
Mascheramento Statico dei Dati
Introduzione
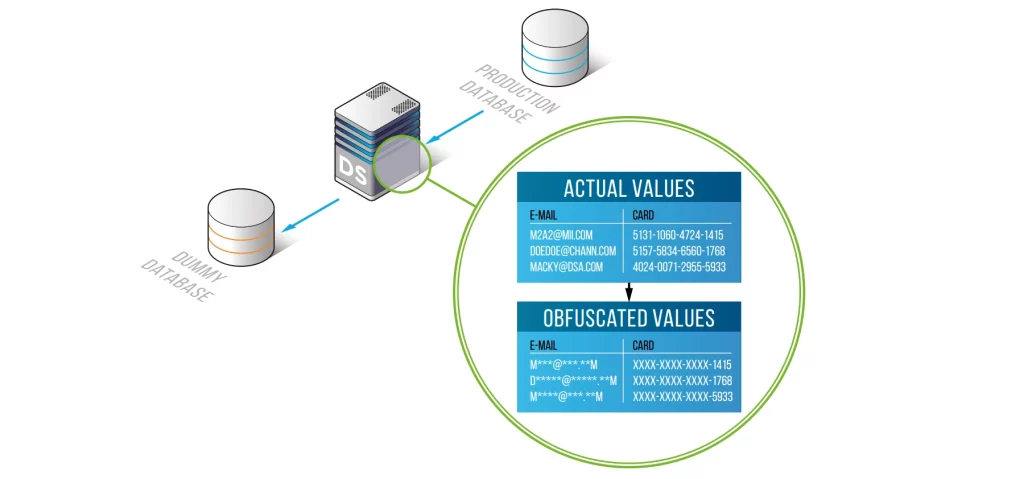
Il mascheramento statico dei dati protegge le informazioni sensibili generando una copia sicura e anonimizzata dei dati di produzione in cui i campi riservati vengono sostituiti con valori realistici ma fittizi. Poiché il set di dati risultante mantiene lo schema originale, le relazioni e il formato dei dati, esso resta completamente utilizzabile per test, analisi, sviluppo software e machine learning—senza esporre informazioni personali identificabili, dati finanziari o sanitari a soggetti non autorizzati. Questo approccio permette alle organizzazioni di bilanciare l’utilità dei dati con rigorosi requisiti di privacy e conformità. Le linee guida di standard come il framework ISO/IEC 27559 per la protezione dei dati sottolineano ulteriormente l’importanza di pratiche robuste di anonimizzazione.
Questo articolo esplora i principi chiave del mascheramento statico dei dati, spiega come si differenzia dal mascheramento dinamico e ne analizza il ruolo cruciale nella gestione della conformità, nella garanzia della privacy e nella riduzione del rischio. Dimostra inoltre come DataSunrise semplifichi il deployment tramite flussi di lavoro automatizzati, garantisca l’integrità referenziale in dataset complessi e supporti ambienti di database eterogenei—sia on-premises che in cloud. Inoltre, il mascheramento statico è inestimabile per la condivisione sicura dei dati con fornitori terzi, partner di ricerca o team di test, nonché per abilitare processi di migrazione sicuri al cloud in cui solo dataset anonimizzati e conformi lasciano il perimetro di produzione protetto.
Mascheramento Statico vs Dinamico: Differenze Chiave
Entrambe le tecniche proteggono i campi sensibili, ma rispondono a esigenze operative diverse.
Il mascheramento statico dei dati genera una nuova copia mascherata del database dove il contenuto sensibile è sostituito da valori sintetici—ideale per sviluppo/test, passaggi a fornitori e condivisione sicura dei dati.
