
Data Masking per Apache Hive

| id | masked_ssn | name |
|---|---|---|
| 1 | XXX-6789 | Alice |
| 2 | XXX-4321 | Bob |
Vantaggi del masking basato sulle view:
- Implementazione semplice mediante SQL.
- Nessun strumento aggiuntivo richiesto.
- Fornisce protezione dei dati a livello di colonna.
2. Approccio di Virtualizzazione dei Dati per RLS in Hive
Poiché Hive non supporta nativamente la sicurezza a livello di riga (RLS), si può utilizzare un workaround basato sulla virtualizzazione dei dati per ottenere un risultato simile, reindirizzando le query verso view mascherate.
Come Funziona
- Restringi l’accesso alla tabella originale.
- Crea una view mascherata in uno schema specifico per l’utente.
- Imposta lo schema predefinito dell’utente per interrogare automaticamente la view mascherata.
Esempio: Mascheramento degli SSN per Analista
CREATE DATABASE analyst1_db;
CREATE VIEW analyst1_db.users AS
SELECT id, CONCAT('XXX-', SUBSTR(ssn, -4)) AS ssn, name
FROM default.users;
Output Atteso:
Quando l’analista esegue:
SELECT * FROM users;
Interrogherà la view mascherata (analyst1_db.users), garantendo la protezione dei dati.
Risultati Query Attesi
| Query Eseguita | Tabella Accessibile | Risultato (Mascherato/Non Mascherato) |
|---|---|---|
| SELECT * FROM users; (Analista) | analyst1_db.users | Mascherato (XXX-6789) |
| SELECT * FROM users; (Admin) | default.users | Non Mascherato (123-45-6789) |
