
Mascheramento dei dati per Apache Impala

| id | ssn_mascherato | nome |
|---|---|---|
| 1 | XXX-9012 | Charlie |
| 2 | XXX-1098 | Diana |
Le viste offrono un modo semplice per nascondere le informazioni sensibili pur mantenendo i dati leggibili per analisi.
2. Mascheramento dei Dati per Apache Impala tramite Job ETL
Per le organizzazioni che richiedono dati pre-mascherati prima dell’archiviazione, i job ETL (Extract, Transform, Load) possono processare e mascherare i dati sensibili prima di inserirli nelle tabelle.
Ecco l’output quando si esegue l’istruzione INSERT INTO sulla tabella users basandosi sui dati provenienti dalla tabella raw_users:
Dati di Input dalla tabella raw_users:
| id | ssn | nome |
|---|---|---|
| 1 | 123-45-9012 | Charlie |
| 2 | 987-65-1098 | Diana |
Dati di Output nella tabella users:
| id | ssn_mascherato | nome |
|---|---|---|
| 1 | XXX-9012 | Charlie |
| 2 | XXX-1098 | Diana |
I valori di ssn sono stati mascherati in modo da mostrare solo le ultime quattro cifre, precedute da XXX-.
Seppure questo approccio migliora la sicurezza, esso riduce anche la flessibilità, rendendo più difficile recuperare i dati originali senza un dataset separato non mascherato.
3. Mascheramento con Funzioni Definite dall’Utente (UDFs)
Impala non dispone di UDF predefinite per il mascheramento come Hive. Secondo la documentazione, Impala supporta la scrittura di UDF personalizzate in C++ e Java per la trasformazione dei dati, ma non include funzioni di mascheramento pre-costruite. Sarà quindi necessario scrivere le proprie UDF per implementare la funzionalità di mascheramento, in modo simile a quanto offerto da Hive con le sue funzioni di mascheramento integrate.
Se necessiti di capacità di mascheramento, potresti:
- Scrivere UDF personalizzate in C++ per implementare la logica di mascheramento necessaria
- Utilizzare UDF Java esistenti di Hive per il mascheramento importandole in Impala
- Gestire il mascheramento a livello di applicazione prima di caricare i dati in Impala
Supponiamo di aver scritto una UDF personalizzata in Impala utilizzando C++ o Java per mascherare i numeri di previdenza sociale (SSN) nella colonna ssn. Per semplicità chiameremo questa UDF personalizzata mask_ssn.
Ecco un esempio di come potresti interrogare questa UDF e l’output previsto:
Esempio di Query con UDF Personalizzata:
SELECT id, mask_ssn(ssn) AS masked_ssn, name
FROM users;
Output Previsto:
| id | ssn_mascherato | nome |
|---|---|---|
| 1 | XXX-9012 | Charlie |
| 2 | XXX-1098 | Diana |
Spiegazione:
- La UDF
mask_ssntrasformerà i numeri di previdenza sociale sostituendo i primi cinque caratteri conXXX-, lasciando visibili le ultime quattro cifre. - L’output previsto è simile all’effetto ottenuto utilizzando
CONCAT('XXX-', RIGHT(ssn, 4)), ma l’impiego di una UDF personalizzata offre maggiore flessibilità per implementare logiche di mascheramento più complesse.
Mascheramento Avanzato dei Dati per Impala con DataSunrise
DataSunrise offre un mascheramento dinamico e statico senza modificare i dati originali. Garantisce:
- Mascheramento dei dati basato sui ruoli.
- Integrazione senza soluzione di continuità con Impala.
- Impatto minimo sulle prestazioni.
Passaggi per l’Implementazione:
- Connetti la tua istanza di Impala a DataSunrise.
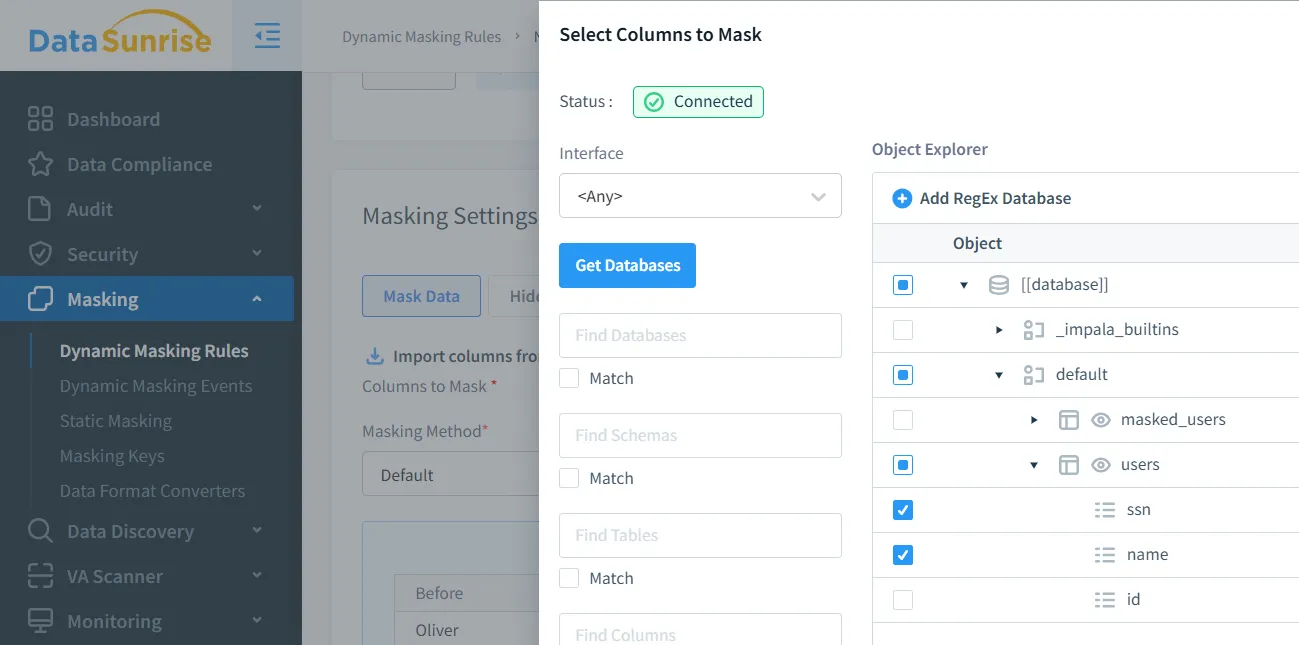
- Definisci le regole di mascheramento tramite l’interfaccia di DataSunrise.
- Valida il mascheramento dei dati eseguendo query di test.

Conclusione
Il mascheramento dei dati è cruciale per proteggere le informazioni sensibili in Impala e garantire la conformità alle normative. Mentre viste e UDF offrono soluzioni di base, il mascheramento tramite ETL rappresenta un approccio più permanente. DataSunrise migliora ulteriormente la sicurezza offrendo soluzioni di mascheramento dei dati flessibili, scalabili e a impatto minimo.
Prenota una demo di DataSunrise per esplorare soluzioni avanzate di sicurezza dei dati per il tuo ambiente Impala.