Al contrario, il mascheramento dinamico opera in tempo reale—mascherando i risultati delle query in base al contesto di accesso senza modificare i dati memorizzati—migliore per il controllo degli accessi in produzione all’interno delle applicazioni.
| Caratteristica | Mascheramento Statico | Mascheramento Dinamico |
|---|---|---|
| Come Funziona | Genera una copia mascherata del database | Modifica l’output delle query a runtime |
| Caso d’Uso | Sviluppo/test, accessi esterni | Controllo accessi in tempo reale |
| Performance | Nessun impatto a runtime | Applicato al volo |
| Sicurezza dei Dati | Adatto per esportazione/condivisione | Richiede policy di protezione a runtime |
Quando Usare il Mascheramento Statico
Il mascheramento statico dei dati è particolarmente prezioso quando le informazioni sensibili devono essere spostate fuori dal loro ambiente originale di produzione. Consente ai team di lavorare con dataset realistici assicurando che nessun dato personale identificabile o regolamentato venga esposto. I casi d’uso tipici includono:
- Ambient i di sviluppo e testing: Permettere a sviluppatori e ingegneri di costruire, debuggare e ottimizzare funzionalità usando dati che riflettono la complessità reale—senza rivelare identità dei clienti reali, dettagli di pagamento o record riservati.
- Ambient i di qualità e di staging: Replicare le condizioni di produzione per test funzionali, di performance o di integrazione senza introdurre rischi di conformità o privacy.
- Formazione e onboarding dei dipendenti: Fornire ai nuovi assunti e ai team di supporto esempi realistici che migliorano l’apprendimento tutelandone completamente le informazioni sensibili.
- Collaborazioni esterne: Condividere dataset in sicurezza con consulenti, team esternalizzati, ricercatori o fornitori senza concedere accesso a dati regolamentati.
- Migrazioni cloud, backup e archiviazione: Trasferire o conservare dataset mascherati per ridurre i rischi di esposizione durante il movimento, la replicazione o la conservazione a lungo termine.
Con DataSunrise, questi flussi di lavoro possono essere standardizzati e automatizzati. Il mascheramento preserva il formato per garantire coerenza analitica e relazionale, l’integrità referenziale è mantenuta attraverso tabelle e schemi, e i job schedulati assicurano che ogni dataset generato rimanga conforme nel tempo. Inoltre, le funzionalità integrate di auditing e controllo policy aiutano le organizzazioni a validare il processo di mascheramento e dimostrare la conformità a revisori e regolatori.
Come DataSunrise Applica il Mascheramento Statico dei Dati
DataSunrise supporta il mascheramento statico su SQL Server, Oracle, PostgreSQL, MongoDB e database cloud come Amazon Redshift. Funziona tramite il server DataSunrise (senza modifiche di schema). L’installazione definisce quattro aree: istanze sorgente/destinazione, tabelle trasferite, frequenza di schedulazione e regole opzionali di pulizia.
Funzioni di mascheramento comuni e quando usarle
| Funzione | Esempio Input | Output Mascherato | Ideale per |
|---|---|---|---|
| FPE (AES-FFX) | 4111 1111 1111 1111 | 4129 6034 5821 4410 | Simulazioni di carte di credito |
| Substring Redact | [email protected] | al***@***.com | Email, nomi utente |
| Scambio date (+/- 365gg) | 1990-05-09 | 1990-12-17 | Date di nascita |
| Dictionary Swap | Chicago | Francoforte | Campi città / paese |
Istanza Sorgente e Destinazione
Il processo di mascheramento genera una nuova istanza con dati mascherati. La sorgente contiene il contenuto originale; la destinazione è dove risiederanno i dati offuscati.
