrise nel proprio ambiente. DataSunrise offre opzioni di distribuzione flessibili, inclusi scenari on-premises, cloud e configurazioni ibride.
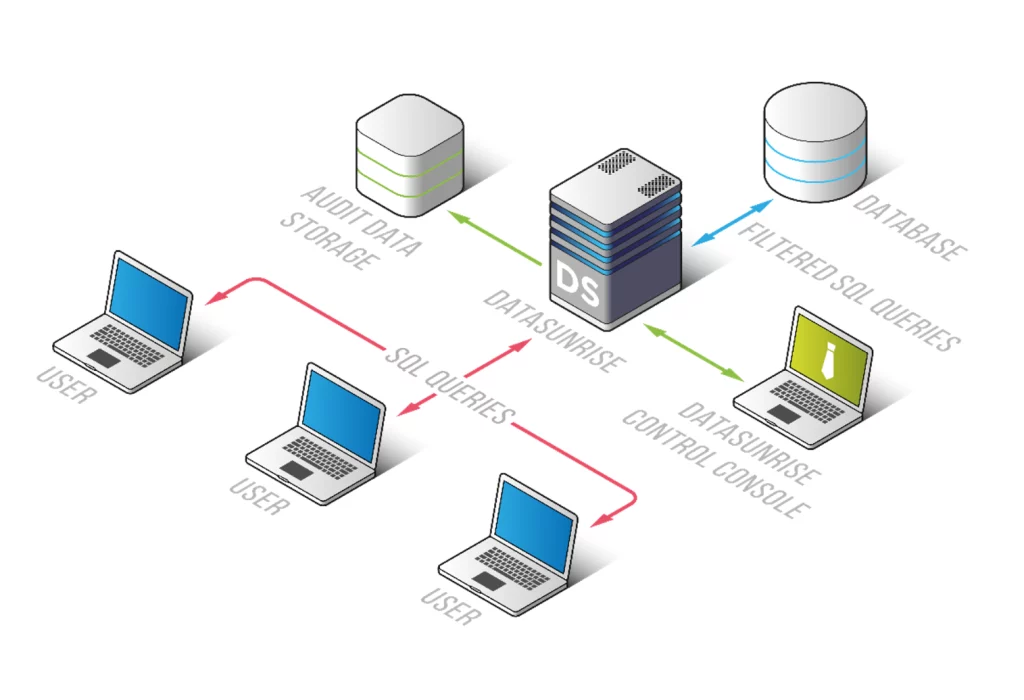
Fase 2: Connettersi ad Apache Hive
Una volta distribuito DataSunrise, lo colleghi al suo ambiente Apache Hive:
- Acceda alla console di gestione di DataSunrise.
- Vada su “Databases” e selezioni “Aggiungi Database”.
- Selezioni “Apache Hive” come tipo di database.
- Inserisca i dettagli di connessione per la sua istanza Hive, inclusi host, porta e credenziali di autenticazione.
- Testi la connessione per assicurarsi che sia configurata correttamente.

Fase 3: Configurare le Regole di Audit
Crei regole di audit per definire quali attività devono essere monitorate:
- Vada su “Regole” e selezioni “Aggiungi Regola”.
- Scelga “Audit” come tipo di regola.
- Configuri i parametri della regola, includendo:
- Nome della regola e descrizione
- Oggetti target (databases, tabelle, viste)
- Utenti e ruoli da monitorare
- Tipi di operazioni da auditare (SELECT, INSERT, UPDATE, DELETE, ecc.)
- Condizioni basate sul tempo (se necessario)
- Salvi e attivi la regola.

Fase 4: Testare e Validare l’Auditing
Esegua diverse operazioni in Hive per verificare che DataSunrise stia eseguendo correttamente l’audit delle attività:
- Esegua le stesse query di test utilizzate in precedenza per validare l’audit nativo.
- Vada nella sezione “Audit Log” di DataSunrise per visualizzare gli eventi di audit catturati.
- Verifichi che tutte le operazioni vengano registrate correttamente con informazioni dettagliate che includano:
- Identità dell’utente
- Data e ora
- Query SQL
- Tipo di operazione
- Oggetti interessati
- Indirizzo IP di origine

Conclusione
Un auditing efficace di Apache Hive è essenziale per mantenere la sicurezza, garantire la conformità e ottenere visibilità sui modelli di accesso ai dati. Sebbene le capacità di audit native di Hive forniscano funzionalità di base, le organizzazioni con requisiti avanzati traggono beneficio da soluzioni complete come DataSunrise.
DataSunrise migliora l’audit di Apache Hive con gestione centralizzata, tracce di audit dettagliate, allarmi in tempo reale e report di conformità automatizzati. Implementando una soluzione di auditing robusta, le organizzazioni possono proteggere i propri dati sensibili, mantenere la conformità normativa e rispondere rapidamente agli incidenti di sicurezza.
Pronto a potenziare le capacità di auditing di Apache Hive? Pianifichi una demo per vedere come DataSunrise possa aiutarLa a implementare un auditing completo per il Suo ambiente Hive.