Questa tecnica di virtualizzazione dei dati offre un workaround pratico per Hive, ma non è un sostituto perfetto per la sicurezza a livello di riga. Potrebbe aggiungere complessità con schemi specifici per ogni utente e causare confusione se non documentata correttamente. Per una soluzione più robusta, si consiglia di integrare Apache Ranger o altri strumenti dedicati.
3. Data Masking per Apache Hive con Apache Ranger
Apache Ranger offre un controllo centralizzato degli accessi con capacità di masking a livello granulare. Ranger consente di:
- Masking Statico: Trasformazioni fisse come la sostituzione dei valori con null o costanti.
- Masking Dinamico: Trasformazioni basate sul ruolo dell’utente, in cui la visibilità dei dati sensibili dipende dai permessi.
Esempio: Applicazione di una Politica di Masking in Apache Ranger
- Definire una politica di data masking in Ranger per la tabella
users. - Impostare regole di masking a livello di colonna per la colonna
ssn. - Assegnare ruoli per controllare quali utenti vedono valori mascherati rispetto a quelli non mascherati.
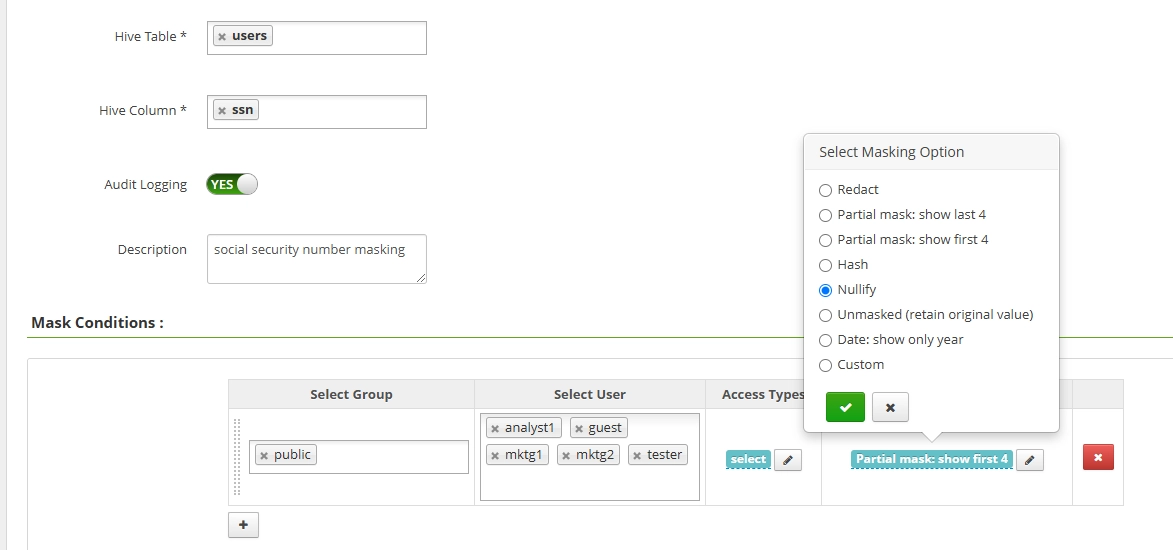
Risultati Query per l’Esempio della Politica Ranger:
| Utente | Colonna | Risultato della Query |
|---|---|---|
| Analista | ssn | Mascherato con NULL |
| Ospite | ssn | Mascherato con NULL |
| Amministratore | ssn | Non Mascherato |
Data Masking per Apache Hive Utilizzando DataSunrise
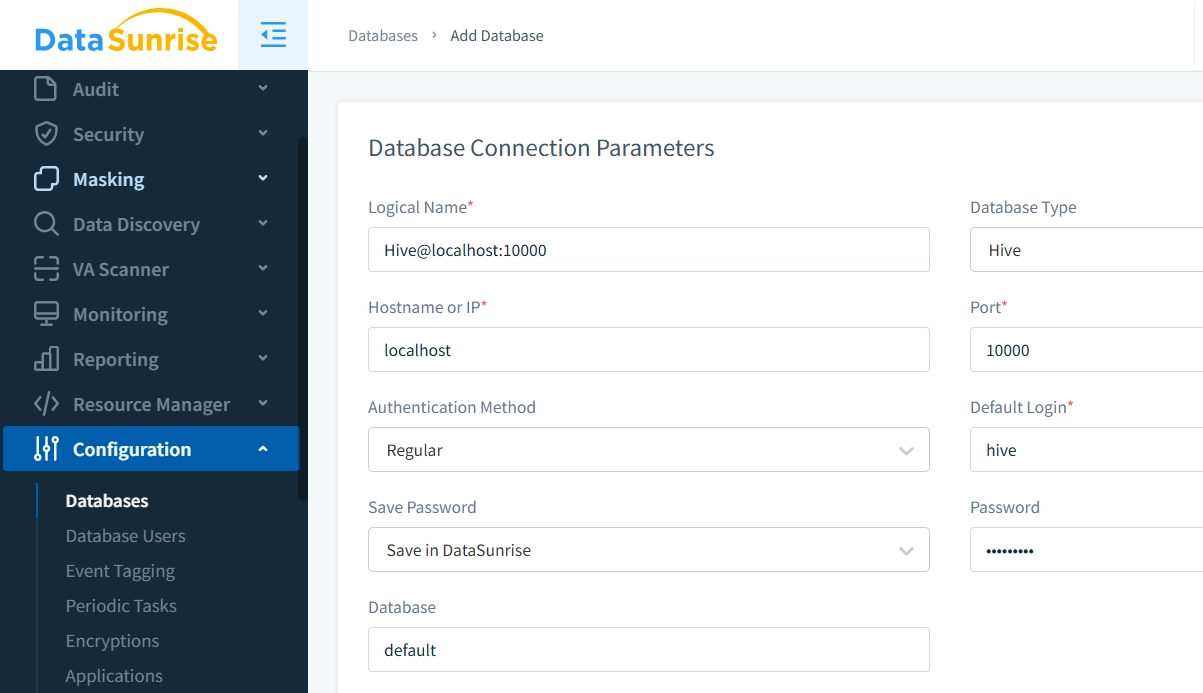
1. Collega la Tua Istanza Hive a DataSunrise
Una volta installato DataSunrise, configurarlo per connettersi al tuo ambiente Hive specificando i parametri di connessione.