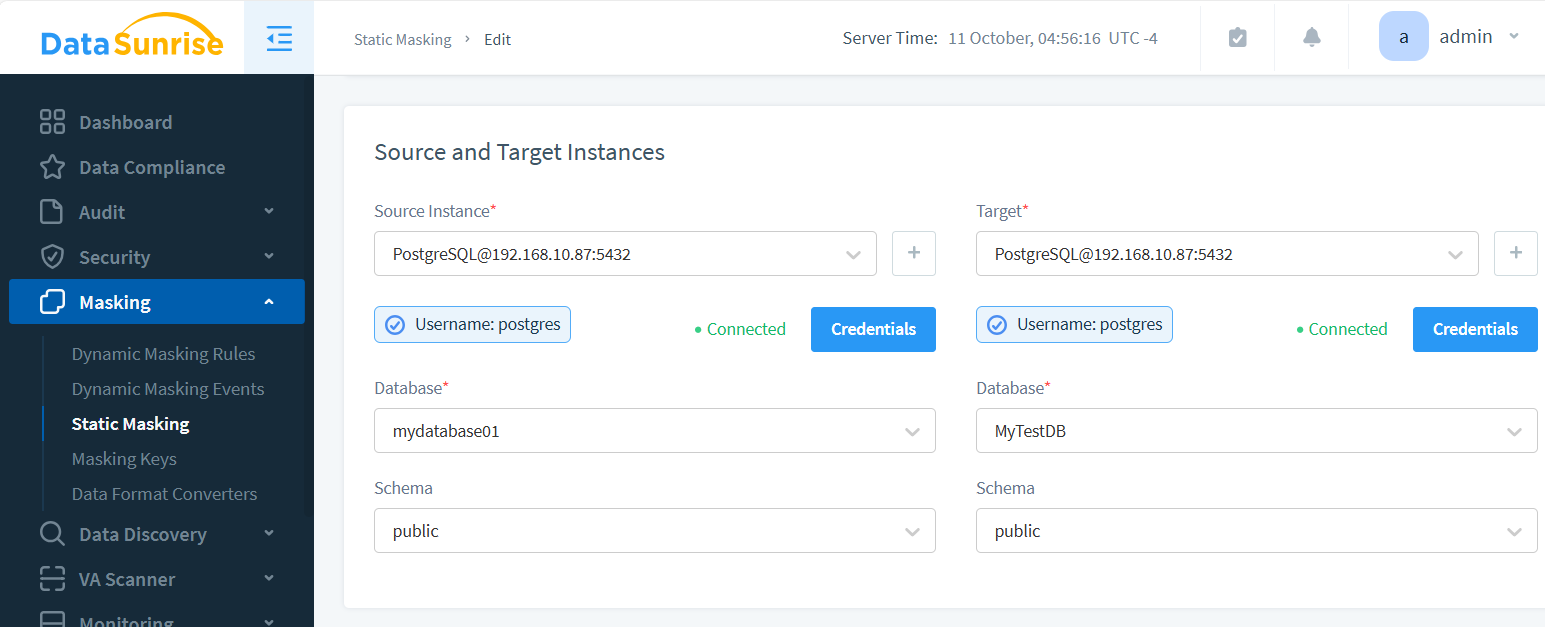
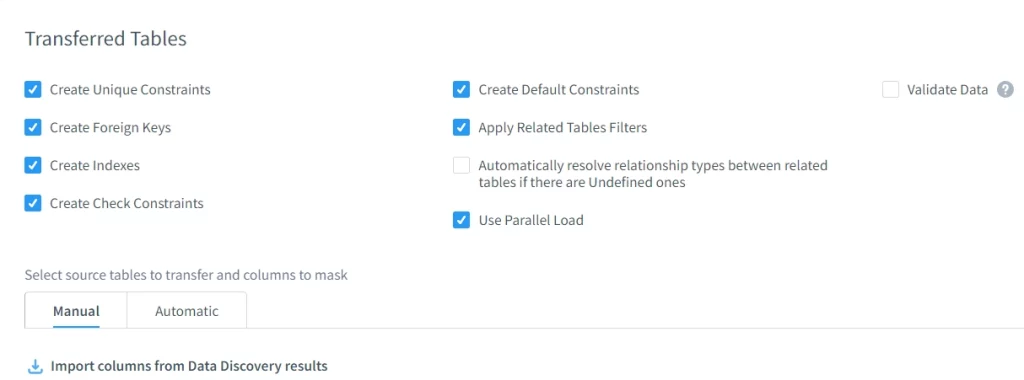
Tabelle Trasferite
DataSunrise preserva integrità referenziale, vincoli, indici e relazioni tra le tabelle mascherate—mantenendo i dati utilizzabili dopo l’offuscamento.
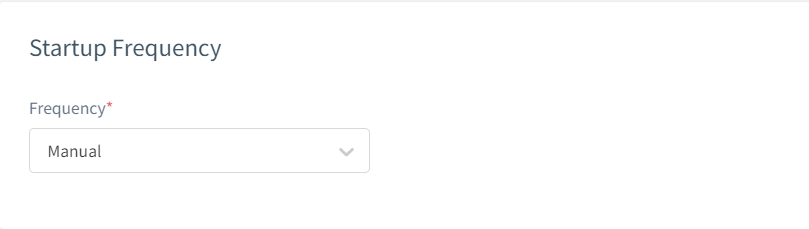
Frequenza di Avvio
Esegui i task manualmente, schedula una sola volta o configura intervalli ricorrenti. Ciò automatizza i flussi di aggiornamento dati mantenendo attuali gli ambienti di test.
