
Dati Cluster: Come Funzionano e Come Utilizzarli

I dati cluster rappresentano una tecnica potente che aiuta a scoprire pattern e tendenze nascosti in grandi set di dati. Raggruppa oggetti simili insieme, rendendo più semplice analizzare e comprendere informazioni complesse. Gli scienziati dei dati utilizzano il clustering per identificare rapidamente tematiche, rilevare anomalie e ottenere preziose informazioni da enormi quantità di dati.
Che Cos’è il Data Clustering?
Alla base, il data clustering è un metodo di unsupervised machine learning. Non richiede dati etichettati o categorie predefinite. Invece, l’algoritmo individua raggruppamenti naturali all’interno del set di dati basandosi sulla somiglianza. Inseriamo oggetti simili nello stesso gruppo e separiamo quelli differenti.
Il processo è flessibile e può operare con vari tipi di dati:
- Documenti
- Punti su un grafico
- Risposte ai sondaggi
- Sequenze genetiche
Finché esiste un metodo per misurare la somiglianza tra due oggetti, il clustering può essere applicato. Questa varietà lo rende uno strumento di riferimento per l’analisi esplorativa dei dati in diversi settori.
Analisi dei Dati Cluster in Azione
Immagini di gestire un sito di e-commerce con migliaia di prodotti. Desidera comprendere meglio il comportamento dei clienti e personalizzare le raccomandazioni. Raggruppando i dati dei suoi prodotti, potrebbe scoprire gruppi interessanti, come ad esempio:
- I bestsellers che vengono acquistati frequentemente insieme
- Articoli di nicchia che attraggono specifici segmenti demografici
- Tendenze stagionali legate a feste o eventi
Queste informazioni possono guidare le strategie di marketing, la gestione dell’inventario e il design del sito web. È possibile evidenziare bundle di prodotti popolari, personalizzare campagne email per segmenti di clienti e ottimizzare la navigazione in base ai pattern di navigazione.
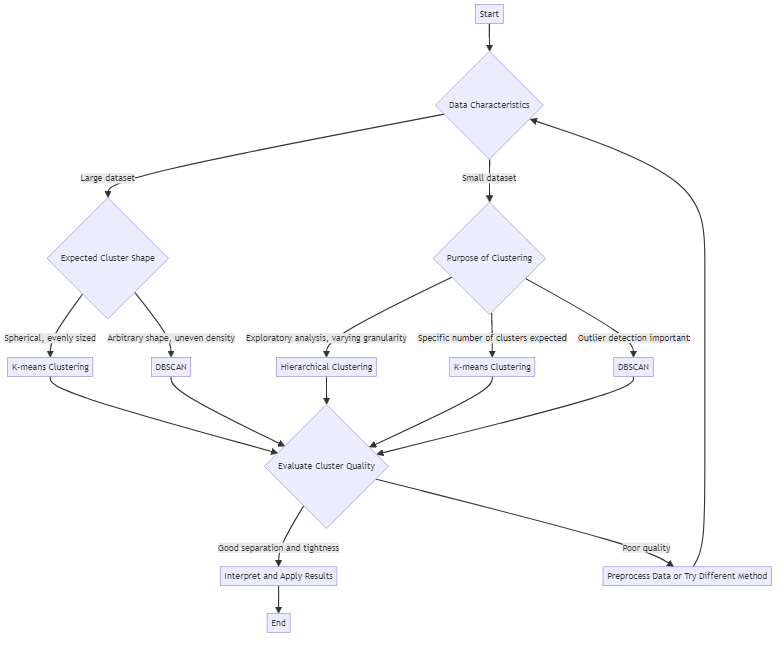
Scelta dell’Algoritmo di Clustering Appropriato
Diversi algoritmi di clustering soddisfano scopi differenti. Alcuni dei più comuni includono:
- K-means: Divide i dati in un numero predefinito (k) di cluster. Funziona bene quando si ha un’idea del numero di gruppi da aspettarsi.
- Clustering gerarchico: Costruisce cluster di dati annidati in una struttura ad albero. Utile per visualizzare i dati a diversi livelli di granularità.
- DBSCAN: Identifica cluster di forma arbitraria e segna gli outlier. Gestisce set di dati con rumore e densità non uniforme.
La scelta migliore dipende da fattori come la dimensione dei dati, la forma dei cluster attesi e la tolleranza agli outlier. Spesso vale la pena provare approcci multipli per individuare quello che fornisce i risultati più significativi.
Valutazione della Qualità dei Dati Cluster
Non tutti i cluster sono uguali. Un buon risultato di clustering mostra gruppi compatti e ben separati. Gli oggetti all’interno di un cluster dovrebbero essere altamente simili, mentre quelli in gruppi differenti devono essere distinti. Indici come il Silhouette score e tecniche di visualizzazione possono aiutare a valutare la qualità dei cluster.
È fondamentale validare i cluster confrontandoli con conoscenze specifiche del dominio per garantire l’accuratezza e la rilevanza dei risultati ottenuti. In questo modo si verifica se i cluster sono in linea con le opinioni degli esperti o con gli obiettivi aziendali. Questo processo di validazione contribuisce a confermare che i gruppi siano significativi e utili per decisioni strategiche.
Il clustering aiuta a individuare pattern nei dati, ma rappresenta solo l’inizio. L’interpretazione umana dei risultati del clustering è essenziale per estrarre intuizioni applicabili e prendere decisioni informate. Combinando dati numerici e il parere degli esperti, possiamo comprendere meglio i dati e il loro impatto sull’attività.
In sintesi, la validazione dei cluster rispetto alle conoscenze specifiche del settore e l’interpretazione dei risultati sono passi essenziali nel processo di clustering. Grazie all’uso di competenza e giudizio nel campo specifico, si garantisce che i gruppi siano utili e pratici, contribuendo al successo dell’azienda.
Applicazioni dei Dati Cluster
Le applicazioni dei dati cluster spaziano in vari settori:
- Segmentazione dei clienti per marketing mirato
- Rilevamento di anomalie nella prevenzione delle frodi
- Compressione delle immagini e riconoscimento dei pattern
- Bioinformatica e analisi dell’espressione genica
- Analisi dei social network e rilevamento delle comunità
Dove vi siano dati complessi da decifrare, il clustering rappresenta un punto di partenza prezioso. Semplifica il panorama dei dati e mette in luce strutture chiave per ulteriori indagini.
Best Practices per i Dati Cluster
Per sfruttare al meglio i dati cluster, tenga a mente questi suggerimenti:
- Pre-elaborare e normalizzare i dati per garantire comparazioni eque
- Sperimentare con differenti metriche di distanza e algoritmi
- Validare i risultati utilizzando misure statistiche e competenza specifica del dominio
- Visualizzare i cluster per comunicare in modo efficace le intuizioni
- Iterare e perfezionare il processo man mano che nuovi dati diventano disponibili
Con una corretta implementazione, i dati cluster possono rivoluzionare il modo in cui si analizzano set di dati complessi, trasformandoli in informazioni azionabili e permettendo alle organizzazioni di prendere decisioni più intelligenti.
Mettere i Dati Cluster al Lavoro
Sblocchi il potenziale dei suoi dati con il clustering. L’analisi dei cluster è uno strumento cruciale per marketer, ricercatori e scienziati dei dati. Le permette di ottenere intuizioni dai clienti, esplorare reti geniche e risolvere problemi complessi. Cominci a esplorare il mondo del data clustering e scopra i pattern nascosti già da oggi.