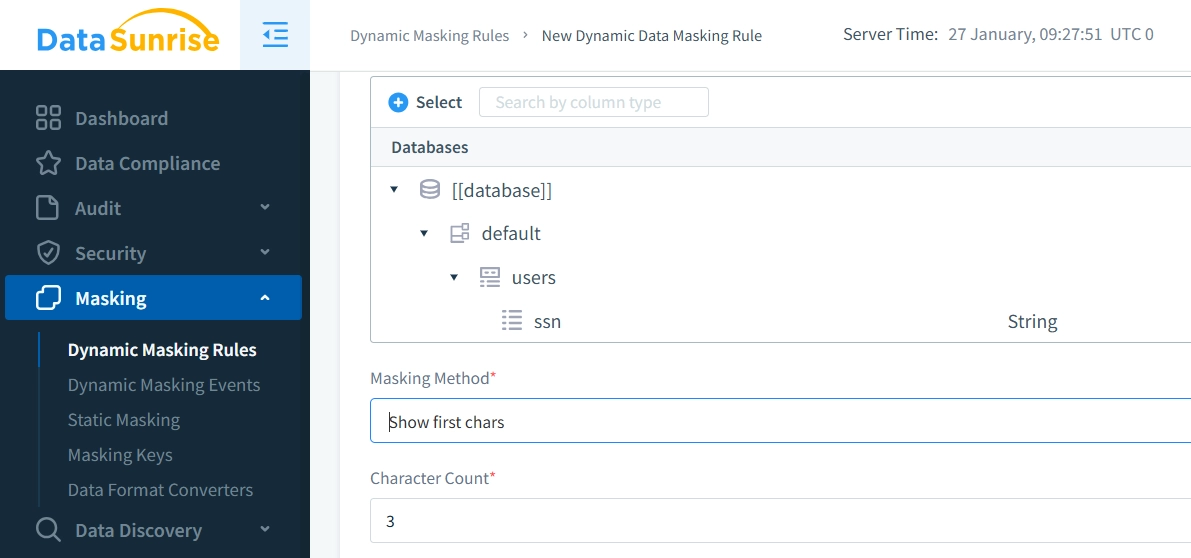
2. Definisci Regole di Masking
Crea regole di data masking in DataSunrise per specificare quali colonne devono essere mascherate e i metodi di masking da applicare. DataSunrise supporta sia il data masking dinamico che quello statico, ciascuno configurabile nelle rispettive sezioni dell’interfaccia utente. Per questa dimostrazione, ci concentriamo sul masking dinamico, specificando esattamente quali dati devono essere mascherati.
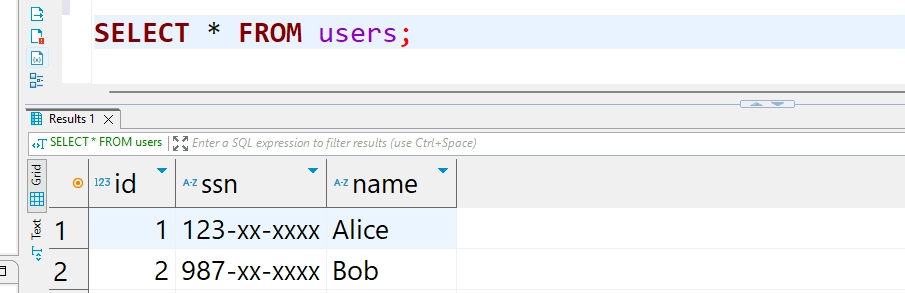
3. Testa e Valida
Esegui query per verificare che il data masking sia applicato correttamente senza impattare sulle prestazioni delle query.
Conclusione
Il data masking è essenziale per proteggere i dati sensibili in Apache Hive e garantire la conformità normativa. Sebbene le view in Hive e la virtualizzazione dei dati offrano capacità di masking di base, esse richiedono spesso una configurazione manuale e mancano di flessibilità. Apache Ranger fornisce un controllo centralizzato, ma può essere complesso da gestire e configurare efficacemente.
DataSunrise offre una soluzione superiore, fornendo data masking dinamico e statico con un impatto minimo sulle prestazioni. La sua interfaccia intuitiva, politiche flessibili e integrazione senza soluzione di continuità con Hive lo rendono la scelta ideale e scalabile per migliorare la sicurezza dei dati.
DataSunrise offre funzionalità avanzate di sicurezza per i database, tra cui auditing, masking e data discovery. Pianifica una demo online per scoprire come possiamo aiutarti a proteggere i dati memorizzati in Hive.