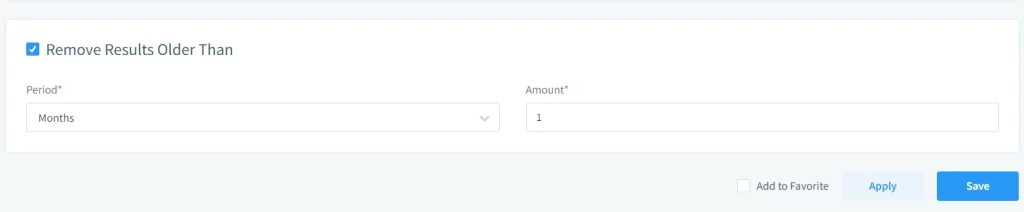
Rimuovi Risultati Più Vecchi di
Applica politiche di retention per eliminare database mascherati obsoleti. Questo salva spazio di archiviazione e riduce l’ingombro operativo.
Simulare il Mascheramento Statico in PostgreSQL
Ecco come si potrebbe simulare manualmente il mascheramento statico senza automazione:
-- Passo 1: Crea copia mascherata di una tabella
CREATE TABLE customers_masked AS
SELECT
id,
name,
email,
'XXXX-XXXX-XXXX-' || RIGHT(card_number, 4) AS card_number
FROM customers;
-- Passo 2: Maschera formato email
UPDATE customers_masked
SET email = CONCAT(LEFT(email, 2), '***@***.com');
Questo metodo funziona per mascheramenti su piccola scala, ma manca di logica per preservare il formato, enforcement di chiavi esterne e logging di audit. DataSunrise automatizza e scala questo flusso di lavoro su più piattaforme.
Esempio Pratico: PostgreSQL + DataSunrise
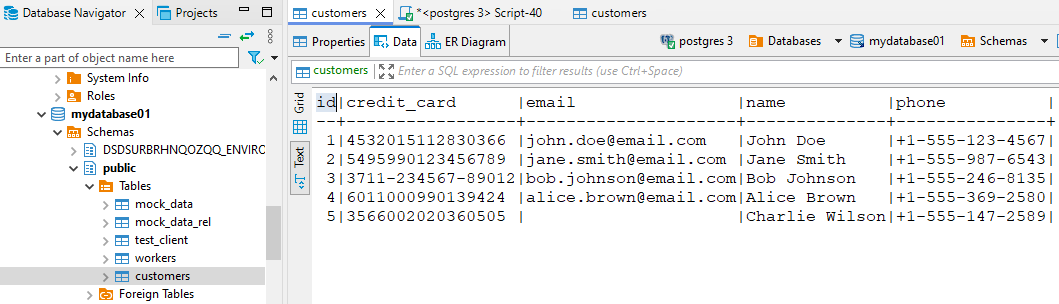
Considera un database PostgreSQL con dati clienti che includono nomi, email e numeri di carta. Vista non mascherata:
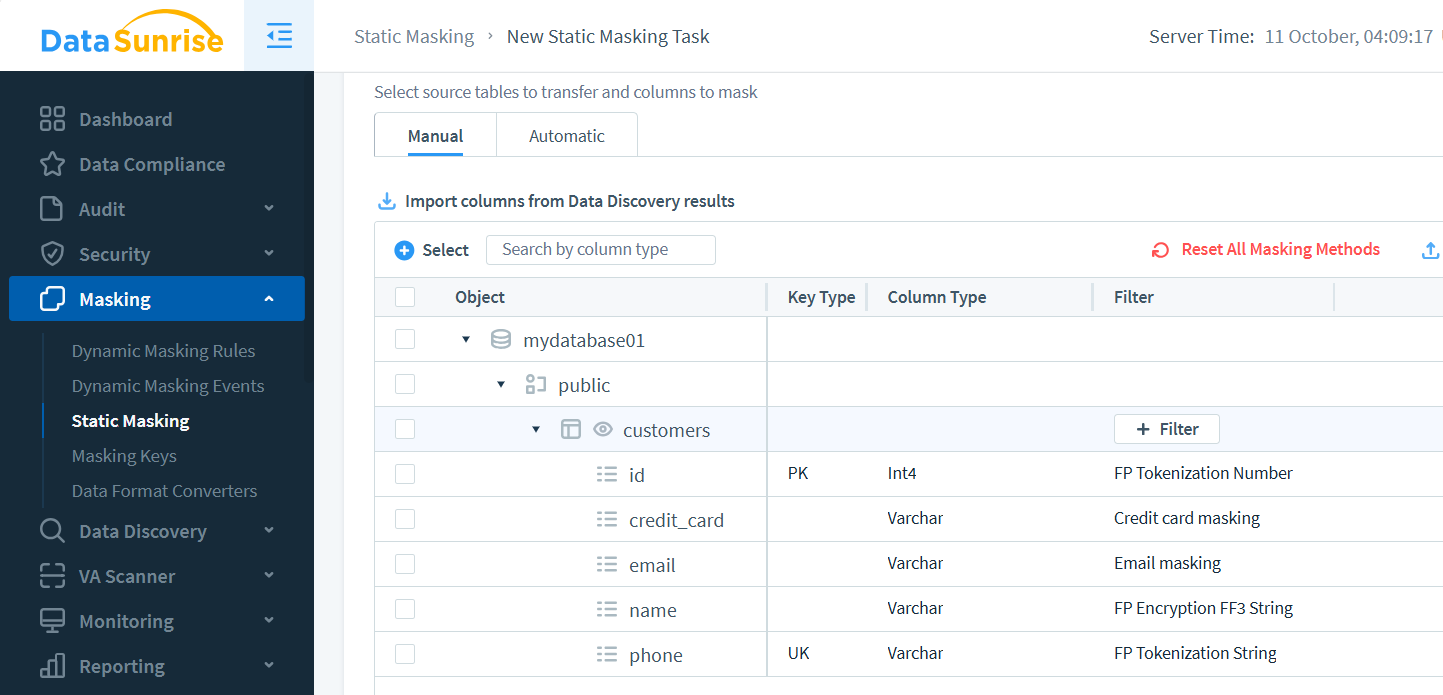
In DataSunrise, configura un task tramite il pannello Mascheramento Statico. Seleziona le istanze, definisci le tabelle e scegli i metodi di mascheramento per colonna:
Al completamento del task, riceverai conferma nello stato del lavoro:
L’istanza destinazione ora contiene una versione completamente mascherata dei dati:
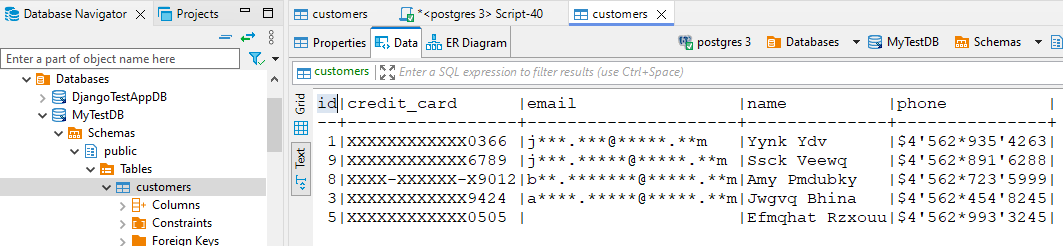
Mascheramento Statico con DataSunrise: Vantaggi Chiave
- Dati realistici per sviluppo e test
- Offuscamento che preserva il formato
- Integrità referenziale mantenuta
- Nessun impatto sui sistemi sorgenti
- Conformità GDPR/PCI/HIPAA garantita
Best Practice per il Mascheramento Statico dei Dati
Anche con lo strumento giusto, l’efficacia dipende da un’implementazione precisa. Usa queste pratiche per mantenere il mascheramento sicuro, scalabile e pronto per gli audit:
- Maschera a livello di colonna: Interessare solo i campi a rischio (nomi, email, numeri di carta) per preservare la fruibilità.
- Prediligi metodi format-preserving per analisi: Mantieni lunghezza, tipo e pattern referenziali per BI, join ed esportazioni.
- Maschera prima di esportare: Esporta copie mascherate su S3, cold storage o fornitori per ridurre la responsabilità.
- Documenta ogni job: Traccia sorgente/destinazione, tabelle coinvolte, metodi e pianificazioni—DataSunrise logga tutto per le revisioni.
- Revisioni politiche trimestrali: Aggiorna configurazioni man mano che schema e regolamenti evolvono.
Integra il mascheramento statico nei processi CI/CD in modo che ogni ambiente di build raccolga automaticamente dati sanificati. Questo elimina script fragili, applica logiche coerenti e mantiene gli ambienti di test allineati con la produzione—senza esporre contenuti sensibili.
Fatto correttamente, il mascheramento statico diventa un controllo integrato e ripetibile nel tuo SDLC—non un’attività occasionale.
Perché Usare il Mascheramento Statico con DataSunrise
- Proteggi campi sensibili come PII, dati finanziari e credenziali prima dell’uso esterno.
Il mascheramento statico trasforma in modo irreversibile i valori riservati, garantendo che dataset esportati o condivisi non possano rivelare informazioni reali dei clienti—anche se escono dal tuo ambiente sicuro. - Rispetta norme come GDPR, HIPAA e PCI DSS.
Anonimizzando elementi sensibili alla sorgente, le organizzazioni soddisfano requisiti regolatori su minimizzazione, condivisione sicura e protezione delle informazioni personali. - Condividi dati in sicurezza con appaltatori, analisti e terze parti.
I dataset mascherati facilitano la collaborazione senza esporre dati di produzione reali, riducendo rischi di abusi interni o divulgazioni accidentali. - Riduci il rischio supportando ambienti di test realistici.
Sviluppatori e team QA possono lavorare con dataset ad alta fedeltà, che mantengono valori statistici e logiche di business—senza il pericolo di trattare identità o dati finanziari reali. - Preserva l’integrità referenziale su schemi complessi.
Il mascheramento DataSunrise mantiene relazioni coerenti tra tabelle e campi, assicurando che applicazioni, analisi e pipeline di test funzionino correttamente dopo l’anonimizzazione.
Conclusione
Il Mascheramento Statico dei Dati (SDM) resta un elemento fondamentale dei framework moderni di sicurezza dati, offrendo un metodo affidabile ed efficiente per anonimizare informazioni sensibili preservando struttura, integrità e utilizzabilità dei dataset. Sostituendo valori confidenziali con equivalenti realistici ma non identificabili, le organizzazioni possono sfruttare in sicurezza dati simili a quelli di produzione per test, sviluppo, analisi e training di modelli AI senza rischiare l’esposizione di dati personali, finanziari o proprietari. Questo approccio garantisce non solo la conformità a normative globali quali GDPR, HIPAA, SOX e PCI DSS, ma mantiene un equilibrio ottimale tra privacy, funzionalità ed efficienza in pipeline DevOps e ecosistemi dati aziendali.
Oltre a soddisfare obblighi di conformità, il mascheramento statico svolge un ruolo cruciale in operazioni complesse come migrazioni cloud, collaborazioni con terze parti e scambi interdipartimentali di dati. Le sue capacità di gestione centralizzata e automazione garantiscono applicazione coerente di policy in ambienti ibridi e multi-cloud—riducendo errori umani e assicurando completa tracciabilità durante il ciclo di vita dei dati. Integrato con tecnologie complementari quali mascheramento dinamico, Database Activity Monitoring (DAM) e data discovery intelligente, lo SDM diventa un componente vitale di una strategia unificata di governance dei dati.
All’interno di piattaforme complete come DataSunrise, il mascheramento statico non solo previene l’esposizione non autorizzata dei dati, ma migliora la flessibilità operativa abilitando condivisione sicura, automazione dei test e innovazione su larga scala. Grazie a monitoraggio in tempo reale, applicazione automatizzata di conformità e visibilità centralizzata sugli audit, trasforma la privacy dei dati da un obbligo reattivo a una forza proattiva per la fiducia, la resilienza e la trasformazione digitale sostenibile.
